上下文腐烂 - 注意力有限

上下文腐烂 - 注意力有限

用户11705094
发布于 2026-07-02 09:44:39
发布于 2026-07-02 09:44:39

原因1:Attention资源有限
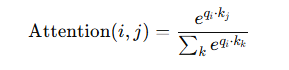
Transformer 的注意力本质是一个 softmax。
意思是每个位置 i,会对所有位置 j,计算一个相关性分数,然后归一化成概率分布。
这是一个竞争分配系统。
因为总权重 = 1,有人分得多,就有人分得少。

1. 为什么不是平均分配?
因为softmax 会放大差异。
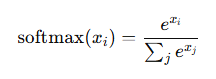
其中的指数函数,会把小差距变成大差距。
例如,线性差 1 倍,指数后变成 2.7 倍。
Attention 本质是:
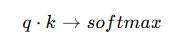
哪个 token 稍微内积大一点,更相关一点,被指数放大,再经过归一化。
结果少数 token 吃掉大部分注意力。

2. 前面为什么有优势?
因为,前面有结构性权重(system),即隐式偏置(bias)。
虽然注意力公式看起来没有任何偏置项,但其实偏置已经被编码进向量 query 和 key 里了。
这些向量不是中性的,是被训练出来的。
因为,在海量训练数据中,反复出现这种结构:
- 开头:指令 / 设定 / 规则
- 中间:背景 / 细节
- 结尾:当前问题
模型学到一个统计规律,开头的内容,决定怎么理解后面的内容。
这个规律就变成了隐式偏置(bias),就是结构性权重。

因为,这个 bias 并不是单独一项参数,而是藏在向量方向里的偏移。
没有一个参数叫 bias_front,但结果是行为上确实在偏向这些位置。
所以叫隐式。
数学上体现为 query 会更偏向匹配这些位置的 key。
因此分配的注意力也就更多。

3. 后面为什么有优势?
因为后面有时间性权重(recency)。
越靠近当前token的位置,在注意力里天然更容易被选中
这是模型训练后形成的距离偏置(distance bias)。
语言不是跳跃的,是连续演化的。
比如,“我今天去公司开会,然后...”
“然后”这个 token 的表示一定强依赖“开会”
所以,相邻 token 的向量是相似的,数学上就是向量方向接近。
因为 Transformer 在每一层都是有损压缩,而不是无损传输,所以语义漂移不可避免。
每经过一层 Transformer,本质是在做混合(attention)和变换(MLP)。
但是,离得近的 token,经过的变换路径短,语义还很纯。
离得远的 token,被很多层混合过,信息被别的内容污染。
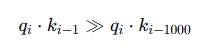
所以,越近,内积越大,因此权重越高。
你可以把它想成人的记忆。
刚听到的话, 还在脑子里,高权重。
很久之前的话,需要回忆,低权重。

4. 中间为什么没人管?
因为中间位置不像开头,没有结构信号。
也不像结尾,不新。
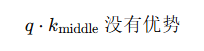
再经过 softmax 放大,注意力直接被两边挤压掉了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 magicyuan的AI随笔记 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号