初探 VexDB:DABStep 榜首背后,一款为 AI 而生的国产向量数据库

初探 VexDB:DABStep 榜首背后,一款为 AI 而生的国产向量数据库

胖头鱼的鱼缸
发布于 2026-07-02 14:36:36
发布于 2026-07-02 14:36:36

c1e2b050f885f08f4d01b61dbc9323df.jpg

在前面的文章,简单对VexDB进行了介绍,随着VexDB官网的正式开放,开发版免费下载的开放,我也第一时间登录官网进行了学习。
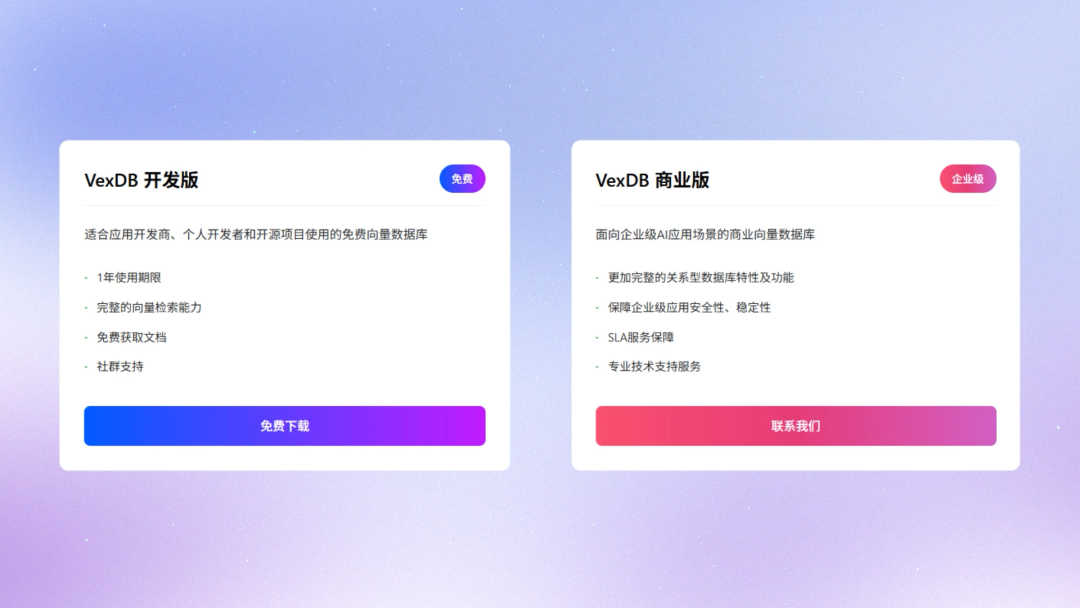
首先,在官方文档层面,在VexDB安装前操作系统准备阶段的操作是非常完善的,里面针对不同操作系统的依赖软件进行了详尽的分类;同时,每一项操作系统的配置操作都非常详细的解释了其配置原因和操作内容、步骤,这在国产数据库官方文档中算做的比较好的。也因为这个原因,在本文中就不对数据库的部署做出演示,同时由于硬件资源和测试场景的问题,我也只对VexDB的简单使用进行了验证,本文也不做演示。


作为一个非开源的数据库产品,我们无法在代码层面去探索VexDB的技术创新,同时再多的技术描述也不如权威测试数据有说服力 —— 而 VexDB 在 DABStep 基准测试中的表现,恰好给出了最直观的 “实力证明”。
我对 DABStep 不太熟悉,我也先查询了相关资料,了解到了这个基准测试的 “含金量”。DABStep 全称为 “Data Agent Benchmark for Multi-step Reasoning”,是由全球知名支付公司 Adyen 和 AI 领域巨头 Hugging Face 联合发布的基准测试工具,专门用于评估语言模型和 AI Agent 在多步骤推理中的能力,尤其聚焦数据分析场景。它之所以被行业认可,核心在于五个 “独特之处”:
https://huggingface.co/blog/dabstep DABStep介绍
DABStep的独特之处:
- 基于真实世界的用例:基于从 Adyen 实际工作负载中提取的 450 多个真实任务构建,这些任务并非合成的简单问题,而是反映了分析师每天面临的挑战,这是的 DABStep 有别于其他基准测试
- 结构化与非结构化数据的平衡:这些任务需要高级数据分析技能,来处理结构化数据和理解多个数据集及文档中的非结构化数据
- 简单设置:与其他需要复杂配置的基准测试不同,DABstep 易于使用,只需访问代码执行环境即可生成答案,参与者还可以直接提交答案到排行榜进行自动评估
- 事实性评估:任务设计为客观评估,输出结果总是映射为二元结果,无论对错,无需解释
- 多步骤复杂性:DABstep 测试系统在各种分析任务上的表现,从常规查询到多步骤的迭代工作流。与专注于孤立问题的基准不同,DABstep 挑战模型在各种实际任务中进行端到端的代理推理
也正因为这些优势,DABStep 的排行榜成为行业内衡量 AI 数据处理能力的 “权威榜单”。而 VexDB 在这份榜单中的表现,用 “惊艳” 来形容毫不为过。
https://huggingface.co/spaces/adyen/DABstep DABStep排行榜

从已认证的排行榜数据来看,参与测试的既有 Google Cloud AI Research、Hugging Face 这样的国际巨头,也有 Amity Solutions、Mphasis Limited 等行业解决方案提供商,使用的模型包括 Gemin-2.5-Pro、claude-3-5-sonnet、DeepSeek-V3 等当前主流的大模型。但清华大学提交的方案(Agent 为 AgenticData、模型为 Qwen3、向量数据库为 VexDB),在两个关键精度指标上都远超其他对手:Easy Level Accuracy(简单任务精度)达到 94.44%,比第二名 Google Cloud 的 87.5% 高出近 7 个百分点;Hard Level Accuracy(复杂任务精度)更是达到 50.79%,远超第二名的 45.24%。要知道,在基准测试中,1-2 个百分点的差距就已算显著优势,VexDB 能领先如此之多,足以证明其在向量检索效率、与 AI 模型适配性上的硬实力 —— 毕竟 AI Agent 每一步推理都需要从向量数据库中获取数据,数据库的检索速度和准确性,直接决定了 Agent 的推理效率和结果精度。
VexDB 汇聚了清华大学在数据库领域的多年积累,同时也结合了数智引航团队在真实场景中的实践经验。旨在真正释放大规模非结构化数据的价值,构建更高效、更紧密的“数据+大模型”协同方式。VexDB 通过向量化技术,把外部的知识高效地组织起来,精准地提供给大模型,从而显著降低幻觉、提高生成内容的准确性和可信度。同时,面对大规模的非结构化数据,VexDB 具备高效存储和极速检索高维向量的能力,从而打通从特征提取到智能推理的整个流程。它可以广泛应用在推荐系统、语义搜索、图像识别等场景中,真正让非结构化数据不再只是“存起来”,而是能够“用起来”。
再说说 VexDB 这个名字的含义,它拆分成三部分:Vector(向量)+ X(无限可能的多模态数据)+ Database(数据库)。这个命名其实暗含了它的野心 —— 不只是做一款 “存储向量的数据库”,而是要成为连接数据与 AI 的 “桥梁”,甚至是多模态数据智能管理的 “技术底座”。

在 AI 技术飞速发展的今天,向量数据库早已不是 “可有可无的辅助工具”,而是决定 AI 应用落地效果的 “关键基础设施”。VexDB 作为一款源自清华、聚焦 AI 的国产向量数据库,能在 DABStep 这样的权威测试中拿下第一,无疑给国产数据库赛道注入了新的活力。当然,基准测试的成绩只是 “起点”,未来它能否在实际落地中保持性能优势,能否持续迭代满足企业不断变化的需求,能否在激烈的市场竞争中站稳脚跟,还需要时间来验证。但至少现在,它已经用实力证明了国产向量数据库的技术潜力 —— 期待今天的云端发布会,看看这款 “为 AI 而生” 的数据库,究竟能给行业带来多少惊喜。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号