为什么所有请求都必须经过 API Server?

为什么所有请求都必须经过 API Server?

一根头发丝的宽度
发布于 2026-07-03 17:35:20
发布于 2026-07-03 17:35:20
🧭 你每天都在“间接控制 Kubernetes”
你每天都会执行这样一条命令:
kubectl apply -f deployment.yaml
但你有没有想过:
- 为什么 Pod 会被创建?
- 为什么 Scheduler 会自动工作?
- 为什么 kubelet 知道要拉镜像?
- 为什么没人直接操作 etcd?
如果把 Kubernetes 拆开来看,你会发现:
所有组件之间,从不直接通信。 它们只做一件事:围绕 API Server 工作。
🎯 一、kubectl apply 到底发生了什么?
有的人以为:
kubectl apply = 创建 Pod
但实际上,这只是一个“请求入口”。
真正的过程如下👇
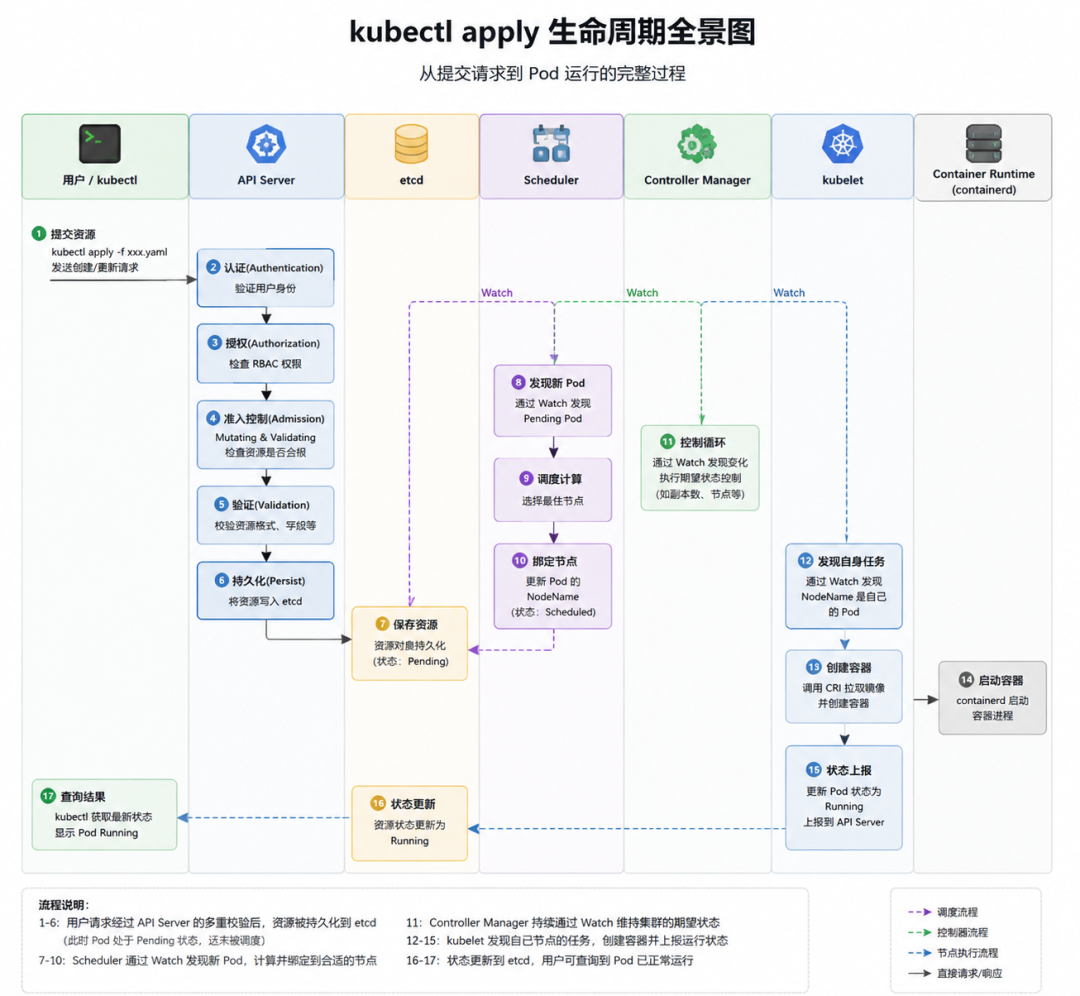
🔑 一句话记住:
kubectl 只负责把“期望状态”提交给 API Server。
🧭 二、完整生命周期:从命令到 Pod 运行
我们按图一步一步拆解:
1️⃣ 请求进入 API Server
kubectl 将 YAML 转换为 HTTP 请求: POST /api/v1/namespaces/default/pods
API Server 是唯一入口。
2️⃣ 安检流程开始(核心)
请求进入后,不是直接写入,而是经历“三道关卡”:
🔐 ① Authentication(你是谁?) 验证用户身份(证书 / Token / OIDC)
🛡 ② Authorization(你能干什么?) 检查 RBAC 权限
⚙ ③ Admission(你是否合规?) 分两类:
- Mutating:自动修改资源(默认值 / 注入 Sidecar)
- Validating:规则校验(资源限制 / 安全策略)
🔑 这三道关保证了只有合法的请求才能改动集群状态。
3️⃣ 写入 etcd(真正存储)
通过所有检查后: 👉 Pod 被写入 etcd
此时状态:Pending
⚠️ 注意: Pod 还没有运行,只是“被记录下来”了。
4️⃣ Scheduler 开始工作(通过 Watch)
Scheduler 并不会轮询 API Server。 它做的是:Watch Pod 变化
发现 Pending Pod 后:
- 计算最优节点
- 选择 Node
- 回写结果
❓ 猜一猜:Scheduler 是每秒问一次,还是“有事叫我”? 答案就是:事件驱动,不用轮询。
5️⃣ Controller Manager 介入
Controller 通过 Watch:
- 发现副本不足
- 创建新的 Pod 对象
- 保证期望状态
6️⃣ kubelet 执行真正的“干活”
每个 Node 上的 kubelet,同样通过 Watch:
- 发现分配给自己的 Pod
- 调用 containerd / CRI
- 拉镜像
- 创建容器
7️⃣ Pod 运行成功
容器启动后,kubelet 上报状态:Running 并同步回 API Server。
🔥 三、看懂完整链路的关键路径
回到上面那张生命周期全景图,整个流程可以拆成两大阶段:
1️⃣ 写入阶段(上半段)
kubectl → API Server → 认证/鉴权/准入 → etcd
👉 这个阶段只是把“期望状态”安全地存进数据库,Pod 还没真正运行。
2️⃣ 事件分发阶段(下半段)
etcd 里的变化通过 Watch 机制,同时推送给三个角色:
- Scheduler:负责找合适的节点
- Controller Manager:确保副本数符合期望
- kubelet:真正拉镜像、启动容器
👉 最后容器运行时创建完成,Pod 状态回到 API Server,变成 Running。
🔑 API Server 不干活,它只负责收消息、存状态、发通知。 真正干活的是 Scheduler 和 kubelet。
🧠 四、为什么必须经过 API Server?
这是 Kubernetes 最核心的设计:
1️⃣ 统一入口
所有请求必须经过 API Server → 避免系统混乱
2️⃣ 数据一致性
只有 API Server 可以写 etcd → 防止数据冲突
3️⃣ 权限控制
所有操作必须认证授权 → RBAC 体系完整
4️⃣ Watch 机制
组件不是轮询,而是事件驱动 → 性能极高
🔑 API Server 就是集群的“总控开关”和“交通指挥”。
⚙️ 五、如果没有 API Server,会发生什么?
如果组件直接访问 etcd:
- ❌ 数据无法校验
- ❌ 权限体系失效
- ❌ 状态容易冲突
- ❌ 控制面彻底混乱
Kubernetes 会变成一个“分布式野数据库”。
🧭 六、一句话总结
API Server 本身不执行任何调度或容器创建,它的作用是:
👉 让整个 Kubernetes 集群保持一致性与可控性。
📚 想更系统地搞懂 API Server?
在 1HairLabs 的完整版文章里,我画了更详细的架构图,还整理了:
- API Server 高可用部署方案
- Watch Cache 实现机制
- Admission Controller 生产实践
- 一键排查故障的命令速查表
👉 点击 [阅读原文]
🚀 写在最后
Kubernetes 的设计本质不是“自动化”,而是: 通过 API Server 实现统一状态管理的分布式系统。
理解这一点,你才算真正理解 Kubernetes。
🚀 写在最后
Kubernetes 的设计本质不是“自动化”,而是: 通过 API Server 实现统一状态管理的分布式系统。
理解这一点,才算真正理解 Kubernetes。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号