Karpathy 的 LLM Wiki 搭建实战:三层架构 + 三大操作,Obsidian + AGENTS.md 让知识库自我维护
原创
Karpathy 的 LLM Wiki 搭建实战:三层架构 + 三大操作,Obsidian + AGENTS.md 让知识库自我维护
原创
术哥
发布于 2026-07-04 10:43:32
发布于 2026-07-04 10:43:32
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 156 篇,AI 星探「2026」系列第 19 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
Karpathy LLM Wiki 方法论信息图封面:核心分工、三层架构与三大操作概览
你可能有过这样的体验:往 NotebookLM 或 ChatGPT 里上传了一堆 PDF 和文章,问完问题,关掉窗口,什么都没留下。下次再问,又得从头喂资料。
你读过的东西,AI 替你总结过的东西,全部蒸发。
问题的根源只有一个:这些工具不累积。它们每次都从零开始重新检索、重新拼凑、重新遗忘。
Andrej Karpathy 前段时间在一个 gist 里提出了另一种做法——让 LLM 不只是回答你的问题,而是持续维护一个属于你的、会越长越厚的知识库。他把这套模式叫做 LLM Wiki。
这篇教程就带你用 Obsidian 把它落地。
整套方法的核心分工,Karpathy 说得很直白:
You never (or rarely) write the wiki yourself — the LLM writes and maintains all of it. You're in charge of sourcing, exploration, and asking the right questions. The LLM does all the grunt work — the summarizing, cross-referencing, filing, and bookkeeping.
一句话:你几乎不用自己写 wiki,只负责找资料和提问;LLM 负责所有记账的脏活累活。
说明:本文基于 Andrej Karpathy 的 LLM Wiki 方法论 gist 和笔者搭建的可运行 Obsidian 模板整理而成。文中目录结构、frontmatter 字段、建页规则均为模板实际实现,但 LLM 维护效果会因工具版本、模型能力、资料类型不同而有差异,请以你的实际环境测试结果为准。如果有实操经验或疑问,欢迎在评论区分享交流。
先搞清楚:为什么 RAG 的知识不累积
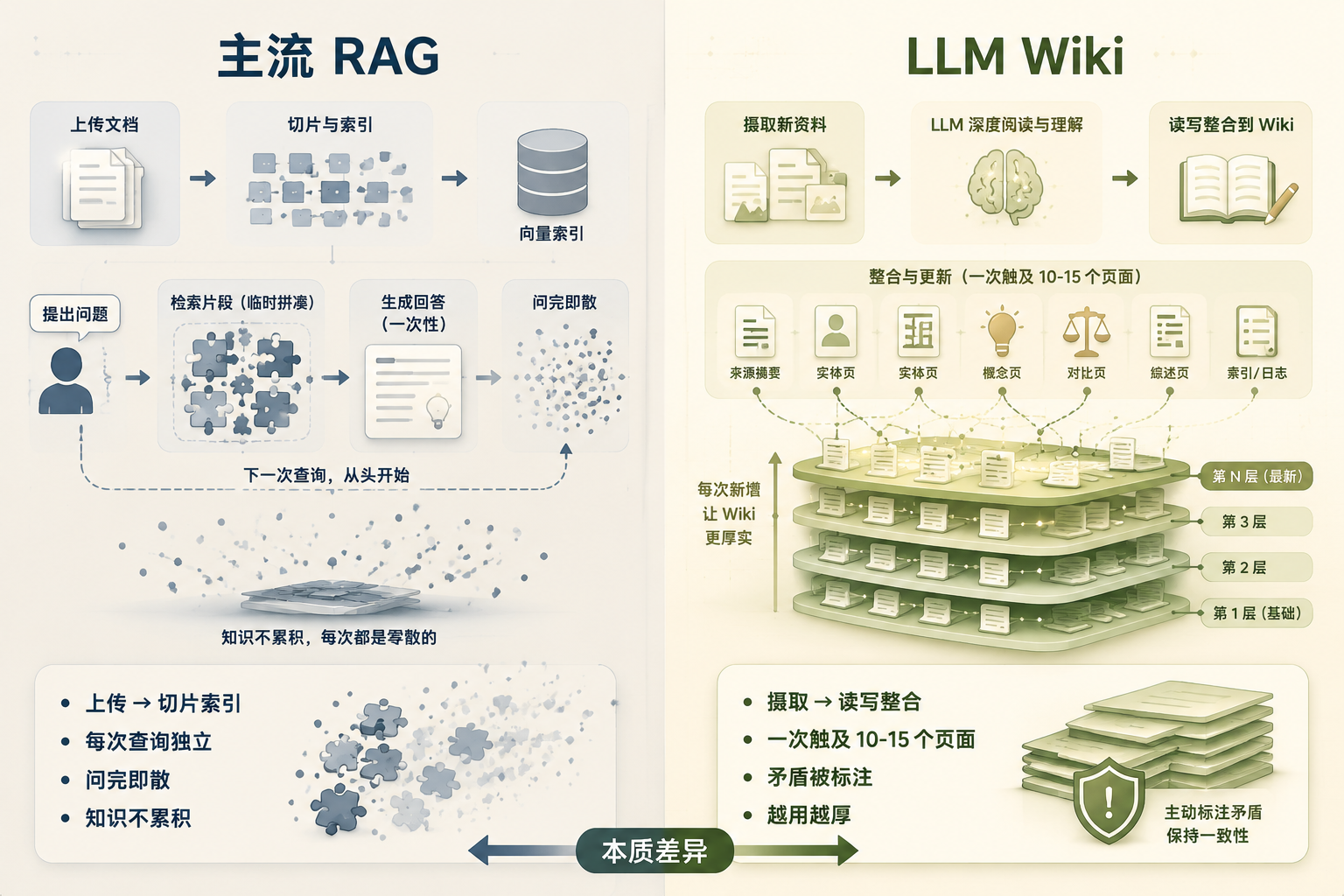
RAG 与 LLM Wiki 累积机制对比:左边问完即散,右边层层累积变厚
图 1:RAG 每次从零检索、问完即散;LLM Wiki 摄取一次整合 10-15 个页面,知识持续累积变厚
先把痛点说透,你才知道这个方法到底解决了什么。
主流的 RAG 系统(NotebookLM、ChatGPT 文件上传、大多数自建 RAG)的工作方式是这样的:你上传一批文件,系统把它们切块、做向量索引。
你提问的时候,系统检索出最相关的几个片段,喂给 LLM,LLM 基于这些片段生成回答。
听起来合理。但问题在于:每次查询都是独立的一次性事件。你问一个需要综合五篇文章的微妙问题,LLM 每次都要重新拼凑那些片段。
它没有把上一次的发现记下来,也没有把矛盾标注出来。没有任何东西被建立起来。
Karpathy 的 LLM Wiki 模式不一样。加入新资料时,LLM 做的事情远不止「为以后检索做索引」——它读完整篇、提取关键信息、整合进现有的 wiki、更新实体页、修订综述摘要、把新旧数据的矛盾标出来。一次摄取,常常同时触碰 10 到 15 个 wiki 页面。
结果就是一个 Karpathy 反复强调的词——持久的、复利的产物(persistent, compounding artifact):
- 交叉引用已经建好了
- 矛盾已经被标注了
- 综述反映了你读过的所有内容
- 每加一篇资料、每问一个问题,wiki 都在变厚
两者的区别,一句话概括:
维度 | 主流 RAG | LLM Wiki |
|---|---|---|
知识累积 | 不累积,每次从零检索 | 持续累积,越用越厚 |
产物形态 | 检索索引(你看不到) | 你能读、能编辑的 markdown 文件 |
矛盾处理 | 不会发现矛盾 | 主动标注矛盾 |
维护成本 | 取决于你重新上传的频率 | 趋近于零(LLM 全权记账) |
为什么维护成本能趋近于零
这里有个关键洞察,也是整套方法能成立的根基。
Karpathy 的原话:
The tedious part of maintaining a knowledge base is not the reading or the thinking — it's the bookkeeping.
维护一个知识库,累人的地方不是读、不是想。是记账:更新交叉引用、保持摘要不过时、标注新数据推翻了哪个旧声明、跨几十个页面维持一致性。
这正是人类放弃维护 wiki 的原因——维护成本增长比价值增长快。
你可能花一个周末搭了个精美的 Obsidian 库,一个月后再打开,已经记不清哪个页面说的是什么阶段的结论了。
LLM 把这件事接过去了。它不会无聊,不会忘记更新交叉引用,可以一次性碰触十几个文件还保持一致。wiki 之所以能持续被维护,靠的不是人变勤快,而是记账的活儿被外部化给了 LLM,对用户来说趋近于零。
Karpathy 还把这个想法关联到了 Vannevar Bush 1945 年的 Memex 设想——一个私人的、主动策划的知识存储,文档之间有联想式的连接。Bush 想到了这个愿景,但留下一个没解决的问题:谁来做维护? LLM 把这一步补上了。
理解了这个核心逻辑,接下来就是怎么落地。
三层架构:Schema、原始资料、Wiki
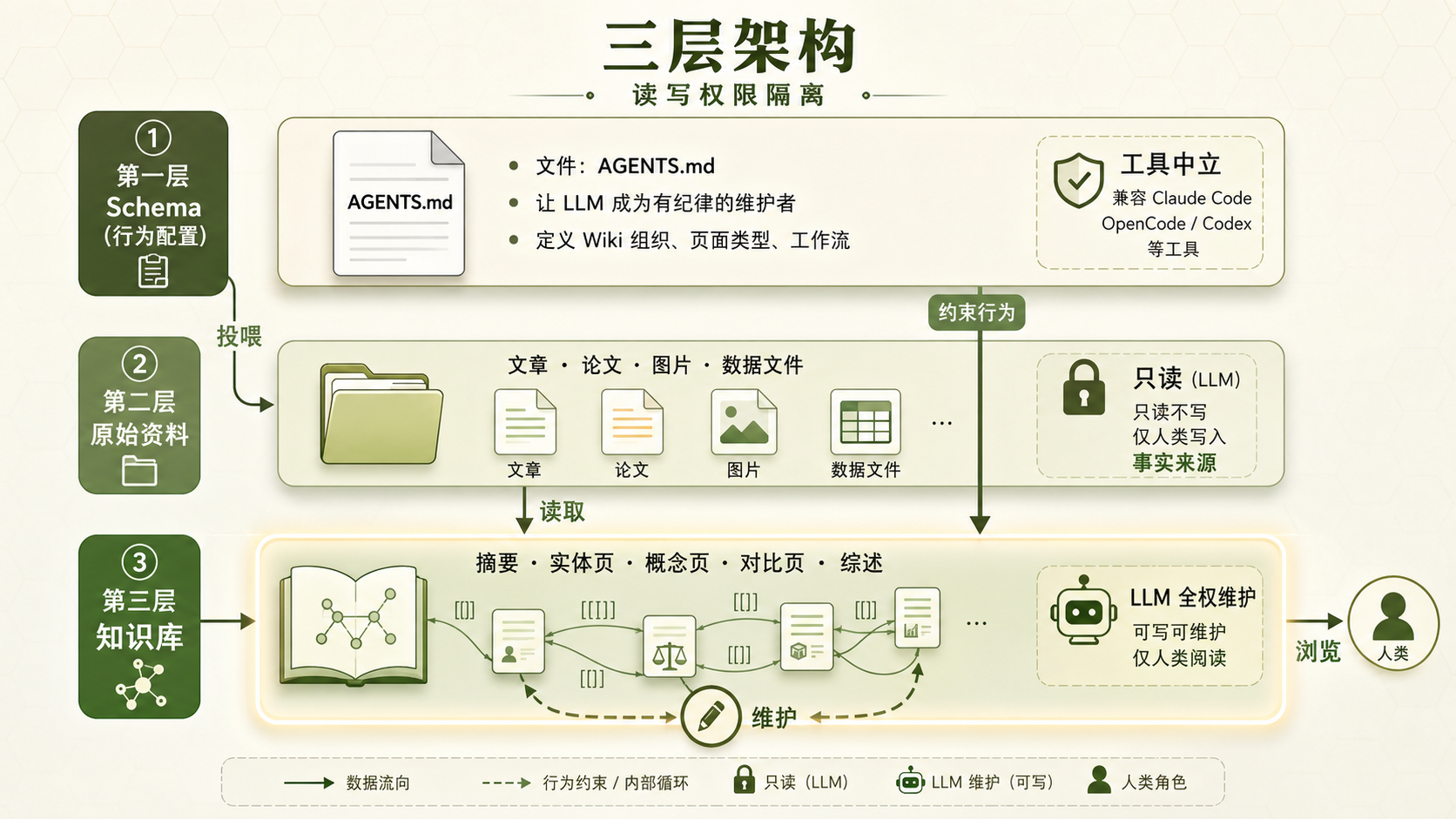
LLM Wiki 三层架构图:Schema 配置层、原始资料只读层、知识库 LLM 维护层
图 2:三层架构与读写权限隔离——Schema 配置行为、Raw 原始资料只读、Wiki 知识库由 LLM 全权维护
Karpathy 定义了三层结构,这也是整个系统的骨架。
第一层:Schema(行为配置)
这是告诉 LLM「该怎么干活」的配置文件。它定义 wiki 如何组织、页面类型有哪些、工作流是什么。它是让 LLM 成为「有纪律的维护者」而非「通用聊天机器人」的关键。
这一层有个命名问题必须说清楚。
Karpathy 原文用的是 CLAUDE.md,他明确写了「a document e.g. CLAUDE.md for Claude Code or AGENTS.md for Codex」。也就是说,这个命名是面向特定工具 Claude Code 的。
但这里有个问题:喂给 LLM 的工具不止 Claude Code 一个。OpenCode、Codex、Cursor,任何能读写文件的 LLM Agent 都能用这套模式。
如果你把配置文件命名为 CLAUDE.md,换一个工具就未必能被识别,Schema 也没法跨工具复用。
所以本文的建议是:统一用 AGENTS.md 这个通用命名。原因很简单:
AGENTS.md是跨工具的通用约定,Claude Code、OpenCode、Codex 都能识别- 你不会因为换了个 LLM 工具就得重命名配置文件
- Schema 作为「这套方法论的合约」,不应该绑定某个特定产品
这个差异看起来是小事,但如果你打算长期用这套方法,工具中立能省掉很多麻烦。
第二层:Raw sources(原始资料)
原始资料层。文章、论文、图片、数据文件。只有你自己可以往里写东西,LLM 读取时视为只读。 这是事实来源(source of truth)。
第三层:The wiki(知识库)
LLM 全权维护的部分。摘要、实体页、概念页、对比页、综述。你只读,不写。 你要做的就是浏览它、点链接、看图谱。
一个完整的目录结构长这样:
my-wiki/ ← Obsidian 直接打开这个文件夹
├── .obsidian/ ← vault 配置
├── AGENTS.md ← Schema 配置(LLM 的行为说明书)
├── README.md ← 项目说明(给人看)
│
├── raw/ ← 原始资料层(只读)
│ └── 素材/
│ ├── 文章/ ← URL 抓取 / Web Clipper / 手动存入
│ │ └── 2026/06/ ← 按年月组织
│ ├── 图片/ ← 单独下载的参考图片
│ └── 附件/ ← 拖拽进来的任意附件
│
└── wiki/ ← 知识库层(LLM 全权维护)
├── index.md ← 内容索引(每次操作后更新)
├── log.md ← 操作日志(仅追加)
├── 来源/ ← 来源摘要页
├── 实体/ ← 实体页:人/公司/产品/工具
├── 概念/ ← 概念页:原理/方法/术语
└── 对比/ ← 对比分析页:跨来源综合这个结构的核心设计思路是读写权限隔离。raw 层只你能写,保证事实来源不被 LLM 篡改;wiki 层只 LLM 写,保证你不会手动改坏 LLM 维护的一致性。各司其职。
三个核心操作:Ingest、Query、Lint
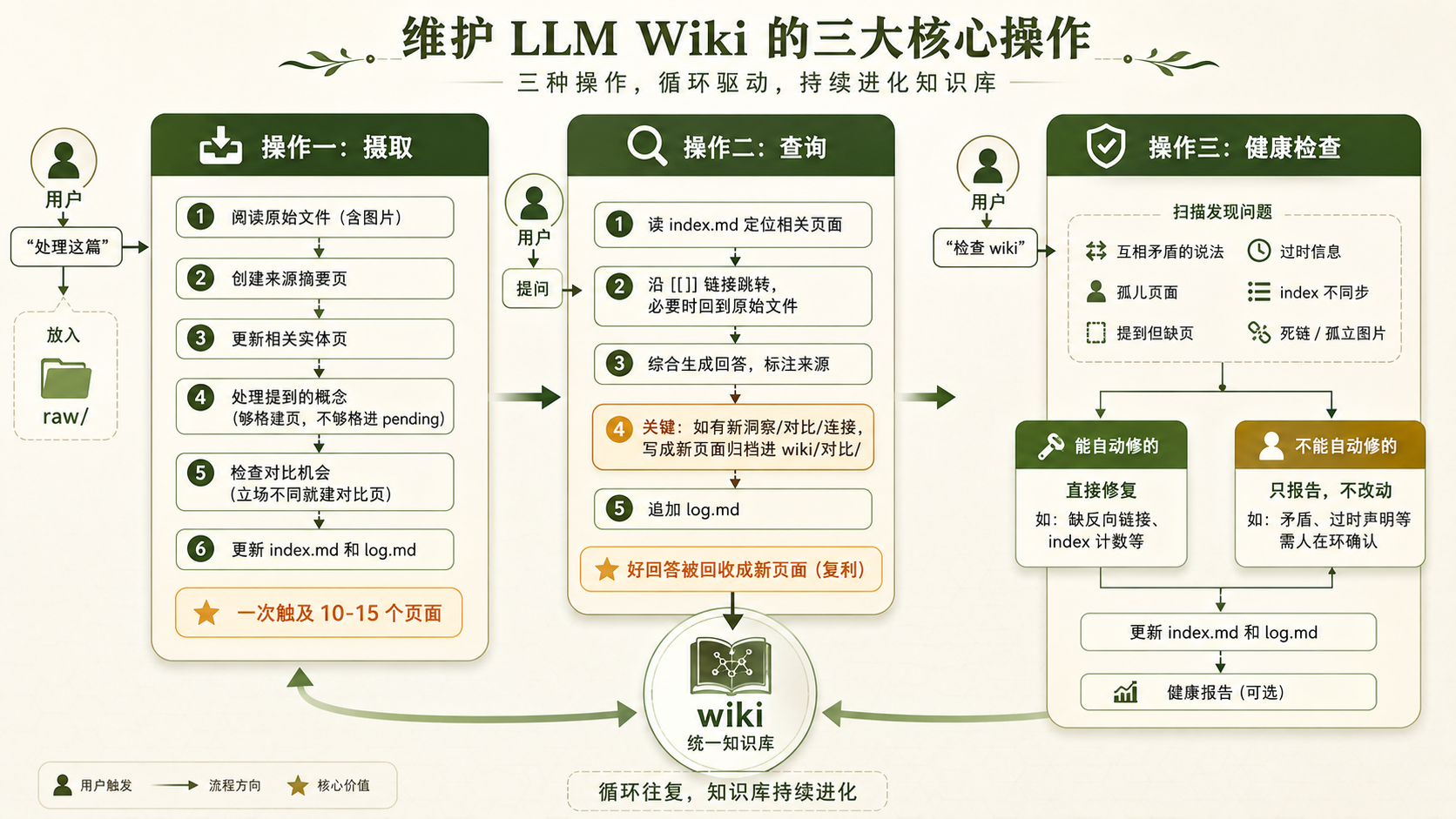
三大核心操作流程图:摄取整合资料、查询沉淀洞察、健康检查维护一致性
图 3:三大核心操作——摄取每次触及 10-15 个页面,查询会把好回答沉淀为新页面(复利来源),健康检查区分自动修复与人在环
架构搭好了,接下来是你日常会反复做的三件事。
操作一:Ingest(摄取)
你把新资料放进 raw/,然后对 LLM 说一句「处理这篇」。接下来全是 LLM 的事:
- 阅读原始文件(包括图片)
- 创建一篇
wiki/来源/{标题}.md摘要页 - 更新相关的实体页
- 处理提到的概念(够格就建页,不够格进 pending)
- 检查有没有对比机会(新资料和已有来源立场不同就建对比页)
- 更新 index.md 和 log.md
Karpathy 的实操偏好是一次摄取一篇,保持参与。别一口气扔十篇让它批量处理——你会失去对内容走向的掌控。
读一读它生成的摘要,检查它更新了哪些页面,引导它该强调什么。一次摄取触及 10 到 15 个 wiki 页面是正常的,这说明资料被充分消化了,不是孤立地躺在那里。
操作二:Query(查询)
你有问题要问的时候,LLM 的工作流程是:
- 先读 index.md 定位相关页面
- 深入阅读相关页面,沿着
[[]]链接跳转,必要时回到 raw 原始文件 - 综合生成回答,标注来源页面
- 关键一步:如果这次回答产生了新的综合洞察、对比分析或意外连接,把它写成一篇新页面归档进
wiki/对比/ - 追加 log.md
第 4 步是整个 Query 操作的亮点,也是 LLM Wiki 区别于普通问答的地方。Karpathy 的原话:
Good answers can be filed back into the wiki as new pages. A comparison you asked for, an analysis, a connection you discovered — these are valuable and shouldn't disappear into chat history.
普通问答里,你问出一个好问题、得到一个精彩回答,关掉窗口就没了,下一次还得重新问。
而在 LLM Wiki 里,好的回答会被回收成 wiki 的新页面,成为下次提问的起点——「复利」就是这么来的。
操作三:Lint(健康检查)
你跟 LLM 说「检查 wiki」或「lint」,它会扫一遍整个库,报告这些问题:
- 互相矛盾的说法:不同页面对同一事实描述不一致
- 孤儿页面:没有任何反向链接的页面
- 提到但缺页:有
[[]]链接但目标页不存在 - 过时信息:被新资料推翻但还没更新的内容
- index.md 与实际文件不同步
- 值得新建的对比页:多个来源讨论同一主题但角度不同
- 死链:来源页的 URL 已经失效
- 孤立图片:raw 里的图片没有被任何 wiki 页引用
Lint 分两类处理。能自动修的(缺反向链接、index 计数对不上),LLM 直接修。
不能自动修的(矛盾、过时声明),只报告,不擅自改——因为这类判断需要你这个人在环里确认。
落地实操:四种页面和建页规则
架构和操作清楚了,接下来要看 wiki 里到底放什么页面、什么时候建。
Frontmatter:每个页面都有的元信息
所有 wiki 页面顶部都有 frontmatter,长这样:
---
type: 来源 # 页面类型:来源 | 实体 | 概念 | 对比
tags: [AI, 知识管理] # 标签
sources: [] # 关联的来源页(实体/概念/对比页必填,来源页不填)
created: 2026-07-02 # 创建日期
updated: 2026-07-02 # 更新日期
---几个字段说明:
type标明页面类型,Dataview 插件靠它做动态表格sources是 wiki-link 列表,标注这个页面的依据来自哪些原始资料。来源页自己不需要这个字段,其他三类必填created和updated是日期戳,方便 Lint 判断信息新鲜度
四种页面类型
类型 | 目录 | 建页规则 | 设计原理 |
|---|---|---|---|
来源 |
| 每篇资料都建 | 每篇原始资料对应一个摘要页 |
实体 |
| 首次被专段讨论就建 | 实体是具体的对象(人/公司/产品),单篇已能充分刻画 |
概念 |
| 被 2 篇以上来源提到才建 | 概念容易过度抽象,先放进 pending 观察 |
对比 |
| 2 篇以上来源有不同立场时建 | 或在 Query 时归档有价值分析 |
这套建页规则背后有个自下而上的原则:不要急着抽象。
实体页(比如 Karpathy、Obsidian、Claude Code 这种)单篇资料就能刻画清楚,首次出现专段讨论就可以建。跨来源的认知演进,通过实体页里的「认知演进」段落追加记录。孤儿页交给 Lint 清理。
概念页(比如「向量检索」「上下文窗口」)更抽象,容易过度泛化产生低质量页面。
所以规则是第一次出现先不建,记进 index.md 的 pending 列表,等第二篇来源也提到它,确认这个概念确实反复出现,才正式建页。
对比页有两种来源:一是你摄取资料时 LLM 发现不同来源立场对立,主动建;二是你 Query 时 LLM 产出了有价值的横向分析,归档成新页。
交叉引用怎么写
Obsidian 兼容的写法,注意别包反引号:
- 引用实体页:[[实体/Karpathy]]
- 引用概念页:[[概念/LLM Wiki]]
- 引用原始资料:[[raw/素材/文章/2026/06/xxx.md]]
- 引用图片:![[raw/素材/图片/xxx.png]]有个重要取舍:图片不复制到 wiki,直接引用 raw 里的路径。这样原始资料和 wiki 各司其职,避免同一张图存两份导致不同步。
index.md 和 log.md:两个枢纽文件
index.md:内容导向
index.md 是 wiki 的首页,也是 LLM 回答任何问题前的第一个动作——读它来定位相关页面。
Karpathy 在原文里提到,在中等规模(大约 100 篇来源、几百个页面)下,一个 index 文件已经够用,不需要引入 embedding-based 的 RAG 基础设施。
Karpathy 给出的做法是用 Dataview 插件生成动态表格,基于 frontmatter 的 type、tags、created 字段自动汇总。这样表格永远跟着实际文件走,不会出现手写表格和文件对不上的情况。
log.md:时间导向
log.md 是一个只追加的时间线,记录每次操作。固定格式:
## [2026-07-02] ingest | 摄取了 Karpathy 的 LLM Wiki gist
## [2026-07-02] query | 对比了 RAG 和 LLM Wiki 的累积机制
## [2026-07-03] lint | 发现 3 个孤儿页面,已清理 2 个想看最近做了什么,一行命令:
grep "^## \[" log.md | tail -10log.md 的作用是给 LLM 一个「最近发生了什么」的时间线,帮它理解当前 wiki 的状态。
Obsidian 在这套模式里扮演什么角色
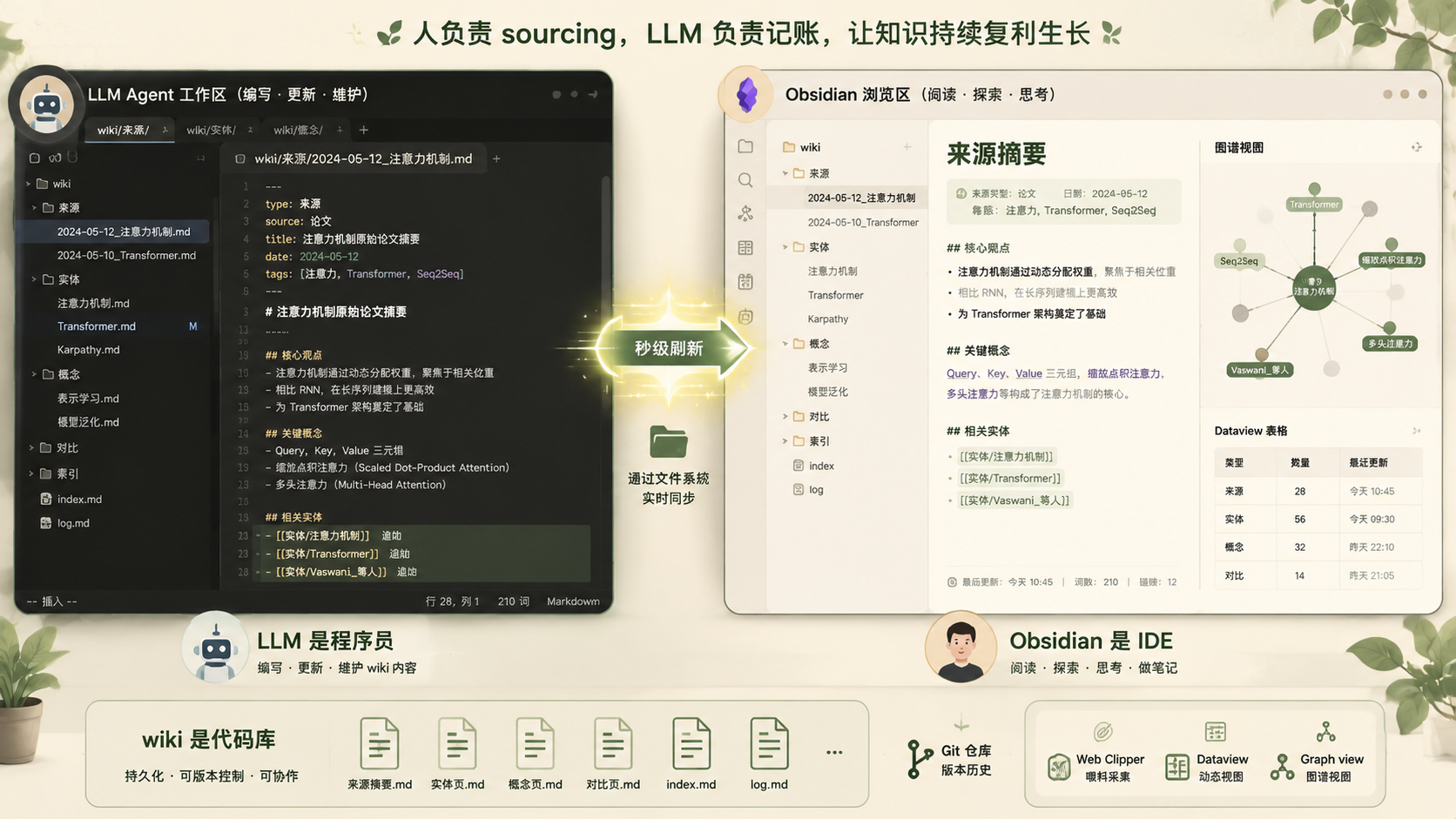
Obsidian 与 LLM 协作画面:左侧 LLM 编辑代码窗口,右侧 Obsidian 实时显示 wiki 页面与图谱
图 4:Obsidian 是 IDE、LLM 是程序员、wiki 是代码库——LLM 在一侧编辑,Obsidian 实时刷新页面与图谱
Karpathy 有一句概括整个协作画面的金句:
Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase.
实操画面是:LLM agent 开在一边,Obsidian 开在另一边。LLM 基于对话做编辑,你在 Obsidian 里实时看结果——点链接、看图谱、读更新的页面。LLM 改文件,Obsidian 秒级刷新。
Obsidian 在这套模式里主要用上这几个功能:
Web Clipper(浏览器扩展):把网页文章一键转成 markdown 存进 raw/,是快速喂数料的利器。
图片下载到本地:在 Settings → Files and links 里把 Attachment folder path 设成固定目录(比如 raw/assets/),然后在 Hotkeys 里搜「Download」,找到「Download attachments for current file」,绑个快捷键。
剪藏文章后按一下,所有图片自动下载到本地。为什么重要:让 LLM 直接看本地图片,而不是依赖会失效的 URL。
Graph view(图谱视图):看 wiki 形态最直观的方式。什么连到什么、哪些页面是 hub、哪些是孤儿,一目了然。
Dataview 插件:基于 frontmatter 跑查询,自动生成动态表格和列表。LLM 加 YAML frontmatter,Dataview 负责展示。
还有一点值得强调:wiki 就是一个 git 仓库。你免费拿到版本历史、分支、协作能力。Karpathy 原文:
The wiki is just a git repo of markdown files. You get version history, branching, and collaboration for free.
刻意不做的事:几个设计取舍
这套方法有几个明确的「不做」,理解它们比理解「做什么」更能看清设计思路:
- 不复制图片到 wiki:直接引用 raw 里的路径,避免双份存储
- 不复制原文到 wiki:原始文件在 raw,wiki 只存提炼后的知识
- 不引入向量搜索:量级在 100 篇以内,index.md 加 Dataview 完全够用
- 不建 tags 目录:用 frontmatter 的 tags 字段加 index.md 分类就够
这些取舍背后是同一个判断:中等规模下,简单结构比复杂基础设施更扛得住。等你真的攒到几百篇来源、感觉 index 不够用了,再引入正经的搜索工具(比如 Karpathy 提到的 qmd,一个本地 markdown 搜索引擎)也不迟。
这套方法适合什么场景
Karpathy 在原文里列举了几个典型场景:
- 个人:跟踪目标、健康、自我提升,归档日志、文章、播客笔记
- 研究:用几周或几个月深入一个主题,读论文和报告,增量搭建一个带演进观点的综述 wiki
- 读书:每读完一章摄取一次,给人物、主题、情节线索建页,看它们怎么连接。读完整本书,就有一个丰富的伴生 wiki
- 团队:LLM 维护的内部 wiki,喂 Slack 讨论、会议记录、项目文档,可能需要有人在环审核更新
说到底,任何「随时间累积知识、希望组织化而非散乱」的场景,都适用。
动手搭一个:把 Gist 丢给 LLM
说到这里,原理够了,该动手了。
回想一下前面讲的核心理念——人做 sourcing,LLM 做记账。那么搭 wiki 这件"记账活儿"本身,理所当然也应该交给 LLM。你不需要手写目录、手写规则文件、手敲 frontmatter 模板。你只需要做两件事:建一个空 vault,然后把 Karpathy 的 Gist 丢给你的 LLM Agent。
准备清单很短:
- Obsidian:免费下载,官网 https://obsidian.md
- 一个 LLM Agent 工具:Claude Code、OpenCode、Codex、Cursor,任何能读写文件的都行
- Karpathy 的 Gist 链接:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
两步走。
第一步:新建一个 Obsidian Vault
打开 Obsidian,点「Create new vault」,选一个空文件夹,命名为你的项目名(比如 my-wiki)。这一步只是建一个空盒子。
第二步:把 Karpathy 的 Gist 喂给你的 LLM Agent
打开终端,cd 到你刚才建的 vault:
cd /你的路径/my-wiki
claude # 或 opencode、codex,看你用哪个工具然后把 Karpathy 的 Gist 链接丢给它,配一句指令:
读一下这篇 Gist:https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f 按它定义的 LLM Wiki 方法论,帮我初始化整个 wiki 的结构。 规则文件用
AGENTS.md命名(不要用CLAUDE.md,我希望它跨工具通用)。
LLM 会替你做完全部脏活:
- ✅ 读懂 Gist 里的三层架构、三大操作、建页规则
- ✅ 创建完整的目录结构(
raw/、wiki/来源/、wiki/实体/、wiki/概念/、wiki/对比/) - ✅ 生成
AGENTS.md(规则文件,告诉它自己以后怎么干活) - ✅ 生成
index.md(索引骨架,配好 Dataview 查询模板)和log.md(空日志)
最终生成的结构长这样(目录命名你可以让 LLM 按你的偏好调整):
my-wiki/
├── raw/ ← 原始资料层(你喂数据的地方)
│ ├── articles/ ← 抓取的文章
│ ├── images/ ← 图片
│ └── attachments/ ← 其他附件
│
├── wiki/ ← 知识库层(LLM 全权维护)
│ ├── sources/ ← 来源摘要页
│ ├── entities/ ← 实体页
│ ├── concepts/ ← 概念页
│ ├── comparisons/ ← 对比页
│ ├── index.md ← 索引(Dataview 动态生成)
│ └── log.md ← 操作日志
│
└── AGENTS.md ← 规则文件(最关键)其中 AGENTS.md 是整套系统的钥匙——它就是 Karpathy 说的 Schema,定义了所有规则:怎么读原始素材、什么时候建实体页、什么时候建概念页、交叉引用怎么写、命名约定是什么、index 和 log 怎么更新。
这个文件你不需要自己写,LLM 已经帮你写好了。它后面会严格遵守里面的规则。
第三步(可选):装两个 Obsidian 插件
- Dataview(社区插件):让 index.md 里的动态表格能渲染出来。在设置里关闭安全模式后从社区插件市场装
- Web Clipper(Obsidian 官方出的浏览器扩展):用来快速剪藏网页文章进
raw/
装完之后,整个环境就绪。你的活儿到此为止,剩下的都是 LLM 的事。
开始喂数据
找一篇你最近读过的文章,用 Web Clipper 剪进 raw/articles/,然后对你的 LLM Agent 说:
处理一下 raw/articles/ 里我刚存的那篇文章。
从这一刻开始,你的 wiki 就开始生长了。它会建来源摘要页、提取实体、标出值得追踪的概念、更新 index 和 log——一次摄取触碰十几个页面,全是它自己干。
写在最后
回到那个核心分工:人做 sourcing,LLM 做记账。
Vannevar Bush 在 1945 年就想到了个人知识库的愿景,但他没法解决的问题是「谁来维护」。
Karpathy 把这件事看透了——维护知识库累人的地方不在读、不在想,在记账。而记账这件事,恰好是 LLM 擅长又不会厌倦的活儿。
这套方法不是说你要从此告别 RAG。RAG 在「快速查询一批陌生文档」时依然好用。
但如果你面对的是一个会随时间累积、需要持续整合和交叉引用的知识领域,LLM Wiki 是一个更对路的模式。
Karpathy 在 gist 末尾留了一句元说明,我觉得很适合作为这篇教程的结尾:
This document is intentionally abstract. It describes the idea, not a specific implementation.
方法论是抽象的,只传达模式。具体的目录结构、Schema 内容、页面格式、用哪个 LLM 工具——都由你的领域和偏好决定。把这份方法论交给你的 LLM agent,和它一起搭出一个适合你的版本。 剩下的,LLM 能搞定。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号