用 Amazon CDK 构建现代化云架构:Python 编写部署脚本替代 YAML

用 Amazon CDK 构建现代化云架构:Python 编写部署脚本替代 YAML

掘金安东尼
发布于 2026-07-05 09:22:18
发布于 2026-07-05 09:22:18
在我所在的团队里,我们一度用 RDS + 复杂脚本生成报表,靠人工维持“日更数据” —— 但每加一个字段、每多一个报表,技术债就成倍增长。我们不是不懂 ETL,而是被旧有的数据处理方式“耦合死了”。
直到我们尝试 构建一个基于 S3 + Glue + Athena 的数据湖,用来承接来自日志系统、CRM、IoT 设备、财务系统的多源数据。最终它不仅解决了扩展性问题,更重要的是,它让业务分析从“求报表”变成了“自助分析”。
这篇文章,我不讲理论,只讲我们如何一步步落地 Glue + Athena,从混乱的数据孤岛,变成标准化、高弹性的“企业分析中台”。
📐 数据湖 vs 数据仓库:别再死磕“结构化数据”了
传统数据仓库(如 Redshift、Snowflake)强调 Schema 优先、结构明确。而数据湖(Data Lake)的核心在于:
- 存数据先放到湖里(S3),后定义结构(Schema-on-read)
- 支持 JSON、CSV、Parquet、甚至日志和二进制
- 配合 Glue 可以自动爬数据结构
- 用 Athena + SQL 查询,无需开数据库实例
这种解耦式架构,才是真正适合多源数据接入+轻分析诉求的现代 BI 架构。
🏗 我们的数据湖架构图
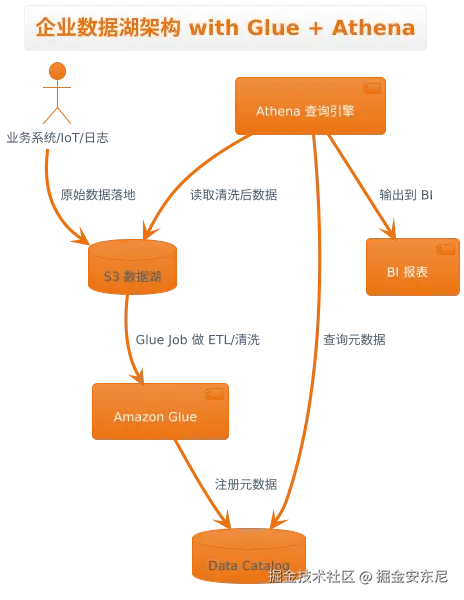
@startuml
title 企业数据湖架构 with Glue + Athena
actor SourceSystem as "业务系统/IoT/日志"
database S3 as "S3 数据湖"
component Glue as "Amazon Glue"
database GlueCatalog as "Data Catalog"
component Athena as "Athena 查询引擎"
component QuickSight as "BI 报表"
SourceSystem --> S3 : 原始数据落地
S3 --> Glue : Glue Job 做 ETL/清洗
Glue --> GlueCatalog : 注册元数据
Athena --> GlueCatalog : 查询元数据
Athena --> S3 : 读取清洗后数据
Athena --> QuickSight : 输出到 BI
@enduml💻 实战:用 Glue + Athena 跑通一次企业级分析流程
Step 1:数据落地到 S3(Bronze Layer)
我们把 CRM 导出的客户 CSV、Kafka 落盘的行为日志、IoT 设备上报的 JSON 全部写入不同的 S3 前缀目录:
s3://company-data-lake/
├── crm/customers/2025-07-15.csv
├── events/logs/2025/07/15/*.json
└── devices/metrics/2025/07/*.json注意:这里我们并不强依赖结构,只要能被 Glue 识别即可。
Step 2:用 Glue Crawler 自动识别 Schema
在 Amazon Glue 创建一个爬虫(Crawler):
数据源:S3://company-data-lake/crm/customers/
格式:CSV(自动识别)
输出:Glue Data Catalog -> 表名为 crm_customers这个过程不需要写代码,Glue 会在 Catalog 中生成一张可 SQL 查询的“虚拟表”。
Step 3:用 Glue Job 清洗数据(Silver Layer)
下面我们编写一个 Glue Job,用 Python(Spark)清洗原始日志数据:
import sys
from Amazonglue.context import GlueContext
from Amazonglue.transforms import *
from pyspark.context import SparkContext
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
# 读取原始日志
df = glueContext.create_dynamic_frame.from_catalog(
database="company_data",
table_name="events_logs"
)
# 清洗字段
cleaned_df = df.toDF() \
.filter("event_type IS NOT NULL") \
.withColumnRenamed("ts", "event_time")
# 写入 S3(Parquet 格式更高效)
cleaned_df.write.mode("overwrite").parquet("s3://company-data-lake-clean/events/")此过程执行后,我们将“事件日志”变成了结构化、查询友好的数据集。
Step 4:用 Athena 直接查(Gold Layer)
Athena 是 Serverless SQL 查询服务,无需部署数据库,用 SQL 直接查:
SELECT
customer_id,
COUNT(*) AS total_visits,
MAX(event_time) AS last_visit
FROM company_data.events_cleaned
WHERE event_type = 'visit'
GROUP BY customer_id
ORDER BY total_visits DESC可直接连接 QuickSight、Tableau 等可视化工具,做成日常 BI 报表。
🎯 真正的价值:不是“数据在哪”,而是“谁都能用数据”
做数据湖最核心的改变是组织能力:
- 数据工程师不再困在“出报表”里,而是构建平台
- BI 分析师不再依赖技术,而是能通过 Athena 实时跑分析
- 业务负责人第一次看到“全域客户行为路径”,不是通过截图,而是通过可刷新 Dashboard
⚠️ 落地坑点(我们踩过)
- S3 文件小文件过多: Glue 处理效率会骤降,建议用 Parquet + 按小时批次合并。
- Schema 演变难: Glue Crawler 会覆盖旧结构,推荐 Glue Job 手动控制 Catalog 注册。
- Athena 计费不透明: SQL 写得不好,几十 GB 扫描,账单就爆炸 —— 加
WHERE、按分区建表是常识。 - 权限管理复杂: S3、Glue、Athena、QuickSight 是分权限系统,建议统一用 LakeFormation 来治理。
🧠 总结:数据湖的核心,是架构思维而不是工具使用
Glue + Athena 并不只是“更省事的 ETL 工具”,它代表的是一种 将数据流“解耦 + 自动化 + 自服务” 的数据平台思维:S3 是低成本、高弹性的数据中枢、Glue 是自动化与治理的基建引擎、Athena 是低门槛、SQL 化的数据接口、QuickSight 是最后的业务化落点,它们组合起来,就像拼积木,最终拼成了一个面向全公司开放的数据底座。
如果你也想构建一个现代数据湖,建议从这几步入手:
- 🌊 把所有数据统一落地到 S3,不要分散在 FTP、Excel、RDS 中
- 🔍 用 Glue 自动或手动生成 Data Catalog,让数据可被发现
- 🧹 通过 Glue Job 做一次数据清洗、字段标准化
- 📊 用 Athena + BI 工具做第一张报表,把“技术能力”转化为“业务价值”
以上就是本文的全部内容啦。最后提醒一下各位工友,如果后续不再使用相关服务,别忘了在控制台关闭,避免超出免费额度产生费用~
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-07-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号