
创建tidymodel对象的SHAP图
这个问题指的是Obtaining summary shap plot for catboost model with tidymodels in R。鉴于以下问题的评论,“任择议定书”找到了解决办法,但到目前为止还没有与社会分享。
我想分析一下我的树组件,它安装了带有SHAP值图的tidymodels包,例如用于单个观测的图

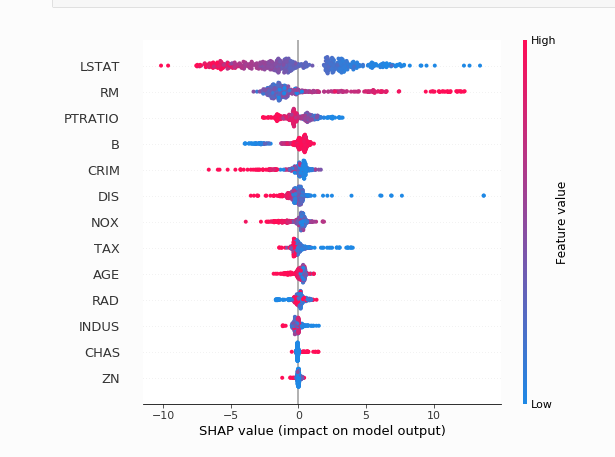
并总结一下我的数据集的所有特性的作用,如
DALEXtra提供了一个函数来为tidymodel explain.tidymodels()创建SHAP值。来自force_plot包的fastshap为底层python包SHAP的绘图函数提供了一个包装器。但我不明白如何使函数与explain.tidymodels()函数的输出一起工作。
问题:如何使用tidymodels和explain.tidymodels在R中生成这样的SHAP图?
MWE (使用explain.tidymodels表示SHAP值)
library(MASS)
library(tidyverse)
library(tidymodels)
library(parsnip)
library(treesnip)
library(catboost)
library(fastshap)
library(DALEXtra)
set.seed(1337)
rec <- recipe(crim ~ ., data = Boston)
split <- initial_split(Boston)
train_data <- training(split)
test_data <- testing(split) %>% dplyr::select(-crim) %>% as.matrix()
model_default<-
parsnip::boost_tree(
mode = "regression"
) %>%
set_engine(engine = 'catboost', loss_function = 'RMSE')
#sometimes catboost is not loaded correctly the following two lines
#ensure prevent fitting errors
#https://github.com/curso-r/treesnip/issues/21 error is mentioned on last post
set_dependency("boost_tree", eng = "catboost", "catboost")
set_dependency("boost_tree", eng = "catboost", "treesnip")
model_fit_wf <- model_fit_wf <- workflow() %>% add_model(model_tune) %>% add_recipe(rec) %>% {parsnip::fit(object = ., data = train_data)}
SHAP_wf <- explain_tidymodels(model_fit_wf, data = X, y = train_data$crim, new_data = test_data回答 1
Stack Overflow用户
发布于 2022-04-15 16:22:19
也许这会有帮助。至少,这是朝着正确方向迈出的一步。
首先,确保安装了快速形状和网状结构(即install.packages(“.”))。接下来,设置一个虚拟环境并安装shap (pip install .)。另外,为依赖关系图安装matplotlib 3.2.2 (请参阅此图上的GitHub问题-需要使用较早版本的matplotlib )。
RStudio拥有丰富的虚拟环境设置信息。也就是说,虚拟环境设置或多或少需要根据使用的IDE进行故障排除。(遗憾的是,一些工作设置由于许可证的原因限制了开放源码RStudio的使用。)
在这方面,图书馆的文档也是有帮助的。
下面是lightgbm的工作流(来自treesnip文档,稍加修改)。
library(tidymodels)
library(treesnip)
data("diamonds", package = "ggplot2")
diamonds <- diamonds %>% sample_n(1000)
# vfold resamples
diamonds_splits <- vfold_cv(diamonds, v = 5)
model_spec <- boost_tree(mtry = 5, trees = 500) %>% set_mode("regression")
# model specs
lightgbm_model <- model_spec %>%
set_engine("lightgbm", nthread = 6)
#workflows
lightgbm_wf <- workflow() %>%
add_model(
lightgbm_model
)
rec_ordered <- recipe(
price ~ .
, data = diamonds
)
lightgbm_fit_ordered <- fit_resamples(
add_recipe(
lightgbm_wf, rec_ordered
), resamples = diamonds_splits)在预测之前,我们希望适应我们的工作流程。
fit_workflow <- lightgbm_wf %>%
add_recipe(rec_ordered) %>%
fit(data = diamonds)现在我们有了一个合适的工作流程,并且可以预测。要使用::explain函数,我们需要创建一个预测函数(这并不总是成立的:取决于所使用的引擎,它可能会或不会开箱即用--参见docs)。
predict_function_gbm <- function(model, newdata) {
predict(model, newdata) %>% pluck(.,1)
}让我们得到平均预测值(用在下面)。这也是一种检查,以确保该功能的运作。
mean_preds <- mean(
predict_function_gbm(
fit_workflow, diamonds %>% select(-price)
)
)现在我们创建我们的解释(shap值)。请注意此处的pred_wrapper和X参数(其他示例--即glmnet)请参见快速see问题。
fastshap::explain(
fit_workflow,
X = as.data.frame(diamonds %>% select(-price)),
pred_wrapper = predict_function_gbm,
nsim = 10
) -> explanations_gbm这应该会产生一个作用力图。
fastshap::force_plot(
object = explanations_gbm[1,],
feature_values = as.data.frame(diamonds %>% select(-price))[1,],
display = "viewer",
baseline = mean_preds) 这允许多个垂直堆叠:
fastshap::force_plot(
object = explanations_gbm[1:20,],
feature_values = as.data.frame(diamonds %>% select(-price))[1:20,],
display = "viewer",
baseline = mean_preds) 为分类添加link = "logit“。将显示更改为"html“以进行Rmarkdown呈现。
现在是摘要图和依赖图。
诀窍是使用网络直接访问函数。请注意,同样的逻辑适用于库,如转换器、numpy等。
首先,对于依赖关系图。
library(reticulate)
shap = import("shap")
np = import("numpy")
shap$dependence_plot(
"rank(3)",
data.matrix(explanations_gbm),
data.matrix(diamond %>% select(-price))
)关于等级(3)-等级(1)等的解释,请参阅shap文档。
不巧的是,当我试图直接命名该特性(即“剪切”)时,它会抛出一个错误。
下面是摘要图:
shap$summary_plot(
data.matrix(explanations_gbm),
data.matrix(diamond %>% select(-price))
)最后注意:反复渲染情节会产生错误的可视化效果。希望这为catboost可视化提供了一个退化点。
https://stackoverflow.com/questions/71662140
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号