
iText 7 html2pdf - Unicode复选框在生成的html2pdf中不存在
iText 7 html2pdf - Unicode复选框在生成的html2pdf中不存在
提问于 2022-09-12 05:48:42
在使用iText 7.0.7和html2pdf 1.0.4的旧实现中,来自html2pdf的unicode符号将显示在输出PDF中。
但是,在升级到iText 7.1.12和html2pdf 3.0.1之后,输出将不显示unicode字符。
如何用新版本恢复旧的行为?
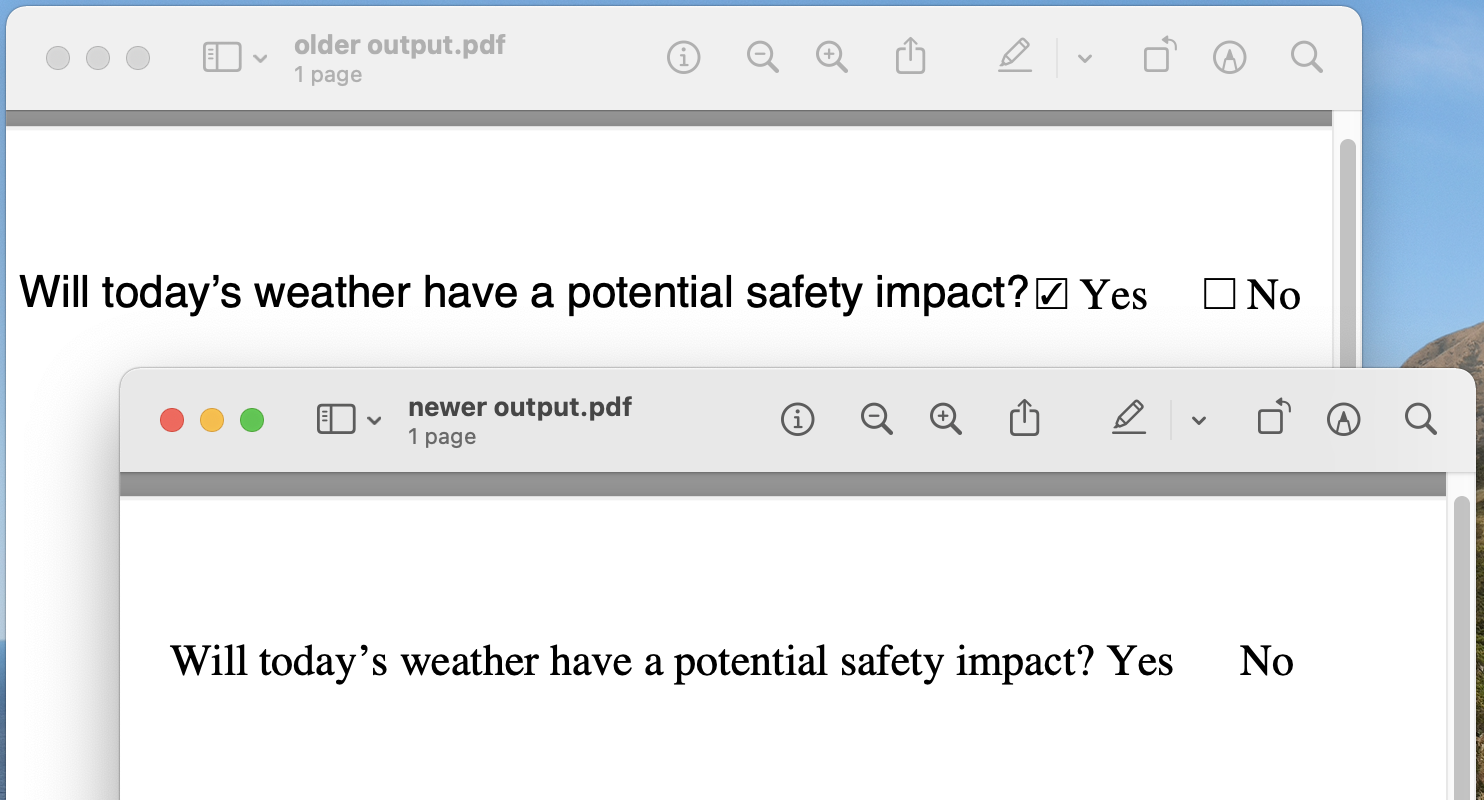
样本输入:
<html>
<head>
<title>STA Form</title>
</head>
<body>
<table>
<tbody>
<tr>
<td>Will today’s weather have a potential safety impact?</td>
<td>
☑ Yes
☐ No
</td>
</tr>
</tbody>
</table>
</body>
</html>回答 1
Stack Overflow用户
发布于 2022-09-17 11:43:05
您只需要在pdfHTML用于转换的一组字体中添加一个包含相关字符/符号的字体。默认情况下,pdfHTML的字体集不能保证每个Unicode字符的存在。
在我的示例中,具有我能够在Windows系统上找到的所需符号的字体是Segoe符号。
如果我将此字体添加到字体提供程序中,并按如下方式将字体提供程序传递到转换器属性,则将得到所需的结果。
ConverterProperties properties = new ConverterProperties();
FontProvider fontProvider = new DefaultFontProvider();
fontProvider.addFont("C:/Windows/Fonts/seguisym.ttf");
properties.setFontProvider(fontProvider);
HtmlConverter.convertToPdf(new File("path/to/file.html"),
new File("path/to/file.pdf"), properties);

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73684957
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号