
Python scrapper不迭代url令牌列表
我正试着从“罗顿番茄”中搜集一些影评人的评论信息。我已经成功地访问了json文件,并且能够使用下面的代码从评论的第一页中提取我需要的数据。问题是,我无法让代码迭代我创建的url标记列表,这些标记应该允许我的刮板移动到数据的其他页面。当前的代码从第一页中提取数据11次(在相同的50个评论中有550条条目),这似乎总是让我感到最简单的事情。有人能告诉我我做错了什么吗?
import requests
import pandas as pd
baseurl = "https://www.rottentomatoes.com/napi/critics/"
endpoint = "alison-willmore/movies?"
tokens = [" ", "after=MA%3D%3D", "after=MQ%3D%3D", "after=Mg%3D%3D", "after=Mw%3D%3D", "after=NA%3D%3D",
"after=NQ%3D%3D", "after=Ng%3D%3D", "after=Nw%3D%3D", "after=OA%3D%3D", "after=OQ$3D%3D"]
def tokenize(t):
for y in t:
return y
def main_request(baseurl, endpoint, x):
r = requests.get(baseurl + endpoint + f'{x}')
return r.json()
reviews = []
def parse_json(response):
for item in response["reviews"]:
review_info = {
'film_title': item["mediaTitle"],
'release_year': item["mediaInfo"],
'full_review_url': item["url"],
'review_date': item["date"],
'rt_quote': item["quote"],
'film_info_link': item["mediaUrl"]}
reviews.append(review_info)
for t in tokens:
data = main_request(baseurl, endpoint, tokenize(t))
parse_json(data)
print(len(reviews))
d_frame = pd.DataFrame(reviews)
print(d_frame.head(), d_frame.tail())回答 2
Stack Overflow用户
发布于 2022-10-16 15:13:51
您的tokenize函数就是问题所在。你给它喂食(例如:“after=MA%3D%3D”),它只会给你回第一个字母'a‘。把标记化处理掉。
for t in tokens:
data = main_request(baseurl, endpoint, t)
parse_json(data)这解决了你的问题,但给你带来了一个新的问题。显然,从JSON获得的密钥并不总是存在的。一个简单的解决方法是稍微重构一下。如果键不存在,使用.get将返回值或第二个参数。
def parse_json(response):
for item in response["reviews"]:
review_info = {
'film_title' : item.get("mediaTitle", None),
'release_year' : item.get("mediaInfo", None),
'full_review_url': item.get("url", None),
'review_date' : item.get("date", None),
'rt_quote' : item.get("quote", None),
'film_info_link' : item.get("mediaUrl", None)
}
reviews.append(review_info)你的最后一个标记有一个错误。after=OQ$....应该是after=OQ%....
如果您感兴趣,我将重构您的整个代码。海事组织,您的代码不必要地支离破碎,这可能是导致您的问题的原因。
import requests
import pandas as pd
baseurl = "https://www.rottentomatoes.com/napi/critics/"
endpoint = "alison-willmore/movies?"
tokens = ("MA%3D%3D", "MQ%3D%3D", "Mg%3D%3D", "Mw%3D%3D", "NA%3D%3D",
"NQ%3D%3D", "Ng%3D%3D", "Nw%3D%3D", "OA%3D%3D", "OQ%3D%3D")
#filter
def filter_json(response):
for item in response["reviews"]:
yield {
'film_title' : item.get("mediaTitle", None),
'release_year' : item.get("mediaInfo" , None),
'full_review_url': item.get("url" , None),
'review_date' : item.get("date" , None),
'rt_quote' : item.get("quote" , None),
'film_info_link' : item.get("mediaUrl" , None)
}
#load
reviews = []
for t in tokens:
r = requests.get(f'{baseurl}{endpoint}after={t}')
for review in filter_json(r.json()):
reviews.append(review)
#use
d_frame = pd.DataFrame(reviews)
print(len(reviews))
print(d_frame.head(), d_frame.tail())Stack Overflow用户
发布于 2022-10-16 15:15:48
问题在于您的main_request方法。在这种情况下,使用print语句或调试器非常有用。
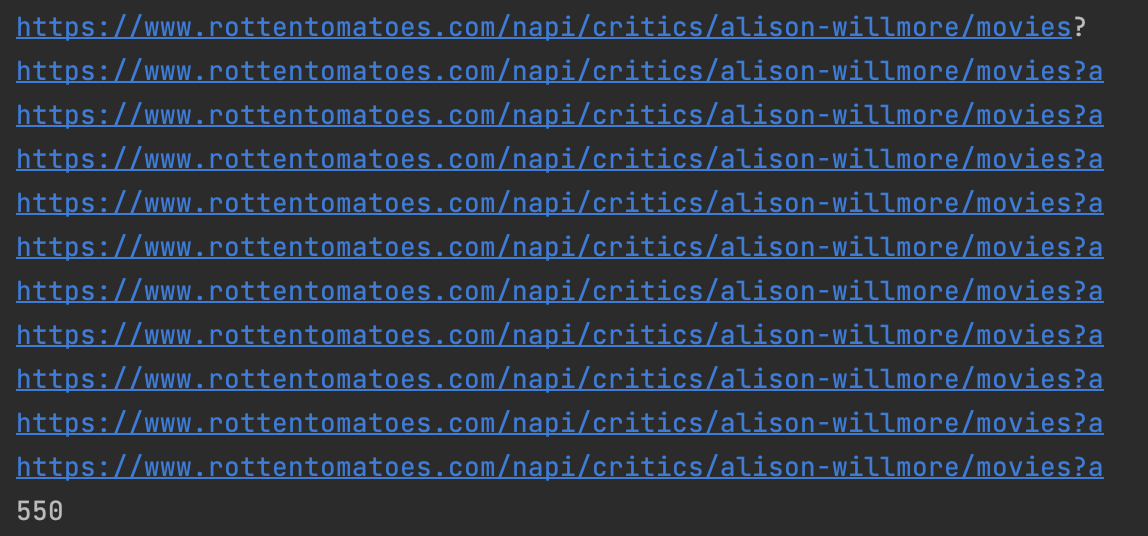
这表明您的代码多次请求同一个url。因此,您的连接不起作用或错了。下一步是弄清楚为什么a是URL中唯一的东西。
def tokenize(t):
for y in t:
return y这是你的罪魁祸首。它迭代一个字符串数组并返回数组中的第一个字符,如果没有意义的话,它就是字母a (来自after=SOMETHING),我会给你看一看。你在这里想做什么?我猜你是想对URL进行编码?不管怎样,试试这个
# Change the parse_json method, this is safer. The way you had it would crash if data was invalid
def parse_json(response):
for item in response["reviews"]:
review_info = {
'film_title': item.get("mediaTitle", None),
'release_year': item.get("mediaInfo", None),
'full_review_url': item.get("url", None),
'review_date': item.get("date", None),
'rt_quote': item.get("quote", None),
'film_info_link': item.get("mediaUrl", None)}
reviews.append(review_info)将循环更改为此或更新tokenize方法。
for t in tokens:
data = main_request(baseurl, endpoint, t)
parse_json(data)https://stackoverflow.com/questions/74087827
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号