
如何防止thrust::reduce_by_key写入可分页内存?
我正在编写一个应用程序,它使用几个并发的CUDA流。当我的thrust::reduce_by_key调用似乎写入可分页内存时,我的其他流阻塞了。我认为返回值才是问题所在。
如何防止将返回值写入可分页内存?
我将包括演示我尝试的解决方案的代码。
#include <thrust/system/cuda/vector.h>
#include <thrust/host_vector.h>
#include <thrust/pair.h>
#include <iostream>
#include <thrust/device_vector.h>
#include <thrust/reduce.h>
#include <thrust/random.h>
int main(void)
{
int N = 20;
thrust::default_random_engine rng;
thrust::uniform_int_distribution<int> dist(10, 99);
// initialize data
thrust::device_vector<int> array(N);
for (size_t i = 0; i < array.size(); i++)
array[i] = dist(rng);
// allocate storage for sums and indices
thrust::device_vector<int> sums(N);
thrust::device_vector<int> indices(N);
// make a pinned memory location for the returned pair of iterators
typedef thrust::device_vector<int>::iterator dIter;
thrust::pair<dIter, dIter>* new_end;
const unsigned int bytes = sizeof(thrust::pair<dIter, dIter>);
cudaMallocHost((void**)&new_end, bytes);
for(int i = 0 ; i< 20; i++){ // you can see in the profiler each operator writes 4 bytes to pageable memory
*new_end = thrust::reduce_by_key
(thrust::make_counting_iterator(0),
thrust::make_counting_iterator(N),
array.begin(),
indices.begin(),
sums.begin(),
thrust::equal_to<int>(),
thrust::plus<int>());
}
std::cout << "done \n";
return 0;
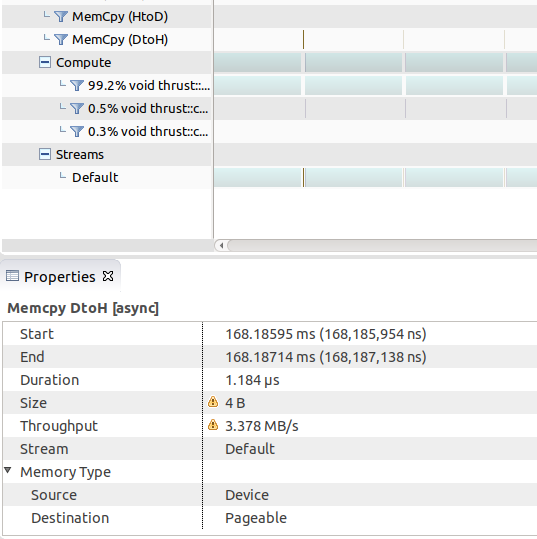
}这是我的分析器的图片,显示从设备复制到宿主可分页内存。
回答 1
Stack Overflow用户
发布于 2020-07-15 19:07:45
我正在编写一个应用程序,它使用几个并发的CUDA流。当我的
thrust::reduce_by_key似乎写入可分页内存时,我的其他流阻塞了。
这种阻塞行为不是由“写入可分页内存”造成的。这是由显式同步调用引起的。一般来说,截至数据自动化系统10.1 (推力1.9.4)释放,所有正常的同步算法都是阻塞的。。您可以通过使用分析器检查API跟踪来确认这一点。但是,您至少可以通过将调用启动到流来限制阻塞的范围,尽管我太懒于测试这是否以一种有用的方式修改了cuda_cub::synchronize的行为。
如何防止将返回值写入可分页内存?
这并不是说这与您的问题有任何关系,但您不能这样做。重要的是要记住,与您最初提出的问题相反,thrust::reduce_by_key不是内核,而是执行一系列操作(包括将返回值从设备内存复制到主机堆栈变量 )的主机代码。没有程序员对内部的控制,而且很明显,试图使用自己的固定内存值来接受通过值传递的结果是荒谬的,也不会有任何效果。
正如注释中所建议的那样,如果您需要按照您的问题所建议的操作内部控制粒度级别,则推力是错误的选择。使用钥匙 -这是相同的算法实现推力使用,但您可以得到明确的控制刮伤内存,同步,流,以及如何访问的结果调用。然而,这并不适合初学者。
https://stackoverflow.com/questions/62907675
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号