
不能用model.fit复制GradientTape
我一直在试图调查为什么SGD在训练中有0.001的学习率,而Adam却没有这样做。(请看我以前的帖子这里)
注意:我在这里也使用了我之前的文章中的模型。
使用tf.keras,我用model.fit()训练神经网络
model.compile(optimizer=SGD(learning_rate=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(x=ds,
epoch=80,
validation_data=ds_val)这导致了一个划时代的损失,如下图所示,在第一个时期内,列车损失为0.46,最终导致train_loss为0.1241,val_loss为0.2849。
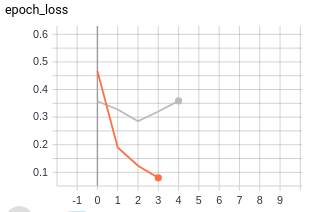
我本想用tf.keras.callbacks.Tensorboard(histogram_freq=1)训练网络,同时使用SGD(0.001)和Adam来进行调查,但它在变量0上抛出了一个InvalidArgumentError,这是我无法破解的。因此,我尝试使用GradientTape编写一个自定义培训循环并绘制这些值。
使用tf.GradientTape(),我尝试使用完全相同的模型和数据集来再现结果,但是,时间损失的训练速度非常慢,在15个周期后达到了0.676的列车损失(见下图),我的实现有什么问题吗?(代码如下)
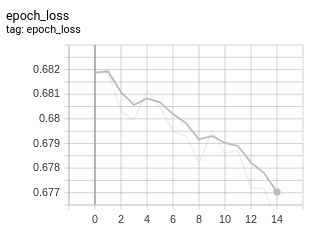
@tf.function
def compute_grads(train_batch: Dict[str,tf.Tensor], target_batch: tf.Tensor,
loss_fn: Loss, model: tf.keras.Model):
with tf.GradientTape(persistent=False) as tape:
# forward pass
outputs = model(train_batch)
# calculate loss
loss = loss_fn(y_true=target_batch, y_pred=outputs)
# calculate gradients for each param
grads = tape.gradient(loss, model.trainable_variables)
return grads, lossBATCH_SIZE = 8
EPOCHS = 15
bce = BinaryCrossentropy()
optimizer = SGD(learning_rate=0.001)
for epoch in tqdm(range(EPOCHS), desc='epoch'):
# - accumulators
epoch_loss = 0.0
for (i, (train_batch, target_dict)) in tqdm(enumerate(ds_train.shuffle(1024).batch(BATCH_SIZE)), desc='step'):
(grads, loss) = compute_grads(train_batch, target_dict['target'], bce, model)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
epoch_loss += loss
avg_epoch_loss = epoch_loss/(i+1)
tensorboard_scalar(writer, name='epoch_loss', data=avg_epoch_loss, step=epoch) # custom helper function
print("Epoch {}: epoch_loss = {}".format(epoch, avg_epoch_loss))提前感谢!
回答 1
Stack Overflow用户
发布于 2020-03-18 10:24:17
检查您是否洗牌了您的数据集,那么问题可能来自使用tf.Dataset方法的洗牌。它当时只在一个桶中遍历数据集。使用Keras.Model.fit会产生更好的效果,因为它可能会增加另一次洗牌。通过在numpy.random.shuffle中加入洗牌,可以提高训练效果。从这份推荐信。
将其应用于数据集生成的示例如下:
numpy_data = np.hstack([index_rows.reshape(-1, 1), index_cols.reshape(-1, 1), index_data.reshape(-1, 1)])
np.random.shuffle(numpy_data)
indexes = np.array(numpy_data[:, :2], dtype=np.uint32)
labels = np.array(numpy_data[:, 2].reshape(-1, 1), dtype=np.float32)
train_ds = data.Dataset.from_tensor_slices(
(indexes, labels)
).shuffle(100000).batch(batch_size, drop_remainder=True)如果这不起作用,您可能需要使用Dataset .repeat(epochs_number) and .shuffle(..., reshuffle_each_iteration=True):。
train_ds = data.Dataset.from_tensor_slices(
(np.hstack([index_rows.reshape(-1, 1), index_cols.reshape(-1, 1)]), index_data)
).shuffle(100000, reshuffle_each_iteration=True
).batch(batch_size, drop_remainder=True
).repeat(epochs_number)
for ix, (examples, labels) in train_ds.enumerate():
train_step(examples, labels)
current_epoch = ix // (len(index_data) // batch_size)这个解决办法既不美丽,也不自然,现在你可以用它来洗牌每一个时代。这是一个已知的问题,并将得到解决,今后您可以使用for epoch in range(epochs_number)而不是.repeat()
提供的解决方案这里也可能有很大帮助。你可能想去看看。
如果不是这样的话,您可能希望加速TF2.0 GradientTape。这可以是解决方案: TensorFlow 2.0引入了函数的概念,它将急切的代码转换成图形代码。
用法相当直截了当。唯一需要的改变是所有相关的函数(like compute_loss和apply_gradients)都必须使用@tf.function.进行注释。
https://stackoverflow.com/questions/60604707
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号