
如何在新df中配置和保存其他变量
如何在新df中配置和保存其他变量
提问于 2021-05-15 03:08:35
很抱歉有这么愚蠢的问题。我有一个如下所示的df:
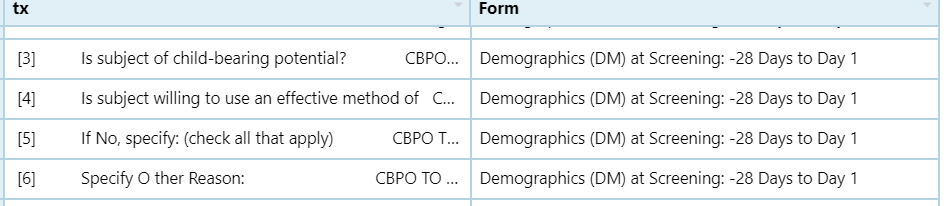
我想将tx与data.frame(do.call("rbind", strsplit(as.character(df$tx), "\\s{2,}" )), stringsAsFactors=FALSE)分开,如何在新的df中保留Form?此外,如果拆分结果是空的,如何避免它自动填充?
可以使用以下方法构建示例df:
df<- structure(list(tx = c(" [1] Timepoint EGTMPT Categorical select one (nominal) 51 Screening",
" [2] N/A : O ff-Study EGTNA Categorical yes/no (dichotomous) 3",
" [3] Check if Not Done EGTMPTND Categorical yes/no (dichotomous) 3",
" [4] Date Performed ECGDT Date 11",
" [5] Time (24-hour format) ECGTM Time 5",
" [6] O verall ECG Interpretation ECGRES Categorical select one (nominal) 37 Normal"
), Form = c("12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)",
"12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)",
"12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)",
"12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)",
"12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)",
"12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)"
)), row.names = c(NA, 6L), class = "data.frame")输出将如下所示:

更新:我应该如何更好地分离tx。我的旧代码似乎会产生错误。样本数据如下:
df<-structure(list(tx = c("[6] O verall ECG Interpretation ECGRES Categorical select one (nominal) 37 Normal",
"[7] If A bnormal - Clinically Significant, describe ECGA BN Text or A ny V alue 200",
"[8] PR Interval (ms) ECGPRIN Number (continuous) 15",
"[1] Not Done PE2ND Categorical yes/no (dichotomous) 3",
"[2] If Not Done, specify reason: PE2NDR Text or A ny V alue 200",
"[4] Start Date: A ESTDTC Date 11",
"[5] End Date A EENDTC Date 11",
"[6] O ngoing: A EO NGO Categorical yes/no (dichotomous) 3",
"[7] Seriousness Criteria: (check all that apply) A ESA E Categorical select multiple 50",
"[8] Severity: A ECTCA E Categorical select one (nominal) 26 Grade 1 - Mild",
"[2] If Not Done, specify reason: CHMNO Text or A ny V alue 200",
"[6] Laboratory ID (NO TE: If Lab ID is not present, CHMID Categorical select one (nominal) 71 Christus Mother Frances Hospital Laboratory",
"[1] Has subject had any prior surgery related to the PSYN Categorical yes/no (dichotomous) 3",
"[2] Cycle 1 O nly: If less than the expected number of EXBC1 Categorical select one (nominal) 3",
"[3] Cycle EXBCYC Categorical select one (nominal) 8 Cycle 1",
"[4] Dose (mg) EXBDO S Number (continuous) 15",
"[5] Frequency EXBFRQ Categorical select one (nominal) 3 BID",
"[6] Start Date EXBSTDT Date 11",
"[7] Stop Date EXBENDT Date 11",
"[8] Reason for End Date/Stopping EXBREA Categorical select one (nominal) 36 Cycle Completed",
"[9] O ther Reason (specify) EXBREA S Text or A ny V alue 200"
)), row.names = c(NA, -21L), class = c("tbl_df", "tbl", "data.frame"
))我的产出是:
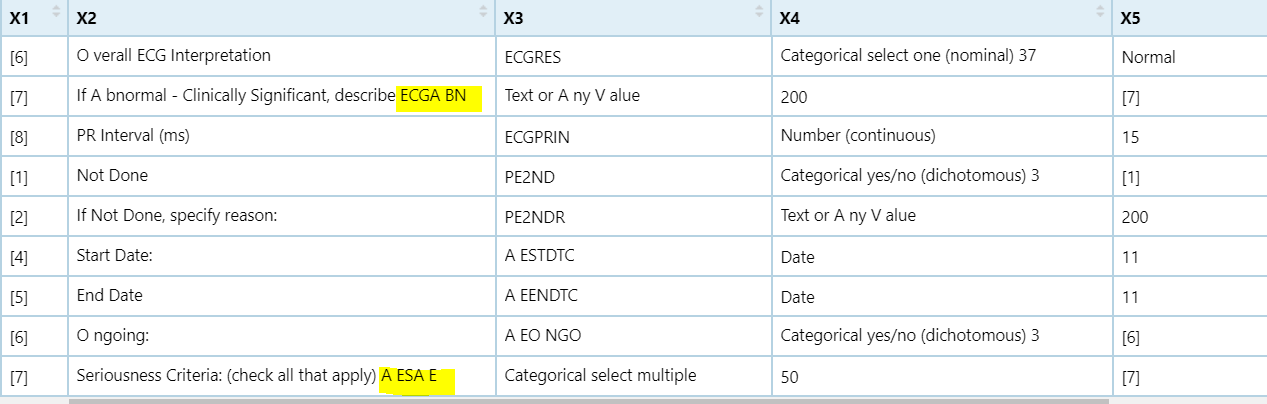
黄色部分应该用x3代替。我该怎么办?
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-05-15 03:24:05
您可以使用splitstackshape::cSplit:
splitstackshape::cSplit(df, 'tx', sep = '\\s{2,}', fixed = FALSE)
# Form tx_1
#1: 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK) [1]
#2: 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK) [2]
#3: 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK) [3]
#4: 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK) [4]
#5: 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK) [5]
#6: 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK) [6]
# tx_2 tx_3 tx_4 tx_5
#1: Timepoint EGTMPT Categoricals{2,}elect one (nominal) 51 Screening
#2: N/A : O ff-Study EGTNA Categorical yes/no (dichotomous) 3 <NA>
#3: Check if Not Done EGTMPTND Categorical yes/no (dichotomous) 3 <NA>
#4: Date Performed ECGDT Date 11
#5: Time (24-hour format) ECGTM Time 5
#6: O verall ECG Interpretation ECGRES Categoricals{2,}elect one (nominal) 37 Normal使用tidyr::separate:
tidyr::separate(df, 'tx', paste0('col', 1:5), sep = '\\s{2,}', fill = 'right')Stack Overflow用户
发布于 2021-05-15 07:21:38
使用read.csv()清洗后,您可以使用gsub。
内部gsub为右边的数字列提供更多的空间,外部将空白转换为逗号,这是read.csv()中的默认sep=','。
dat_clean <- cbind(read.csv(text=gsub('\\s{2,}', ',', gsub('\\s+(\\d+)', ' \\1', trimws(df$tx))),
header=F, na.strings=''), Form=df$Form)
dat_clean
# V1 V2 V3 V4 V5 V6
# 1 [1] Timepoint EGTMPT Categorical select one (nominal) 51 Screening
# 2 [2] N/A : O ff-Study EGTNA Categorical yes/no (dichotomous) 3 <NA>
# 3 [3] Check if Not Done EGTMPTND Categorical yes/no (dichotomous) 3 <NA>
# 4 [4] Date Performed ECGDT Date 11 <NA>
# 5 [5] Time (24-hour format) ECGTM Time 5 <NA>
# 6 [6] O verall ECG Interpretation ECGRES Categorical select one (nominal) 37 Normal
# Form
# 1 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)
# 2 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)
# 3 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)
# 4 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)
# 5 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)
# 6 12-Lead Electrocardiogram (EG) at Log Pages (Dosing, ECG, PBMC, Biomarkers, PK)最好是我们可以使用read.fwf(),但它似乎只从文件中读取。
注意,如果在您的数据中左边的列中有遗漏,那么您可能需要稍微修改一下代码。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67542940
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号