
稀疏-稠密乘法x4在x100上花费更多时间
稀疏-稠密乘法x4在x100上花费更多时间
提问于 2014-03-27 18:05:32
首先,我尝试了一个具有以下大小的稀疏稠密乘法:
C1 [8692 x 8692] = A1 [8692 x 7000 sparse] x B1 [7000 x 8692]它只需0.3秒。然后我又做了一个尺寸如下的:
C2 [8820 x 8820] = A2 [8820 x 32000 sparse] x B2 [32000 x 8820]所需时间因稀疏矩阵中的内容而异,但从30秒到90秒不等。我能做些什么来加速它吗?如果可以减少运行时间,我可以以不同的方式分割矩阵,但我不确定性能问题是什么。
稀疏矩阵A1和A2是以CSR格式存储的,它们确实有一个不好的稀疏模式,但它们同样糟糕。下面的两个图分别显示了非零元素在A1和A2中的位置。在这两种情况下,每列的非零元素被控制为固定在127.
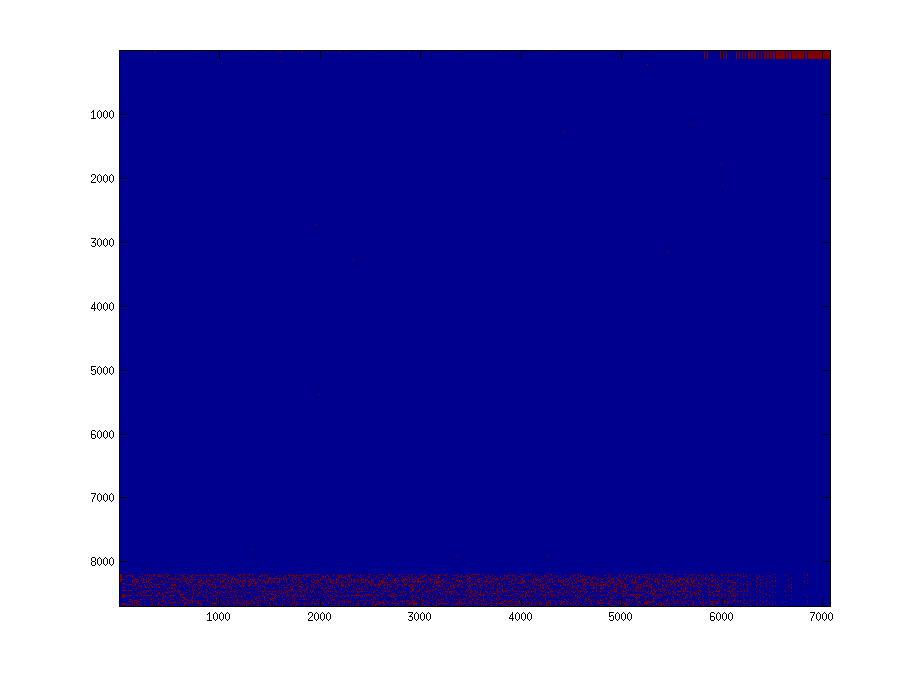
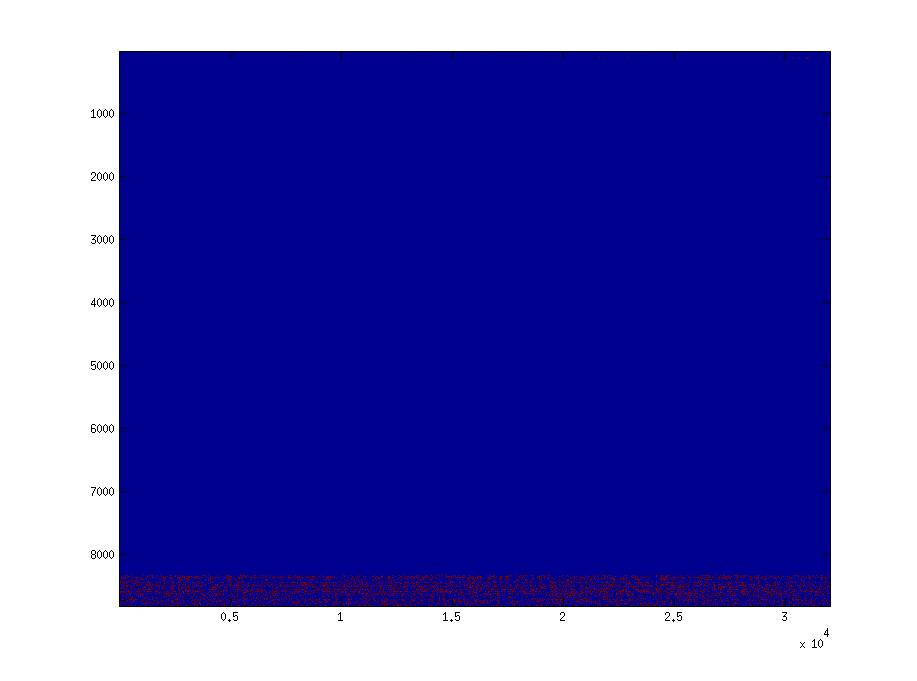
回答 1
Stack Overflow用户
回答已采纳
发布于 2014-03-28 00:50:10
从矩阵的稀疏模式来看,您应该将矩阵A1分成两个部分,其中包含大约前8000行的矩阵A11,并使用csrmv两次。通过这种方式,质解析将为每一行的线程数选择一个更好的启发式。
您还应该考虑使用CUSPARSE6.0 csrmv2中的新版本和转置情况。您需要首先转接B(使用cublasgeam ),然后执行以下操作:
C= A1 * (B')‘
转置情况要好得多,因为对B的访问都是合并的。
另一种选择是使用A1 (使用cusparsecsr2dense )并使用cublas。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/22695742
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号