
无法将提取的文本写入csv中的单个行
无法将提取的文本写入csv中的单个行
提问于 2017-04-19 11:44:38
这可以被认为是问题使用Selenium在元素中查找元素的第二部分。
我在这里所做的是,在从表中提取每个文本之后,将其写入csv文件
以下是代码:
from selenium import webdriver
import os
import csv
chromeDriver = "/home/manoj/workspace2/RedTools/test/chromedriver"
os.environ["webdriver.chrome.driver"] = chromeDriver
driver = webdriver.Chrome(chromeDriver)
driver.get("https://www.betfair.com/exchange/football/coupon?id=2")
list2 = driver.find_elements_by_xpath('//*[@data-sportid="1"]')
couponlist = []
finallist = []
for game in list2[1:]:
coup = game.find_element_by_css_selector('span.home-team').text
print(coup)
couponlist.append(coup)
print(couponlist)
print('its done')
outfile = open("./footballcoupons.csv", "wb")
writer = csv.writer(outfile)
writer.writerow(["Games"])
writer.writerows(couponlist)3份打印报表的结果:
Santos Laguna
CSMS Iasi
AGF
Besiktas
Malmo FF
Sirius
FCSB
Eibar
Newcastle
Pescara
[u'Santos Laguna', u'CSMS Iasi', u'AGF', u'Besiktas', u'Malmo FF', u'Sirius', u'FCSB', u'Eibar', u'Newcastle', u'Pescara']
its done现在,您可以注意到我将这些值写入csv的代码。但最后我奇怪地把它写进了csv。请看快照。有人能帮我把这个修好吗?
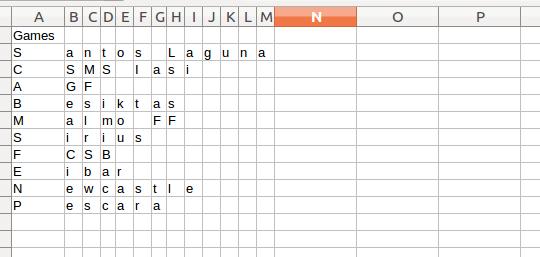
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-04-19 12:11:42
根据文献资料,writerows使用一个行列表作为参数,并且
行必须是用于Writer对象的字符串或数字的可迭代
您正在传递一个字符串列表,因此writerows对您的字符串进行迭代,从每个字符中生成一行。
您可以使用一个循环:
for team in couponlist:
writer.writerow([team])或者将列表转换为列表,然后使用writerows:
couponlist = [[team] for team in couponlist]
writer.writerows(couponlist)但是无论如何,如果您只有一个列,就没有必要使用csv .
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/43494814
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号