
TPU术语混淆
所以我知道时代,火车步骤,批次大小和这类东西是如何定义的,但是我真的很难让我的头绕着TPU的术语,比如火车循环,每个循环迭代等等。我读过这,但仍然很困惑。
另外,我如何对每个循环的迭代时间进行基准测试。
任何解释都对我有很大帮助。谢谢!
回答 3
Stack Overflow用户
发布于 2018-09-14 19:55:33
通过“列车循环”,我假设它与“训练回路”的含义相同。训练循环是迭代每一个时代以给模型提供信息的循环。
每个循环的迭代与Cloud如何处理训练循环有关。为了摊销TPU的启动成本,模型训练步骤被包装在一个tf.while_loop中,这样一个会话运行实际上会为一个训练循环运行多个迭代。
因此,Cloud在返回到主机之前会运行特定数量的训练循环迭代。因此,iterations_per_loop是为一个session.run调用运行多少次迭代。
Stack Overflow用户
发布于 2018-09-17 21:48:07
正如其他答案所描述的,iterations_per_loop是一个调优参数,它控制TPU在再次签入之前完成的工作量。较低的数目使您可以更频繁地检查结果(并对其进行基准测试),而更高的数目可以减少由于同步而造成的开销。
这与熟悉的网络或文件缓冲技术没有什么不同;更改其值会影响性能,但不会影响最终结果。相反,ML超参数(如num_epochs、train_steps或train_batch_size )将改变您的结果。
编辑:以伪代码添加插图,如下所示。从理论上讲,培训循环的功能如下:
def process_on_TPU(examples, train_batch_size, iterations_per_loop):
# The TPU will run `iterations_per_loop` training iterations before returning to the host
for i in range(0, iterations_per_loop):
# on every iteration, the TPU will compute `train_batch_size` examples,
# calculating the gradient from every example in the given batch
compute(examples[i * train_batch_size : (i + 1) * train_batch_size])
# assume each entry in `example` is a single training example
for b in range(0, train_steps, train_batch_size * iterations_per_loop)
process_on_TPU(examples[b:b + train_batch_size * iterations_per_loop],
train_batch_size,
iterations_per_loop)由此可以看出,train_batch_size和iterations_per_loop只是完成同一件事的两种不同的方式。但是,情况并非如此;train_batch_size影响学习速度,因为(至少在ResNet-50中)梯度是根据批处理中每个示例的平均梯度在每次迭代时计算的。每50k个例子执行50个步骤将产生与每50k个例子1k步不同的结果,因为后者计算梯度的频率要高得多。
编辑2:下面的是一种可视化正在发生的事情的方法,用一个赛车隐喻。将TPU想象为运行一个具有train_steps示例距离的比赛,它的步幅允许它每一步覆盖一批示例。比赛是在一条赛道上,它比总比赛距离短;圈的长度是你训练例子的总数,每一圈围绕着赛道是一个时代。您可以将iterations_per_loop看作是这样的点,TPU可以停在某种类型的“水站”,这样的话,培训就会暂停,用于各种任务(基准测试、检查点、其他内务管理)。
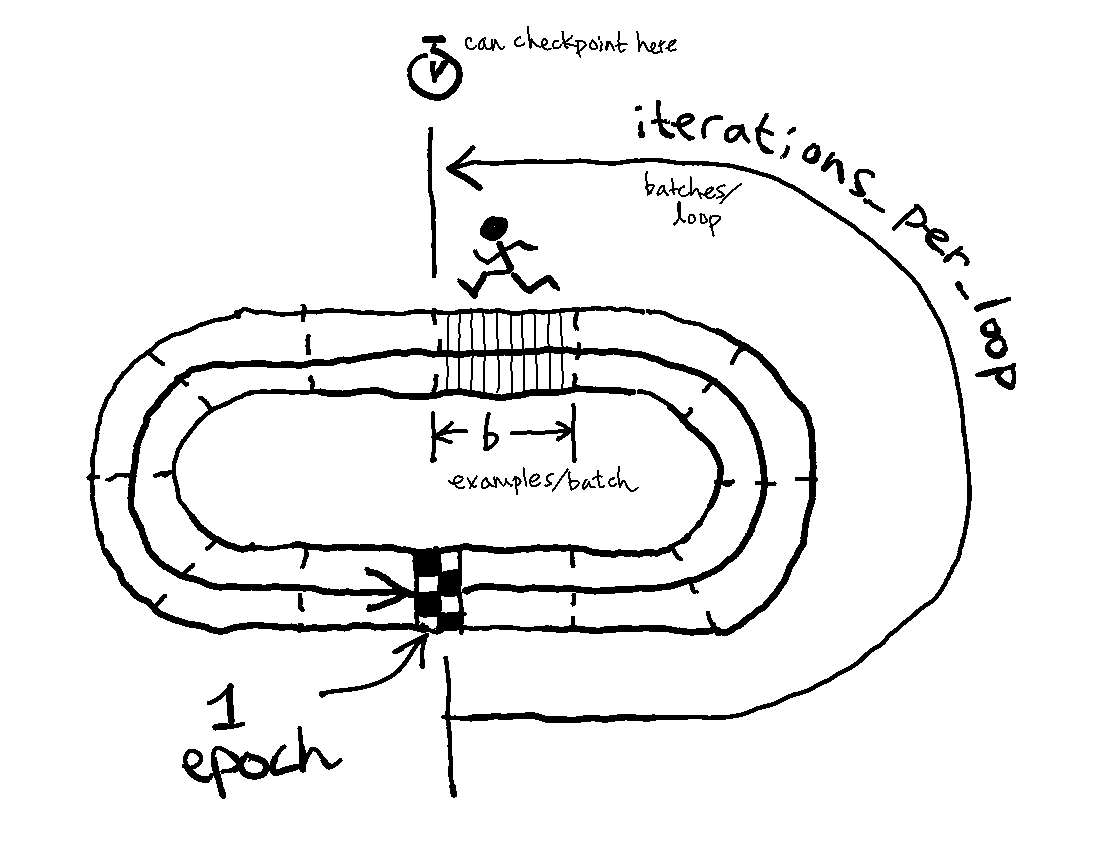
Stack Overflow用户
发布于 2018-09-14 19:51:37
TPU的字面意思是“张量处理单元”,它是一种硬件设备,用于计算,与使用GPU的方式完全相同。TPU实际上是谷歌专有的GPU。GPU与TPU的引擎盖下存在技术差异,主要涉及速度和功耗,以及浮点精度的一些问题,但您不需要关心细节。
iterations_per_loop似乎是通过加载多个培训批来提高效率的一种努力。在将大量数据从主存传输到GPU/TPU时,往往存在硬件带宽限制。
您所引用的代码似乎是将培训批的iterations_per_loop数传递给TPU,然后在暂停执行从主内存到TPU内存的另一个数据传输之前运行iterations_per_loop数量的培训步骤。
不过,我很惊讶地看到,现在异步后台数据传输已经成为可能。
我唯一的免责声明是,虽然我精通Tensorflow,并且在论文和文章中观察了TPU的发展,但我没有直接使用Google API或运行在TPU上的经验,所以我从您链接的文档中所读到的内容推断。
https://stackoverflow.com/questions/52335516
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号