
Dataframe中的贝叶斯平均
我试图根据数据(逐行)提取一系列贝叶斯平均值。
例如,假设我有一系列(0到1)用户对糖果的评级,存储在一个数据文件中,如下所示:
User1 User2 User3
Snickers 0.01 NaN 0.7
Mars Bars 0.25 0.4 0.1
Milky Way 0.9 1.0 NaN
Almond Joy NaN NaN NaN
Babe Ruth 0.5 0.1 0.3我想在不同的DF中创建一个列,它表示每个糖果条的贝叶斯平均值。
为了计算BA,我使用了这里提出的方程
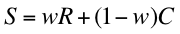
- S=糖果条的分数
- R=用户对糖果条的平均评分
- C=所有糖果的用户平均评级
- W=分配给R的权重,计算为v/(v+m),其中v是该糖果条的用户评等数,m是所有糖果条的平均评论数。
我已经把它翻译成python了:
def bayesian_average(df):
"""given a dataframe, returns a series of bayesian averages"""
R = df.mean(axis=1)
C = df.sum(axis=1).sum()/df.count(axis=1).sum()
w = df.count(axis=1)/(df.count(axis=1)+(df.count(axis=1).sum()/len(df.dropna(how='all', inplace=False))))
return ((w*R) + ((1-w)*C))
other_df['bayesian_avg'] = bayesian_average(ratings_df)然而,我的计算似乎是错误的,因为我的初始数据中的用户列数在增长,最终计算的贝叶斯平均值也会增长(变成大于1的数字)。
这是我正在使用的基本方程的问题,还是我如何将它转化为python的问题?或者,是否有更简单的方法来处理这个问题(例如,预先存在的包/函数)?
谢谢!
回答 1
Stack Overflow用户
发布于 2019-01-25 02:25:38
我从您给出的dataframe作为示例开始:
d = {
'Bar': ['Snickers', 'Mars Bars', 'Milky Way', 'Almond Joy', 'Babe Ruth'],
'User1': [0.01, 0.25, 0.9, np.nan, 0.5],
'User2': [np.nan, 0.4, 1.0, np.nan, 0.1],
'User3': [0.7, 0.1, np.nan, np.nan, 0.3]
}
df = pd.DataFrame(data=d)看起来是这样的:
Bar User1 User2 User3
0 Snickers 0.01 NaN 0.7
1 Mars Bars 0.25 0.4 0.1
2 Milky Way 0.90 1.0 NaN
3 Almond Joy NaN NaN NaN
4 Babe Ruth 0.50 0.1 0.3我做的第一件事是创建一个具有用户评论的所有列的列表:
user_cols = []
for col in df.columns.values:
if 'User' in col:
user_cols.append(col)接下来,我发现将贝叶斯平均方程的每个变量作为dataframe中的列或作为独立变量创建是最简单的:
- 计算每个条形图的
v值:df['v'] = df[user_cols].count(axis=1) - 计算
m的值(在本例中等于2.0 ):m = np.mean(df['v']) - 计算每个条形图的
w值:df['w'] = df['v']/(df['v'] + m) - 并计算每个栏的
R值:df['R'] = np.mean(df[user_cols], axis=1) - 最后,获取
C的值(在本例中等于0.426 ):C = np.nanmean(df[user_cols].values.flatten())
现在我们已经准备好计算每个糖果条的贝叶斯平均分数,S:
df['S'] = df['w']*df['R'] + (1 - df['w'])*C
这给了我们一个数据,如下所示:
Bar User1 User2 User3 v w R S
0 Snickers 0.01 NaN 0.7 2 0.5 0.355 0.3905
1 Mars Bars 0.25 0.4 0.1 3 0.6 0.250 0.3204
2 Milky Way 0.90 1.0 NaN 2 0.5 0.950 0.6880
3 Almond Joy NaN NaN NaN 0 0.0 NaN NaN
4 Babe Ruth 0.50 0.1 0.3 3 0.6 0.300 0.3504其中,最后一列S包含糖果条的所有S分数。如果需要,可以删除v、w和R临时列:df = df.drop(['v', 'w', 'R'], axis=1)
Bar User1 User2 User3 S
0 Snickers 0.01 NaN 0.7 0.3905
1 Mars Bars 0.25 0.4 0.1 0.3204
2 Milky Way 0.90 1.0 NaN 0.6880
3 Almond Joy NaN NaN NaN NaN
4 Babe Ruth 0.50 0.1 0.3 0.3504https://stackoverflow.com/questions/54357300
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号