
不适当,过拟合,Good_Generalization
因此,作为我作业的一部分,我使用线性和套索回归,下面是问题7。
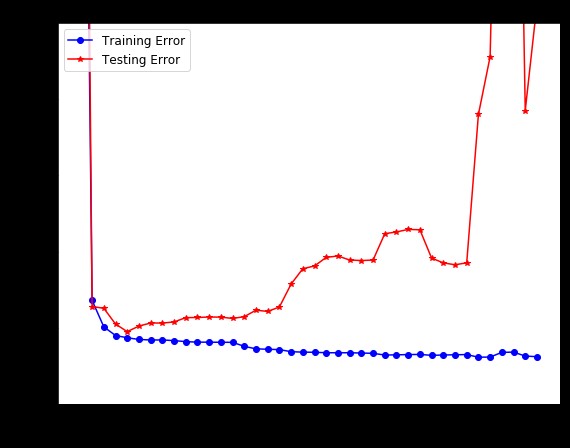
根据问题6的分数,哪一个伽马值对应于一个不合适的模型(而且测试集的准确度最差)?哪个伽马值对应于一个过度拟合的模型(而且测试集的精度最差)?在该数据集上具有良好泛化性能的模型(在训练和测试集上都具有高精度),什么样的伽玛选择是最好的选择? 提示:试着绘制第6题的分数,以可视化伽马和准确性之间的关系。请记住在提交之前注释出导入matplotlib行。
此函数应返回一个元组,并按此顺序返回度值:(欠拟合、过拟合、Good_Generalization) 请注意,只有一个正确的解决方案。。
我真的需要帮助,我真的想不出解决最后一个问题的任何方法。我应该使用什么代码来确定(不适当拟合,过度拟合,Good_Generalization)以及为什么?
谢谢,
数据集:http://archive.ics.uci.edu/ml/datasets/Mushroom?ref=datanews.io
这是问题6的代码:
from sklearn.svm import SVC
from sklearn.model_selection import validation_curve
def answer_six():
# SVC requires kernel='rbf', C=1, random_state=0 as instructed
# C: Penalty parameter C of the error term
# random_state: The seed of the pseudo random number generator
# used when shuffling the data for probability estimates
# e radial basis function kernel, or RBF kernel, is a popular
# kernel function used in various kernelized learning algorithms,
# In particular, it is commonly used in support vector machine
# classification
model = SVC(kernel='rbf', C=1, random_state=0)
# Return numpy array numbers spaced evenly on a log scale (start,
# stop, num=50, endpoint=True, base=10.0, dtype=None, axis=0)
gamma = np.logspace(-4,1,6)
# Create a Validation Curve for model and subsets.
# Create parameter name and range regarding gamma. Test Scoring
# requires accuracy.
# Validation curve requires X and y.
train_scores, test_scores = validation_curve(model, X_subset, y_subset, param_name='gamma', param_range=gamma, scoring ='accuracy')
# Determine mean for scores and tests along columns (axis=1)
sc = (train_scores.mean(axis=1), test_scores.mean(axis=1))
return sc
answer_six() 回答 2
Stack Overflow用户
发布于 2019-02-10 00:05:30
Stack Overflow用户
发布于 2020-12-24 14:26:48
过拟合=你的模型假,如果模型假散射,它将线性地改变为多个或支持向量与工作内核.欠拟合=您的数据集错误添加新数据理想相关.
检查测试和训练的得分/准确性,如果测试和训练高,没有很大的差别,你做得很好。如果测试过低或训练过低,那么你就会面临过度/不足的情况。
霍普解释说..。
https://stackoverflow.com/questions/54611983
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号