
为什么我的CNN太合适了,我怎样才能修复它?
我正在制作一个名为C3D的3D-CNN,它最初是训练从视频剪辑中分类运动的。
我正在冻结卷积(特征提取)层,并使用GIPHY的gifs对完全连接的层进行训练,以便对gifs进行情感分析(正或负)。
除最终完全连接的层外,所有层的重量都预先加载。
我使用5000张图像(2500张正面,2500张负片)进行训练,使用Keras进行70/30的培训/测试分割。我正在使用Adam优化器,其学习速率为0.0001。
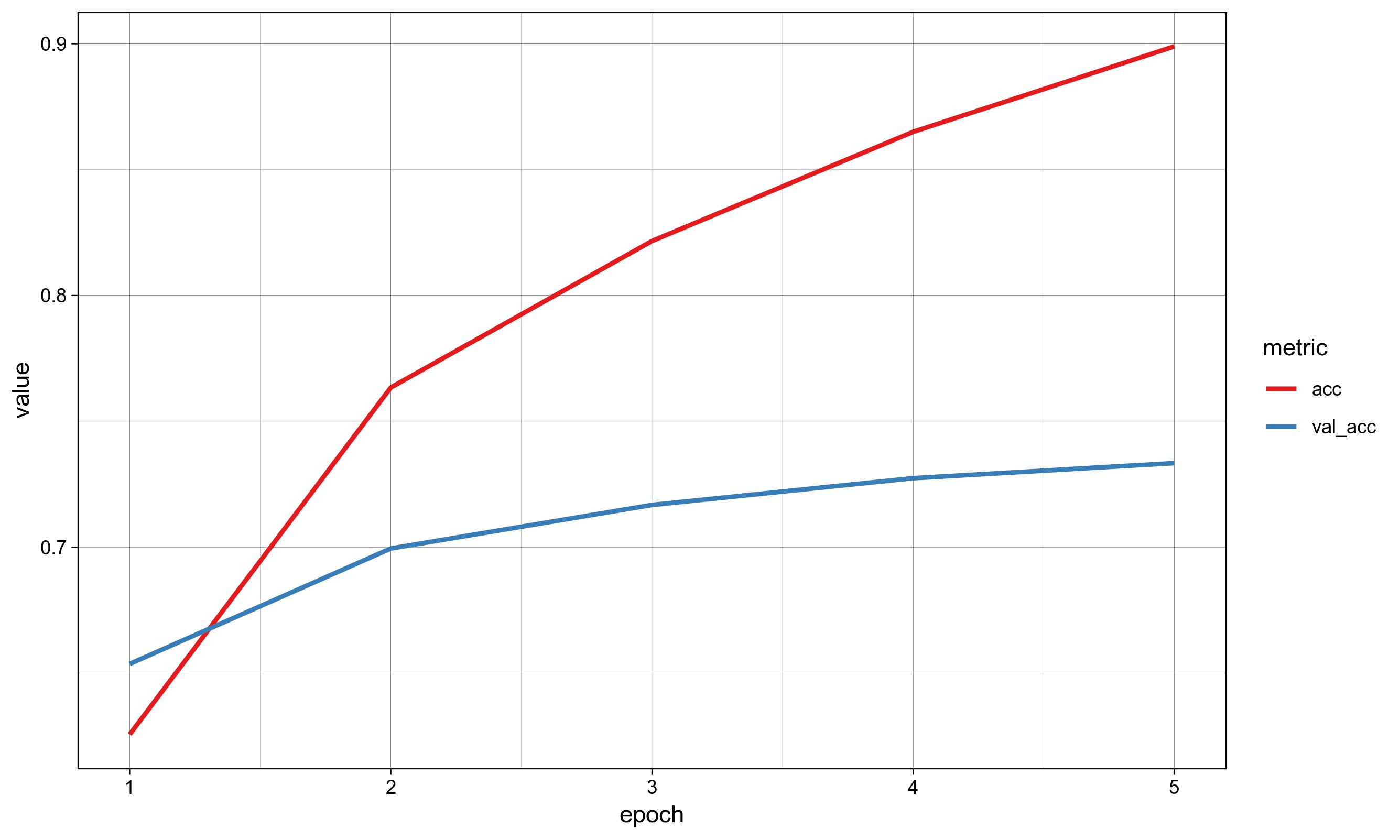
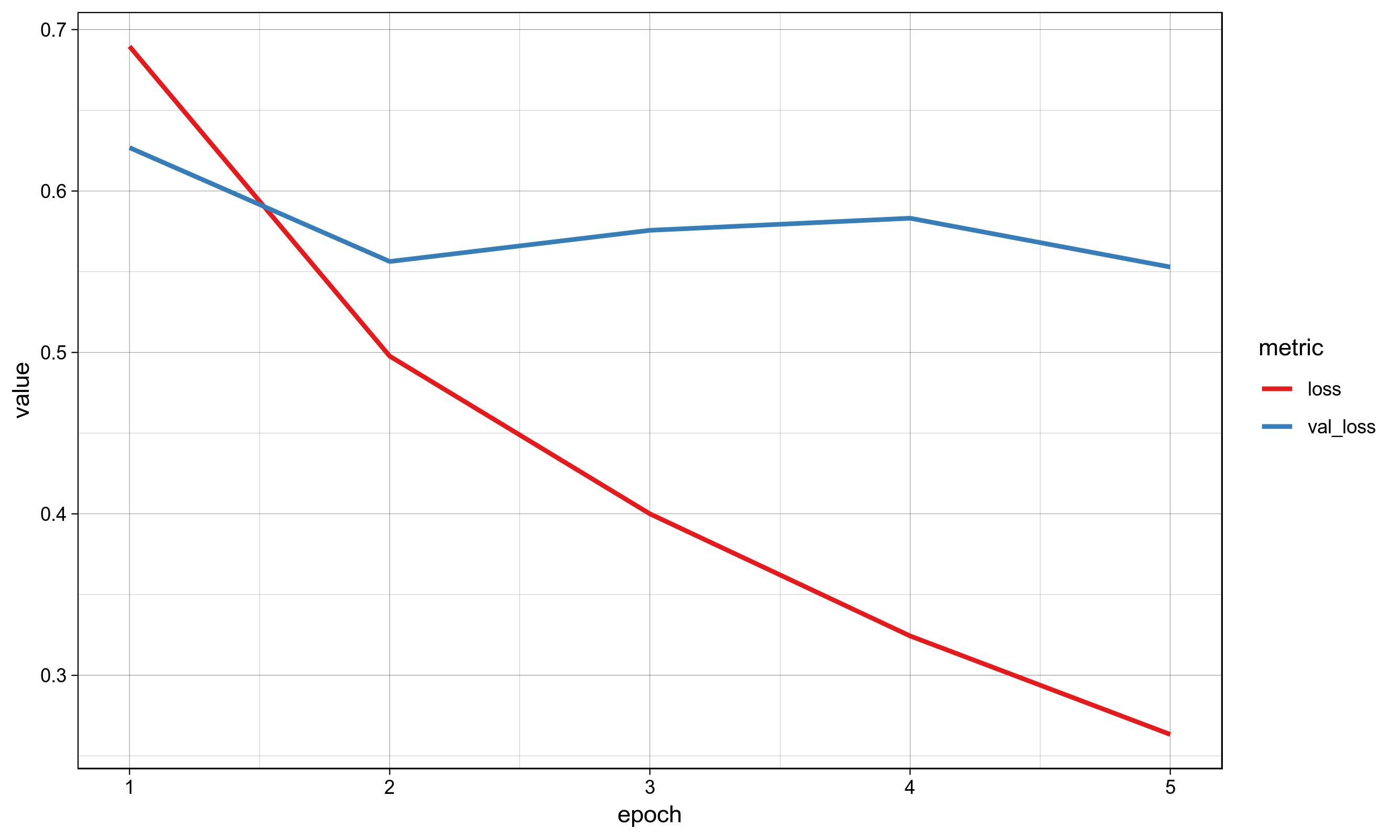
训练过程中训练精度提高,训练损失减少,但在验证精度和损失早期,随着模型的过度拟合,训练精度和损失没有提高。
我相信我有足够的训练数据,并且在两个完全连接的层上都使用了0.5的下降率,所以我该如何应对这种过度适应呢?
下面可以找到来自Keras的培训性能的模型体系结构、培训代码和可视化。
train_c3d.py
from training.c3d_model import create_c3d_sentiment_model
from ImageSentiment import load_gif_data
import numpy as np
import pathlib
from keras.callbacks import ModelCheckpoint
from keras.optimizers import Adam
def image_generator(files, batch_size):
"""
Generate batches of images for training instead of loading all images into memory
:param files:
:param batch_size:
:return:
"""
while True:
# Select files (paths/indices) for the batch
batch_paths = np.random.choice(a=files,
size=batch_size)
batch_input = []
batch_output = []
# Read in each input, perform preprocessing and get labels
for input_path in batch_paths:
input = load_gif_data(input_path)
if "pos" in input_path: # if file name contains pos
output = np.array([1, 0]) # label
elif "neg" in input_path: # if file name contains neg
output = np.array([0, 1]) # label
batch_input += [input]
batch_output += [output]
# Return a tuple of (input,output) to feed the network
batch_x = np.array(batch_input)
batch_y = np.array(batch_output)
yield (batch_x, batch_y)
model = create_c3d_sentiment_model()
print(model.summary())
model.load_weights('models/C3D_Sport1M_weights_keras_2.2.4.h5', by_name=True)
for layer in model.layers[:14]: # freeze top layers as feature extractor
layer.trainable = False
for layer in model.layers[14:]: # fine tune final layers
layer.trainable = True
train_files = [str(filepath.absolute()) for filepath in pathlib.Path('data/sample_train').glob('**/*')]
val_files = [str(filepath.absolute()) for filepath in pathlib.Path('data/sample_validation').glob('**/*')]
batch_size = 8
train_generator = image_generator(train_files, batch_size)
validation_generator = image_generator(val_files, batch_size)
model.compile(optimizer=Adam(lr=0.0001),
loss='binary_crossentropy',
metrics=['accuracy'])
mc = ModelCheckpoint('best_model.h5', monitor='val_loss', mode='min', verbose=1)
history = model.fit_generator(train_generator, validation_data=validation_generator,
steps_per_epoch=int(np.ceil(len(train_files) / batch_size)),
validation_steps=int(np.ceil(len(val_files) / batch_size)), epochs=5, shuffle=True,
callbacks=[mc])load_gif_data()
def load_gif_data(file_path):
"""
Load and process gif for input into Keras model
:param file_path:
:return: Mean normalised image in BGR format as numpy array
for more info see -> http://cs231n.github.io/neural-networks-2/
"""
im = Img(fp=file_path)
try:
im.load(limit=16, # Keras image model only requires 16 frames
first=True)
except:
print("Error loading image: " + file_path)
return
im.resize(size=(112, 112))
im.convert('RGB')
im.close()
np_frames = []
frame_index = 0
for i in range(16): # if image is less than 16 frames, repeat the frames until there are 16
frame = im.frames[frame_index]
rgb = np.array(frame)
bgr = rgb[..., ::-1]
mean = np.mean(bgr, axis=0)
np_frames.append(bgr - mean) # C3D model was originally trained on BGR, mean normalised images
# it is important that unseen images are in the same format
if frame_index == (len(im.frames) - 1):
frame_index = 0
else:
frame_index = frame_index + 1
return np.array(np_frames)模型体系结构
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1 (Conv3D) (None, 16, 112, 112, 64) 5248
_________________________________________________________________
pool1 (MaxPooling3D) (None, 16, 56, 56, 64) 0
_________________________________________________________________
conv2 (Conv3D) (None, 16, 56, 56, 128) 221312
_________________________________________________________________
pool2 (MaxPooling3D) (None, 8, 28, 28, 128) 0
_________________________________________________________________
conv3a (Conv3D) (None, 8, 28, 28, 256) 884992
_________________________________________________________________
conv3b (Conv3D) (None, 8, 28, 28, 256) 1769728
_________________________________________________________________
pool3 (MaxPooling3D) (None, 4, 14, 14, 256) 0
_________________________________________________________________
conv4a (Conv3D) (None, 4, 14, 14, 512) 3539456
_________________________________________________________________
conv4b (Conv3D) (None, 4, 14, 14, 512) 7078400
_________________________________________________________________
pool4 (MaxPooling3D) (None, 2, 7, 7, 512) 0
_________________________________________________________________
conv5a (Conv3D) (None, 2, 7, 7, 512) 7078400
_________________________________________________________________
conv5b (Conv3D) (None, 2, 7, 7, 512) 7078400
_________________________________________________________________
zeropad5 (ZeroPadding3D) (None, 2, 8, 8, 512) 0
_________________________________________________________________
pool5 (MaxPooling3D) (None, 1, 4, 4, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 8192) 0
_________________________________________________________________
fc6 (Dense) (None, 4096) 33558528
_________________________________________________________________
dropout_1 (Dropout) (None, 4096) 0
_________________________________________________________________
fc7 (Dense) (None, 4096) 16781312
_________________________________________________________________
dropout_2 (Dropout) (None, 4096) 0
_________________________________________________________________
nfc8 (Dense) (None, 2) 8194
=================================================================
Total params: 78,003,970
Trainable params: 78,003,970
Non-trainable params: 0
_________________________________________________________________
None训练可视化
回答 1
Stack Overflow用户
发布于 2019-06-20 00:54:18
我认为误差在损失函数和最后的稠密层。正如模型摘要中所提供的,最后一个稠密层是,
nfc8 (Dense) (None, 2)输出形状为( None,2),这意味着该层有2个单元。正如您前面所说的,您需要将GIF分为积极的或消极的。
GIF的分类可以是二进制分类问题,也可以是多类分类问题(有两类)。
二进制分类在最后的稠密层中只有一个单元,具有乙状结肠激活函数。但是,在这里,模型在最后一个稠密层中有两个单元。
因此,该模型是一个多类分类器,但您已经给出了binary_crossentropy的损失函数,该函数用于二进制分类器(在最后一层只有一个单元)。
因此,用categorical_crossentropy代替损失应该是可行的。或者编辑最后一个密集层并更改单元数和激活函数。
希望这能有所帮助。
https://stackoverflow.com/questions/56675919
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号