ABAP 开发避坑指南:内表类型选错,性能直接腰斩!这篇解析让你少写 3 年低效代码

ABAP 开发避坑指南:内表类型选错,性能直接腰斩!这篇解析让你少写 3 年低效代码

齐天大圣
发布于 2026-03-22 13:06:36
发布于 2026-03-22 13:06:36
声明:本文仅代表原作者观点,仅用于ERP行业应用和交流,不代表任何公司
前言:余做ABAP工作二十余载,晨兴夜寐,不敢稍微懈怠。夜半的键盘声里,消磨了青春未曾消磨少年意气;通宵的DEBUG途中,阅尽了源码经验愈发老道。
入行之初,不免有炫技之嫌,或ALV做的天花乱坠,或以懂了某个新语法而洋洋得意,等等如此不一而足,自以为得计,殊不知已入歧途。及经验世面见长,亲见数百千万行数据使那应用服务器气喘如牛,数据库汗流浃背,诸般花巧尽成累赘,方幡然醒悟——这些花拳绣腿,不过是锦上添花,若要达无上成就,性能调优方为大道。
又逢面试多位ABAP顾问,程序调优之道多未得其髓,特开一个ABAP代码调优专题,分享一二。
正文:我在面试ABAP顾问的时候通常会问这么一个问题:内表种类分为几种?各有什么使用场景?
这个问题非常的基础,主要是考察标准表、排序表和哈希表的使用,即便是刚入门的ABAP应该也能回答一二,但是恰恰相反,真正能够回答到点子上的寥寥无几,这个情况凸显了很多顾问基本功还不是太扎实。本文抛砖引玉,对内表的应用做一个大概的描述,更深的用法还需要各位自己去探索。
涉及内表性能的基本就两个操作,READ和LOOP,本质上都是在内表读取数据,少数情况下还有一个COLLECT,对内表做分组累计。
READ又分为按照INDEX和KEY读取某一条数据,按照INDEX只能是标准表和排序表支持,哈希表不能指定INDEX访问。而根据KEY访问三种内表都是可以的,日常中涉及性能问题的也是根据KEY访问的场景。
LOOP的情况比较多,如果单纯的LOOP,速度是非常快的,但是如果根据WHERE条件LOOP,性能就相差巨大了,尤其是LOOP嵌套LOOP的语句,如果没有使用合适的方案,速度能慢到让你怀疑人生。
下面是一个嵌套LOOP例子:
DATA: BEGIN OF gs_mkpf,
mblnr TYPE mkpf-mblnr,
mjahr TYPE mkpf-mjahr,
END OF gs_mkpf.
DATA: gt_mkpf LIKE TABLE OF gs_mkpf.
DATA: BEGIN OF gs_mseg,
mblnr TYPE mseg-mblnr,
mjahr TYPE mseg-mjahr,
zeile TYPE mseg-zeile,
END OF gs_mseg.
DATA: gt_mseg1 LIKE TABLE OF gs_mseg.
DATA: gt_mseg2 LIKE SORTED TABLE OF gs_mseg WITH NON-UNIQUE KEY mblnr mjahr zeile.
DATA: gt_mseg3 LIKE HASHED TABLE OF gs_mseg WITH UNIQUE KEY mblnr mjahr zeile.
DATA: t1 TYPE i,
t2 TYPE i.
DATA: num TYPE i.
SELECT mblnr mjahr INTO TABLE gt_mkpf
FROM mkpf
UP TO 1000 ROWS.
SELECT mblnr mjahr zeile INTO TABLE gt_mseg1
FROM mseg
UP TO 10000 ROWS.
gt_mseg2 = gt_mseg1.
gt_mseg3 = gt_mseg1.
GET RUN TIME FIELD t1.
CLEAR num.
LOOP AT gt_mkpf INTO gs_mkpf.
LOOP AT gt_mseg1 INTO gs_mseg
WHERE mblnr = gs_mkpf-mblnr AND
mjahr = gs_mkpf-mjahr.
num = num + 1.
ENDLOOP.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/'标准表直接LOOP', num,t1.
GET RUN TIME FIELD t1.
CLEAR num.
SORT gt_mseg1 BY mblnr mjahr.
LOOP AT gt_mkpf INTO gs_mkpf.
READ TABLE gt_mseg1 INTO gs_mseg
WITH KEY mblnr = gs_mkpf-mblnr
mjahr = gs_mkpf-mjahr
BINARY SEARCH.
IF sy-subrc = 0.
LOOP AT gt_mseg1 INTO gs_mseg FROM sy-tabix.
IF gs_mseg-mblnr NE gs_mkpf-mblnr OR
gs_mseg-mjahr NE gs_mkpf-mjahr.
EXIT.
ENDIF.
num = num + 1.
ENDLOOP.
ENDIF.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/'标准表 二分法',num,t1.
GET RUN TIME FIELD t1.
CLEAR num.
LOOP AT gt_mkpf INTO gs_mkpf.
LOOP AT gt_mseg2 INTO gs_mseg
WHERE mblnr = gs_mkpf-mblnr AND
mjahr = gs_mkpf-mjahr.
num = num + 1.
ENDLOOP.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/ '排序表直接LOOP',num,t1.
GET RUN TIME FIELD t1.
CLEAR num.
LOOP AT gt_mkpf INTO gs_mkpf.
LOOP AT gt_mseg3 INTO gs_mseg
WHERE mblnr = gs_mkpf-mblnr AND
mjahr = gs_mkpf-mjahr.
num = num + 1.
ENDLOOP.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/ '哈西表直接LOOP',num,t1.第一层LOOP有1000条数据,第二个内表10000条数据,执行结果为:
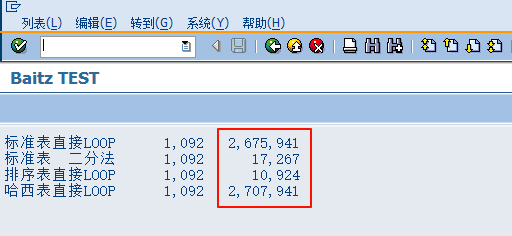
红框内为所用时间,可以看出来排序表用的时间最少,而且是遥遥领先的少,再加大两个内表的条数,分别增加到10倍条数,程序运行结果为:
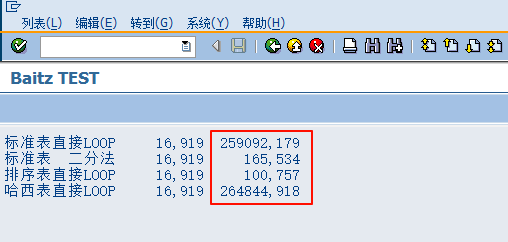
由此可以得出一个结论,在指定KEY值LOOP的时候,标准表和哈希表都非常拉胯,而用了先READ再LOOP的算法后,性能大幅度提升,如果使用了排序表,性能则进一步提升,可以看出,排序表非常适合根据KEY值的LOOP。
需要注意的是,LOOP的时候使用ASSIGN到FIELD-SYMBOLS的方法,因为省了一个复制数据的过程,性能也会有提升,但是因为这个提升的总时间并不是那么明显,所以这个方法可用可不用。
下面再看READ的例子:
DATA: BEGIN OF gs_mkpf,
mblnr TYPE mkpf-mblnr,
mjahr TYPE mkpf-mjahr,
END OF gs_mkpf.
DATA: gt_mkpf LIKE TABLE OF gs_mkpf.
DATA: gt_mkp2 LIKE SORTED TABLE OF gs_mkpf WITH NON-UNIQUE KEY mblnr mjahr.
DATA: gt_mkp3 LIKE HASHED TABLE OF gs_mkpf WITH UNIQUE KEY mblnr mjahr.
DATA: BEGIN OF gs_mseg,
mblnr TYPE mseg-mblnr,
mjahr TYPE mseg-mjahr,
zeile TYPE mseg-zeile,
END OF gs_mseg.
DATA: gt_mseg1 LIKE TABLE OF gs_mseg.
DATA: t1 TYPE i,
t2 TYPE i.
SELECT mblnr mjahr INTO TABLE gt_mkpf
FROM mkpf
UP TO 1000 ROWS.
SELECT mblnr mjahr zeile INTO TABLE gt_mseg1
FROM mseg
UP TO 10000 ROWS.
SORT gt_mkpf BY mblnr mjahr.
gt_mkp2 = gt_mkpf.
gt_mkp3 = gt_mkpf.
GET RUN TIME FIELD t1.
LOOP AT gt_mseg1 INTO gs_mseg.
READ TABLE gt_mkpf INTO gs_mkpf
WITH KEY mblnr = gs_mseg-mblnr
mjahr = gs_mseg-mjahr.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/ '标准表直接READ', t1.
GET RUN TIME FIELD t1.
LOOP AT gt_mseg1 INTO gs_mseg.
READ TABLE gt_mkpf INTO gs_mkpf
WITH KEY mblnr = gs_mseg-mblnr
mjahr = gs_mseg-mjahr
BINARY SEARCH.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/ '标准表 二分法',t1.
GET RUN TIME FIELD t1.
LOOP AT gt_mseg1 INTO gs_mseg.
READ TABLE gt_mkp2 INTO gs_mkpf
WITH TABLE KEY mblnr = gs_mseg-mblnr
mjahr = gs_mseg-mjahr.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/ '排序表直接READ',t1.
GET RUN TIME FIELD t1.
LOOP AT gt_mseg1 INTO gs_mseg.
READ TABLE gt_mkp3 INTO gs_mkpf
WITH TABLE KEY mblnr = gs_mseg-mblnr
mjahr = gs_mseg-mjahr.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/ '哈希表直接READ',t1.结果为
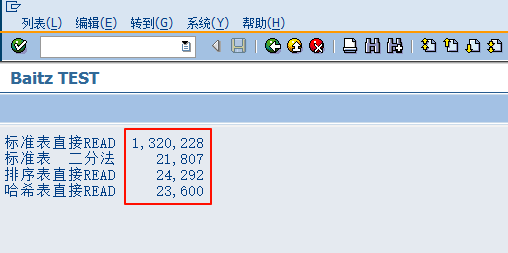
增加内表条数后再次测试:
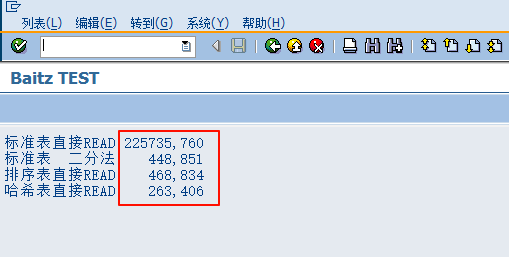
结论是标准表根据KEY访问是非常慢的,但是使用二分法就非常快了,跟排序表、哈希表性能相当,哈希表没有明显优势。但是随着内表条数的增加,哈希表的优势越来越明显,越大的内表哈希表READ就越快。
在ECC之后,SAP就支持内表的索引KEY了,也就是SORTED KEY,在READ和LOOP的时候能起到很大的作用,比如给标准表加上索引KEY,再次测试:
DATA: BEGIN OF gs_mkpf,
mblnr TYPE mkpf-mblnr,
mjahr TYPE mkpf-mjahr,
END OF gs_mkpf.
DATA: gt_mkpf LIKE TABLE OF gs_mkpf.
DATA: BEGIN OF gs_mseg,
mblnr TYPE mseg-mblnr,
mjahr TYPE mseg-mjahr,
zeile TYPE mseg-zeile,
END OF gs_mseg.
DATA: gt_mseg1 LIKE TABLE OF gs_mseg.
DATA: gt_mseg2 LIKE SORTED TABLE OF gs_mseg WITH NON-UNIQUE KEY mblnr mjahr zeile.
DATA: gt_mseg3 LIKE HASHED TABLE OF gs_mseg WITH UNIQUE KEY mblnr mjahr zeile.
DATA: gt_mseg4 LIKE TABLE OF gs_mseg WITH NON-UNIQUE SORTED KEY k1 COMPONENTS mblnr mjahr.
DATA: t1 TYPE i,
t2 TYPE i.
DATA: num TYPE i.
SELECT mblnr mjahr INTO TABLE gt_mkpf
FROM mkpf
UP TO 10000 ROWS.
SELECT mblnr mjahr zeile INTO TABLE gt_mseg1
FROM mseg
UP TO 100000 ROWS.
gt_mseg2 = gt_mseg1.
gt_mseg3 = gt_mseg1.
gt_mseg4 = gt_mseg1.
GET RUN TIME FIELD t1.
CLEAR num.
LOOP AT gt_mkpf INTO gs_mkpf.
LOOP AT gt_mseg1 INTO gs_mseg
WHERE mblnr = gs_mkpf-mblnr AND
mjahr = gs_mkpf-mjahr.
num = num + 1.
ENDLOOP.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/'标准表直接LOOP', num,t1.
GET RUN TIME FIELD t1.
CLEAR num.
SORT gt_mseg1 BY mblnr mjahr.
LOOP AT gt_mkpf INTO gs_mkpf.
READ TABLE gt_mseg1 INTO gs_mseg
WITH KEY mblnr = gs_mkpf-mblnr
mjahr = gs_mkpf-mjahr
BINARY SEARCH.
IF sy-subrc = 0.
LOOP AT gt_mseg1 INTO gs_mseg FROM sy-tabix.
IF gs_mseg-mblnr NE gs_mkpf-mblnr OR
gs_mseg-mjahr NE gs_mkpf-mjahr.
EXIT.
ENDIF.
num = num + 1.
ENDLOOP.
ENDIF.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/'标准表 二分法',num,t1.
GET RUN TIME FIELD t1.
CLEAR num.
LOOP AT gt_mkpf INTO gs_mkpf.
LOOP AT gt_mseg2 INTO gs_mseg
WHERE mblnr = gs_mkpf-mblnr AND
mjahr = gs_mkpf-mjahr.
num = num + 1.
ENDLOOP.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/ '排序表直接LOOP',num,t1.
GET RUN TIME FIELD t1.
CLEAR num.
LOOP AT gt_mkpf INTO gs_mkpf.
LOOP AT gt_mseg3 INTO gs_mseg
WHERE mblnr = gs_mkpf-mblnr AND
mjahr = gs_mkpf-mjahr.
num = num + 1.
ENDLOOP.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/ '哈西表直接LOOP',num,t1.
GET RUN TIME FIELD t1.
CLEAR num.
LOOP AT gt_mkpf INTO gs_mkpf.
LOOP AT gt_mseg4 USING KEY k1 INTO gs_mseg
WHERE mblnr = gs_mkpf-mblnr AND
mjahr = gs_mkpf-mjahr.
num = num + 1.
ENDLOOP.
ENDLOOP.
GET RUN TIME FIELD t2.
t1 = t2 - t1.
WRITE :/ 'SORTED KEY LOOP',num,t1.
结果为:
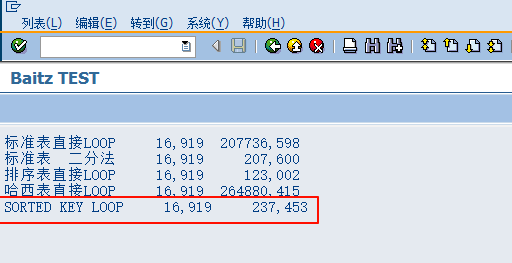
可以看出来跟二分法性能接近,但是这个方法的使用有很大的坑,比如LOOP或者READ的时候,SY-TABIX的值并不是内表的当前序号,而是KEY的当前序号,还有其他一些坑,所以这个方法使用的时候要非常慎重,一不小心就出错了。
结论:根据KEY访问的时候,标准表如果直接READ和LOOP,性能都非常拉胯,但是可以使用二分法或者第二索引来提高性能。排序表本身就是排好序的,系统会自动使用最优的算法来读取,在READ和LOOP的时候性能都比较好。哈希表使用限制比较多,要求必须有唯一KEY,但是在数据巨大时候,READ速度是最快的。使用FIELD-SYMBOLS能提高一部分性能,但是会增加程序的复杂性,属于可用可不用,就看如何取舍了。
COLLECT没有测试,但是有些顾问在使用过程中发现标准表COLLECT会非常快,明显不像是标准表能够达到的速度,其实,系统是根据COLLECT条件创建一个哈希表进行COLLECT操作,完事儿再把结果转移到标准表。
另外,标准表可以INSERT或者APPEND,排序表和哈希表添加新的数据必须使用INSERT TABLE关键字。
版权归原作者所有,如有侵权请联系删除。
免责声明:本文所用视频、图片、文字如涉及作品版权问题,请第一时间告知,我们将根据您提供的证明材料确认版权并按国家标准支付稿酬或立即删除内容!本文内容为原作者观点,并不代表本公众号赞同其观点和对其真实性负责。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号