Prefill Decode分离部署大模型(dynamo框架)

Prefill Decode分离部署大模型(dynamo框架)

Michael阿明
发布于 2026-03-25 13:54:11
发布于 2026-03-25 13:54:11
文章目录
- 构建容器
- 启动必要组件
- 为什么要PD分离
- 编辑配置
- 启动服务
- 调用服务
- benchmark测试
参考:https://github.com/ai-dynamo/dynamo
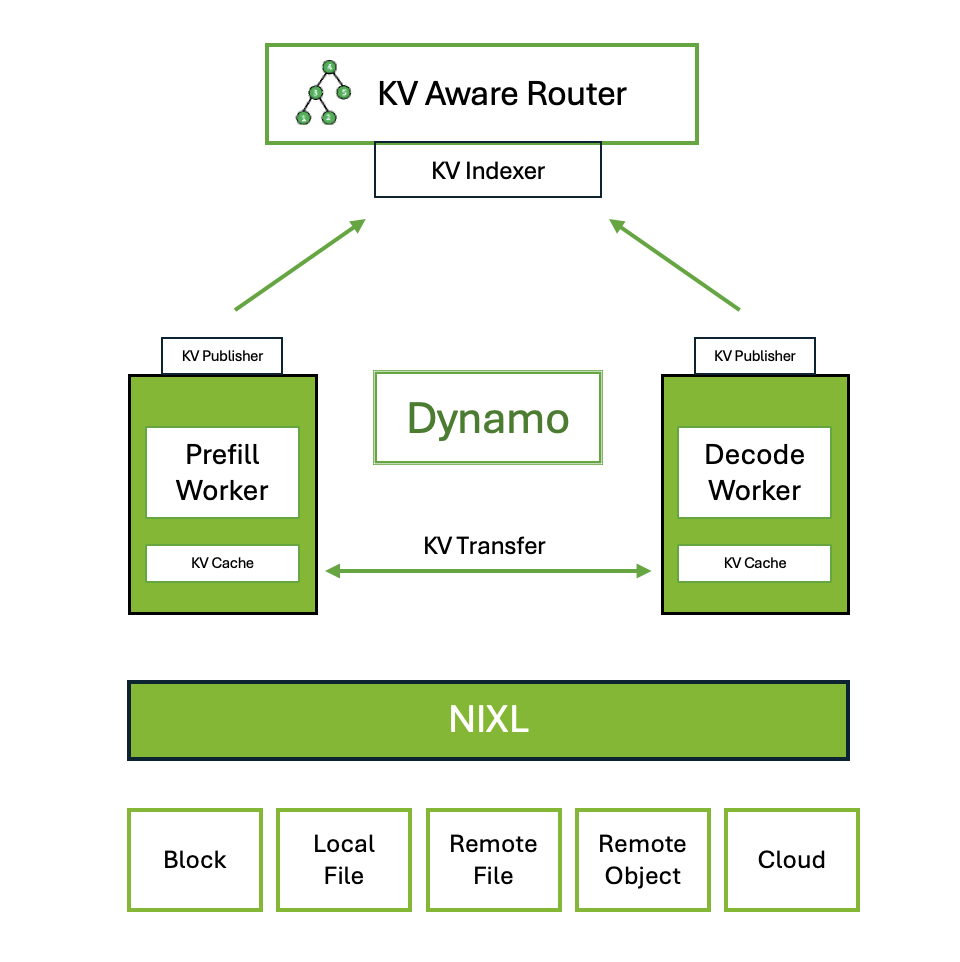
在这里插入图片描述
NVIDIA Dynamo 是一个高吞吐量、低延迟的推理框架,旨在为多节点分布式环境中的生成式 AI 和推理模型提供服务。Dynamo 设计为与推理引擎无关(支持 TRT-LLM、vLLM、SGLang)
1. 构建容器
dynamo 0.2 vllm0.8.4
git clone https://github.com/ai-dynamo/dynamo.git
./container/build.sh --framework vllm
2. 启动必要组件
# docker-compose -f deploy/metrics/docker-compose.yml up -d
[+] Running 3/3
✔ Network metrics_default Created 0.1s
✔ Container metrics-nats-server-1 Started 0.7s
✔ Container metrics-etcd-server-1 Started
3. 为什么要PD分离
LLM(大语言模型)部署中采用Prefill(预填充)与Decode(解码)分离的核心原因在于两者在计算和通信特征上的显著差异,这种差异导致统一部署时难以高效利用资源并满足性能目标。
- 计算与内存需求的差异 Prefill阶段需要处理用户输入的全部上下文,属于计算密集型任务,需大量并行计算资源(如高算力GPU)快速生成初始结果,其性能通常由首Token时延(TTFT)衡量。 Decode阶段需逐个生成输出Token并维护KV Cache(键值缓存),属于内存密集型任务,更依赖显存容量和带宽以支持多轮迭代。若统一部署,两者对硬件资源的需求会产生冲突,导致资源利用率低下。
- 资源优化与弹性扩展 分离部署允许针对不同阶段配置差异化的硬件资源。例如,Prefill可部署在高算力GPU集群上加速计算,Decode则使用大显存GPU以降低内存压力。此外,两阶段的负载波动不同(如用户请求突发时Prefill压力增大),分离架构可独立扩展各自资源,避免资源浪费或瓶颈。
- 性能与吞吐量提升 通过解耦两阶段,系统可分别优化其并行策略和调度逻辑。通过动态分配GPU资源,在相同硬件条件下实现了比传统部署更高的吞吐量和服务质量(如更低延迟)。分离后还能减少通信开销,避免Decode阶段因等待Prefill完成而空转。
- 避免优化目标冲突 Prefill需优先降低首Token时延(TTFT),而Decode关注整体生成速度(ThroughPUT)。若合并部署,两者的优化目标可能导致调度策略互相干扰,分离后可分别针对阶段特性设计最优方案。
4. 编辑配置
进入构建好的容器
cd examples/llm/
vim configs/disagg.yaml
配置示例:4*A10,一个prefill实例、一个decode实例,各占两张卡
Common:
model: /mnt/DeepSeek-R1-Distill-Qwen-14B
block-size: 64
max-model-len: 10240
kv-transfer-config: '{"kv_connector":"DynamoNixlConnector"}'
Frontend:
served_model_name: RAG_LLM
endpoint: dynamo.Processor.chat/completions
port: 8009
Processor:
router: round-robin
common-configs: [model, block-size]
VllmWorker:
remote-prefill: true
conditional-disagg: true
max-local-prefill-length: 1
max-prefill-queue-size: 10
max-num-seqs: 20
enable-prefix-caching: true
tensor-parallel-size: 2
ServiceArgs:
workers: 1
resources:
gpu: 2
common-configs: [model, block-size, max-model-len, kv-transfer-config]
PrefillWorker:
max-num-batched-tokens: 32768
tensor-parallel-size: 2
enable-prefix-caching: true
max-num-seqs: 20
ServiceArgs:
workers: 1
resources:
gpu: 2
common-configs: [model, block-size, max-model-len, kv-transfer-config]
5. 启动服务
在容器内
dynamo serve graphs.disagg:Frontend -f configs/disagg.yaml
输出日志:
2025-06-15T03:01:53.826Z INFO serve.serve: Running dynamo serve with service configs {'Common': {'model': '/mnt/DeepSeek-R1-Distill-Qwen-14B', 'block-size': 64, 'max-model-len': 10240, 'kv-transfer-config': '{"kv_connector":"DynamoNixlConnector"}'}, 'Frontend': {'served_model_name': 'RAG_LLM', 'endpoint': 'dynamo.Processor.chat/completions', 'port': 8009}, 'Processor': {'router': 'round-robin', 'common-configs': ['model', 'block-size']}, 'VllmWorker': {'remote-prefill': True, 'conditional-disagg': True, 'max-local-prefill-length': 1, 'max-prefill-queue-size': 10, 'max-num-seqs': 20, 'enable-prefix-caching': True, 'tensor-parallel-size': 2, 'ServiceArgs': {'workers': 1, 'resources': {'gpu': 2}}, 'common-configs': ['model', 'block-size', 'max-model-len', 'kv-transfer-config']}, 'PrefillWorker': {'max-num-batched-tokens': 32768, 'tensor-parallel-size': 2, 'enable-prefix-caching': True, 'max-num-seqs': 20, 'ServiceArgs': {'workers': 1, 'resources': {'gpu': 2}}, 'common-configs': ['model', 'block-size', 'max-model-len', 'kv-transfer-config']}}
2025-06-15T03:01:53.826Z INFO loader.find_and_load_service: Loading service from import string: graphs.disagg:Frontend
2025-06-15T03:01:53.826Z INFO loader.find_and_load_service: Working directory: .
2025-06-15T03:01:53.826Z INFO loader.find_and_load_service: Changing working directory to: /workspace/examples/llm
2025-06-15T03:01:53.826Z INFO loader.find_and_load_service: Adding /workspace/examples/llm to sys.path
2025-06-15T03:01:53.826Z INFO loader._do_import: Parsed import string - path: graphs.disagg, attributes: Frontend
2025-06-15T03:01:53.826Z INFO loader._do_import: Importing from module name: graphs.disagg
2025-06-15T03:01:53.826Z INFO loader._do_import: Attempting to import module: graphs.disagg
2025-06-15T03:01:59.573Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:01:59.575Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:01:59.577Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:01:59.580Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:01:59.582Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:01:59.585Z INFO __init__.resolve_current_platform_cls_qualname: Automatically detected platform cuda.
2025-06-15T03:02:00.044Z INFO nixl: NIXL is available
2025-06-15T03:02:01.314Z INFO loader._do_import: Navigating attributes: Frontend
2025-06-15T03:02:01.314Z INFO loader._do_import: Getting attribute: Frontend
2025-06-15T03:02:01.314Z INFO loader.find_and_load_service: Removing /workspace/examples/llm from sys.path
2025-06-15T03:02:01.314Z INFO loader.find_and_load_service: Restoring working directory to: /workspace/examples/llm
2025-06-15T03:02:01.314Z INFO serve.serve: Loaded service: Frontend
2025-06-15T03:02:01.314Z INFO serve.serve: Dependencies: ['Processor', 'VllmWorker']
╭───────────────── Dynamo Serve ──────────────────╮
│ Starting Dynamo service: graphs.disagg:Frontend │
╰─────────────────────────────────────────────────╯
2025-06-15T03:02:01.347Z INFO loader.find_and_load_service: Loading service from import string: graphs.disagg:Frontend
2025-06-15T03:02:01.347Z INFO loader.find_and_load_service: Working directory: .
2025-06-15T03:02:01.347Z INFO loader.find_and_load_service: Changing working directory to: /workspace/examples/llm
2025-06-15T03:02:01.347Z INFO loader.find_and_load_service: Adding /workspace/examples/llm to sys.path
2025-06-15T03:02:01.347Z INFO loader._do_import: Parsed import string - path: graphs.disagg, attributes: Frontend
2025-06-15T03:02:01.347Z INFO loader._do_import: Importing from module name: graphs.disagg
2025-06-15T03:02:01.347Z INFO loader._do_import: Attempting to import module: graphs.disagg
2025-06-15T03:02:01.347Z INFO loader._do_import: Navigating attributes: Frontend
2025-06-15T03:02:01.347Z INFO loader._do_import: Getting attribute: Frontend
2025-06-15T03:02:01.347Z INFO loader.find_and_load_service: Removing /workspace/examples/llm from sys.path
2025-06-15T03:02:01.347Z INFO loader.find_and_load_service: Restoring working directory to: /workspace/examples/llm
2025-06-15T03:02:01.400Z INFO resource._discover_gpus: Discovered 4 GPUs
2025-06-15T03:02:01.464Z INFO resource._discover_gpus: Discovered 4 GPUs
2025-06-15T03:02:01.464Z INFO allocator.get_resource_envs: Getting resource envs for service Frontend
2025-06-15T03:02:01.464Z INFO allocator.get_resource_envs: Using configured worker count: 1
2025-06-15T03:02:01.465Z INFO allocator.get_resource_envs: Final resource allocation - workers: 1, envs: []
2025-06-15T03:02:01.465Z INFO allocator.get_resource_envs: Getting resource envs for service Processor
2025-06-15T03:02:01.465Z INFO allocator.get_resource_envs: Using configured worker count: 1
2025-06-15T03:02:01.465Z INFO allocator.get_resource_envs: Final resource allocation - workers: 1, envs: []
2025-06-15T03:02:01.468Z INFO serving.create_dynamo_watcher: Created watcher for Processor's in the dynamo namespace
2025-06-15T03:02:01.468Z INFO allocator.get_resource_envs: Getting resource envs for service VllmWorker
2025-06-15T03:02:01.468Z INFO allocator.get_resource_envs: GPU requirement found: 2
2025-06-15T03:02:01.468Z INFO allocator.get_resource_envs: Using configured worker count: 1
2025-06-15T03:02:01.468Z INFO allocator.get_resource_envs: GPU allocation enabled
2025-06-15T03:02:01.468Z INFO allocator.get_resource_envs: Local deployment detected. Allocating GPUs for 1 workers of 'VllmWorker'
2025-06-15T03:02:01.476Z INFO allocator.get_resource_envs: GPU 0 (NVIDIA A10): Memory: 22.0GB free / 22.5GB total, Utilization: 0%, Temperature: 43°C
2025-06-15T03:02:01.476Z INFO allocator.get_resource_envs: GPU 1 (NVIDIA A10): Memory: 22.0GB free / 22.5GB total, Utilization: 0%, Temperature: 42°C
2025-06-15T03:02:01.476Z INFO allocator.get_resource_envs: Final resource allocation - workers: 1, envs: [{'CUDA_VISIBLE_DEVICES': '0,1'}]
2025-06-15T03:02:01.476Z INFO serving.create_dynamo_watcher: Created watcher for VllmWorker's in the dynamo namespace
2025-06-15T03:02:01.476Z INFO allocator.get_resource_envs: Getting resource envs for service PrefillWorker
2025-06-15T03:02:01.476Z INFO allocator.get_resource_envs: GPU requirement found: 2
2025-06-15T03:02:01.476Z INFO allocator.get_resource_envs: Using configured worker count: 1
2025-06-15T03:02:01.476Z INFO allocator.get_resource_envs: GPU allocation enabled
2025-06-15T03:02:01.476Z INFO allocator.get_resource_envs: Local deployment detected. Allocating GPUs for 1 workers of 'PrefillWorker'
2025-06-15T03:02:01.483Z INFO allocator.get_resource_envs: GPU 2 (NVIDIA A10): Memory: 22.0GB free / 22.5GB total, Utilization: 0%, Temperature: 35°C
2025-06-15T03:02:01.483Z INFO allocator.get_resource_envs: GPU 3 (NVIDIA A10): Memory: 22.0GB free / 22.5GB total, Utilization: 0%, Temperature: 39°C
2025-06-15T03:02:01.483Z INFO allocator.get_resource_envs: Final resource allocation - workers: 1, envs: [{'CUDA_VISIBLE_DEVICES': '2,3'}]
2025-06-15T03:02:01.484Z INFO serving.create_dynamo_watcher: Created watcher for PrefillWorker's in the dynamo namespace
2025-06-15T03:02:01.485Z INFO serving.serve_dynamo_graph: Created watcher for Frontend with 1 workers in the dynamo namespace
2025-06-15T03:02:01.498Z INFO arbiter._ensure_ioloop: Installing handle_callback_exception to loop
2025-06-15T03:02:01.498Z INFO sighandler.__init__: Registering signals...
2025-06-15T03:02:01.500Z INFO arbiter.start: Starting master on pid 18246
2025-06-15T03:02:01.505Z INFO arbiter.initialize: sockets started
2025-06-15T03:02:01.540Z INFO arbiter.start: Arbiter now waiting for commands
2025-06-15T03:02:01.540Z INFO watcher._start: dynamo_Processor started
2025-06-15T03:02:01.568Z INFO watcher._start: dynamo_VllmWorker started
2025-06-15T03:02:01.595Z INFO watcher._start: dynamo_PrefillWorker started
2025-06-15T03:02:01.623Z INFO watcher._start: dynamo_Frontend started
2025-06-15T03:02:01.624Z INFO serving.<lambda>: Starting Dynamo Service Frontend (Press CTRL+C to quit)
2025-06-15T03:02:05.526Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.526Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.526Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.527Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.527Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.527Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.535Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.535Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.535Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.540Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.541Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.541Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.542Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.542Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.542Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.545Z INFO __init__.resolve_current_platform_cls_qualname: Automatically detected platform cuda.
2025-06-15T03:02:05.545Z INFO __init__.resolve_current_platform_cls_qualname: Automatically detected platform cuda.
2025-06-15T03:02:05.545Z INFO __init__.resolve_current_platform_cls_qualname: Automatically detected platform cuda.
2025-06-15T03:02:05.604Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.606Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.609Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.630Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.632Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:05.635Z INFO __init__.resolve_current_platform_cls_qualname: Automatically detected platform cuda.
2025-06-15T03:02:05.982Z INFO nixl: NIXL is available
2025-06-15T03:02:05.985Z INFO nixl: NIXL is available
2025-06-15T03:02:06.002Z INFO nixl: NIXL is available
2025-06-15T03:02:06.040Z INFO nixl: NIXL is available
2025-06-15T03:02:07.004Z INFO serve_dynamo.worker: [PrefillWorker:1] Registering component dynamo/PrefillWorker
2025-06-15T03:02:07.004Z INFO serve_dynamo.worker: [VllmWorker:1] Registering component dynamo/VllmWorker
2025-06-15T03:02:07.005Z INFO _core: created custom lease: Lease { id: 7587887483020983089, cancel_token: CancellationToken { is_cancelled: false } }
2025-06-15T03:02:07.006Z INFO _core: created custom lease: Lease { id: 7587887483020983091, cancel_token: CancellationToken { is_cancelled: false } }
2025-06-15T03:02:07.006Z INFO serve_dynamo.worker: [PrefillWorker:1] Created PrefillWorker component with custom lease id 7587887483020983089
2025-06-15T03:02:07.006Z INFO config.as_args: [PrefillWorker:1] Running PrefillWorker with args=['--model', '/mnt/DeepSeek-R1-Distill-Qwen-14B', '--block-size', '64', '--max-model-len', '10240', '--kv-transfer-config', '{"kv_connector":"DynamoNixlConnector"}', '--max-num-batched-tokens', '32768', '--tensor-parallel-size', '2', '--enable-prefix-caching', '--max-num-seqs', '20']
2025-06-15T03:02:07.009Z INFO serve_dynamo.worker: [VllmWorker:1] Created VllmWorker component with custom lease id 7587887483020983091
2025-06-15T03:02:07.009Z INFO config.as_args: [VllmWorker:1] Running VllmWorker with args=['--model', '/mnt/DeepSeek-R1-Distill-Qwen-14B', '--block-size', '64', '--max-model-len', '10240', '--kv-transfer-config', '{"kv_connector":"DynamoNixlConnector"}', '--remote-prefill', '--conditional-disagg', '--max-local-prefill-length', '1', '--max-prefill-queue-size', '10', '--max-num-seqs', '20', '--enable-prefix-caching', '--tensor-parallel-size', '2']
2025-06-15T03:02:07.049Z INFO serve_dynamo.worker: [Processor:1] Registering component dynamo/Processor
2025-06-15T03:02:07.052Z INFO serve_dynamo.worker: [Processor:1] Created Processor component
2025-06-15T03:02:07.052Z INFO config.as_args: [Processor:1] Running Processor with args=['--model', '/mnt/DeepSeek-R1-Distill-Qwen-14B', '--block-size', '64', '--router', 'round-robin']
2025-06-15T03:02:07.078Z INFO prefill_worker.__init__: [PrefillWorker:1] Chunked prefill is not supported yet, setting to False
2025-06-15T03:02:07.078Z INFO prefill_worker.__init__: [PrefillWorker:1] Async output processing is not supported yet, setting to True
2025-06-15T03:02:07.078Z INFO prefill_worker.__init__: [PrefillWorker:1] Prefill must be done eagerly, setting to True
2025-06-15T03:02:07.078Z INFO prefill_worker.__init__: [PrefillWorker:1] Prefix caching is not supported yet in prefill worker, setting to False
2025-06-15T03:02:07.080Z INFO worker.__init__: [VllmWorker:1] Prefill queue: nats://localhost:4222:vllm
2025-06-15T03:02:07.080Z INFO worker.__init__: [VllmWorker:1] Chunked prefill is not supported yet, setting to False
2025-06-15T03:02:07.080Z INFO worker.__init__: [VllmWorker:1] Preemption mode is not supported yet, setting to swap
chat model RAG_LLM removed from the public namespace: public
Added new chat model RAG_LLM
+------------+------------+-----------+-----------+------------------+
| MODEL TYPE | MODEL NAME | NAMESPACE | COMPONENT | ENDPOINT |
+------------+------------+-----------+-----------+------------------+
| chat | RAG_LLM | dynamo | Processor | chat/completions |
+------------+------------+-----------+-----------+------------------+
2025-06-15T03:02:09.096Z INFO frontend.start_http_server: [Frontend:1] Starting HTTP server
2025-06-15T03:02:09.097Z WARN serve_dynamo.web_worker: [Frontend:1] No API routes found, not starting FastAPI server
2025-06-15T03:02:09.098Z INFO serve_dynamo.web_worker: [Frontend:1] Service is running, press Ctrl+C to stop
2025-06-15T03:02:09.122Z INFO dynamo_llm::http::service::service_v2: Starting HTTP service on: 0.0.0.0:8009 address="0.0.0.0:8009"
2025-06-15T03:02:09.123Z INFO dynamo_llm::http::service::discovery: load_mdc did not complete err=Missing ModelDeploymentCard in etcd under key rag_llm
2025-06-15T03:02:09.123Z INFO dynamo_llm::http::service::discovery: added model model_name="RAG_LLM"
2025-06-15T03:02:14.183Z INFO config._resolve_task: This model supports multiple tasks: {'generate', 'reward', 'classify', 'embed', 'score'}. Defaulting to 'generate'.
2025-06-15T03:02:14.237Z INFO config._resolve_task: This model supports multiple tasks: {'generate', 'reward', 'score', 'classify', 'embed'}. Defaulting to 'generate'.
2025-06-15T03:02:14.246Z INFO config.__post_init__: Defaulting to use mp for distributed inference
2025-06-15T03:02:14.253Z INFO config._resolve_task: This model supports multiple tasks: {'classify', 'reward', 'embed', 'score', 'generate'}. Defaulting to 'generate'.
2025-06-15T03:02:14.259Z INFO api_server.build_async_engine_client_from_engine_args: Started engine process with PID 18914
2025-06-15T03:02:14.296Z INFO config.__post_init__: Defaulting to use mp for distributed inference
2025-06-15T03:02:14.308Z INFO api_server.build_async_engine_client_from_engine_args: Started engine process with PID 18917
2025-06-15T03:02:14.667Z WARN config.get_diff_sampling_param: Default sampling parameters have been overridden by the model's Hugging Face generation config recommended from the model creator. If this is not intended, please relaunch vLLM instance with `--generation-config vllm`.
2025-06-15T03:02:14.667Z INFO serving_chat.__init__: Using default chat sampling params from model: {'temperature': 0.6, 'top_p': 0.95}
2025-06-15T03:02:14.669Z INFO serving_completion.__init__: Using default completion sampling params from model: {'temperature': 0.6, 'top_p': 0.95}
Processor init: round-robin
2025-06-15T03:02:18.190Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.191Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.194Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.198Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.200Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.202Z INFO __init__.resolve_current_platform_cls_qualname: Automatically detected platform cuda.
2025-06-15T03:02:18.255Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.256Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.259Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.263Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.264Z WARN __init__.vllm_version_matches_substr: Using ai_dynamo_vllm
2025-06-15T03:02:18.266Z INFO __init__.resolve_current_platform_cls_qualname: Automatically detected platform cuda.
2025-06-15T03:02:18.554Z INFO nixl: NIXL is available
2025-06-15T03:02:18.605Z INFO nixl: NIXL is available
2025-06-15T03:02:19.482Z INFO llm_engine.__init__: Initializing a V0 LLM engine (v0.8.4) with config: model='/mnt/DeepSeek-R1-Distill-Qwen-14B', speculative_config=None, tokenizer='/mnt/DeepSeek-R1-Distill-Qwen-14B', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=10240, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=2, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=True, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=/mnt/DeepSeek-R1-Distill-Qwen-14B, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=False, chunked_prefill_enabled=False, use_async_output_proc=False, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[],"max_capture_size":0}, use_cached_outputs=True,
2025-06-15T03:02:19.596Z INFO llm_engine.__init__: Initializing a V0 LLM engine (v0.8.4) with config: model='/mnt/DeepSeek-R1-Distill-Qwen-14B', speculative_config=None, tokenizer='/mnt/DeepSeek-R1-Distill-Qwen-14B', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, override_neuron_config=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=10240, download_dir=None, load_format=LoadFormat.AUTO, tensor_parallel_size=2, pipeline_parallel_size=1, disable_custom_all_reduce=False, quantization=None, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(guided_decoding_backend='xgrammar', reasoning_backend=None), observability_config=ObservabilityConfig(show_hidden_metrics=False, otlp_traces_endpoint=None, collect_model_forward_time=False, collect_model_execute_time=False), seed=None, served_model_name=/mnt/DeepSeek-R1-Distill-Qwen-14B, num_scheduler_steps=1, multi_step_stream_outputs=True, enable_prefix_caching=True, chunked_prefill_enabled=False, use_async_output_proc=True, disable_mm_preprocessor_cache=False, mm_processor_kwargs=None, pooler_config=None, compilation_config={"splitting_ops":[],"compile_sizes":[],"cudagraph_capture_sizes":[24,16,8,4,2,1],"max_capture_size":24}, use_cached_outputs=True,
2025-06-15T03:02:20.018Z WARN multiproc_worker_utils.set_multiprocessing_worker_envs: Reducing Torch parallelism from 32 threads to 1 to avoid unnecessary CPU contention. Set OMP_NUM_THREADS in the external environment to tune this value as needed.
2025-06-15T03:02:20.035Z INFO multiproc_worker_utils._run_worker_process: Worker ready; awaiting tasks
2025-06-15T03:02:20.143Z WARN multiproc_worker_utils.set_multiprocessing_worker_envs: Reducing Torch parallelism from 32 threads to 1 to avoid unnecessary CPU contention. Set OMP_NUM_THREADS in the external environment to tune this value as needed.
2025-06-15T03:02:20.167Z INFO multiproc_worker_utils._run_worker_process: Worker ready; awaiting tasks
2025-06-15T03:02:21.142Z INFO cuda.get_attn_backend_cls: Using Flash Attention backend.
2025-06-15T03:02:21.147Z INFO cuda.get_attn_backend_cls: Using Flash Attention backend.
2025-06-15T03:02:21.242Z INFO cuda.get_attn_backend_cls: Using Flash Attention backend.
2025-06-15T03:02:21.252Z INFO cuda.get_attn_backend_cls: Using Flash Attention backend.
[rank1]:[W616 03:02:22.304683185 ProcessGroupGloo.cpp:727] Warning: Unable to resolve hostname to a (local) address. Using the loopback address as fallback. Manually set the network interface to bind to with GLOO_SOCKET_IFNAME. (function operator())
[rank0]:[W616 03:02:22.304698310 ProcessGroupGloo.cpp:727] Warning: Unable to resolve hostname to a (local) address. Using the loopback address as fallback. Manually set the network interface to bind to with GLOO_SOCKET_IFNAME. (function operator())
[rank1]:[W616 03:02:22.317179397 ProcessGroupGloo.cpp:727] Warning: Unable to resolve hostname to a (local) address. Using the loopback address as fallback. Manually set the network interface to bind to with GLOO_SOCKET_IFNAME. (function operator())
[rank0]:[W616 03:02:22.318167474 ProcessGroupGloo.cpp:727] Warning: Unable to resolve hostname to a (local) address. Using the loopback address as fallback. Manually set the network interface to bind to with GLOO_SOCKET_IFNAME. (function operator())
2025-06-15T03:02:22.844Z INFO utils.find_nccl_library: Found nccl from library libnccl.so.2
2025-06-15T03:02:22.844Z INFO pynccl.__init__: vLLM is using nccl==2.21.5
2025-06-15T03:02:22.848Z INFO utils.find_nccl_library: Found nccl from library libnccl.so.2
2025-06-15T03:02:22.848Z INFO pynccl.__init__: vLLM is using nccl==2.21.5
2025-06-15T03:02:22.877Z INFO utils.find_nccl_library: Found nccl from library libnccl.so.2
2025-06-15T03:02:22.877Z INFO pynccl.__init__: vLLM is using nccl==2.21.5
2025-06-15T03:02:22.880Z INFO utils.find_nccl_library: Found nccl from library libnccl.so.2
2025-06-15T03:02:22.881Z INFO pynccl.__init__: vLLM is using nccl==2.21.5
2025-06-15T03:02:23.256Z INFO custom_all_reduce_utils.gpu_p2p_access_check: reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1.json
2025-06-15T03:02:23.256Z INFO custom_all_reduce_utils.gpu_p2p_access_check: reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_0,1.json
2025-06-15T03:02:23.267Z INFO shm_broadcast.__init__: vLLM message queue communication handle: Handle(local_reader_ranks=[1], buffer_handle=(1, 4194304, 6, 'psm_e59a99d1'), local_subscribe_addr='ipc:///tmp/b9f5b6e0-96c5-4cc6-8dbd-037a8397fdad', remote_subscribe_addr=None, remote_addr_ipv6=False)
2025-06-15T03:02:23.285Z INFO custom_all_reduce_utils.gpu_p2p_access_check: reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_2,3.json
2025-06-15T03:02:23.285Z INFO custom_all_reduce_utils.gpu_p2p_access_check: reading GPU P2P access cache from /root/.cache/vllm/gpu_p2p_access_cache_for_2,3.json
2025-06-15T03:02:23.303Z INFO shm_broadcast.__init__: vLLM message queue communication handle: Handle(local_reader_ranks=[1], buffer_handle=(1, 4194304, 6, 'psm_230a4844'), local_subscribe_addr='ipc:///tmp/7830ef6b-f562-41e5-8549-7fe17d2cfd8a', remote_subscribe_addr=None, remote_addr_ipv6=False)
2025-06-15T03:02:23.318Z INFO parallel_state.initialize_model_parallel: rank 0 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 0
2025-06-15T03:02:23.328Z INFO parallel_state.initialize_model_parallel: rank 0 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 0
2025-06-15T03:02:23.395Z INFO parallel_state.initialize_model_parallel: rank 1 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 1
2025-06-15T03:02:23.396Z INFO model_runner.load_model: Starting to load model /mnt/DeepSeek-R1-Distill-Qwen-14B...
2025-06-15T03:02:23.398Z INFO model_runner.load_model: Starting to load model /mnt/DeepSeek-R1-Distill-Qwen-14B...
2025-06-15T03:02:23.408Z INFO parallel_state.initialize_model_parallel: rank 1 in world size 2 is assigned as DP rank 0, PP rank 0, TP rank 1
2025-06-15T03:02:23.409Z INFO model_runner.load_model: Starting to load model /mnt/DeepSeek-R1-Distill-Qwen-14B...
2025-06-15T03:02:23.410Z INFO model_runner.load_model: Starting to load model /mnt/DeepSeek-R1-Distill-Qwen-14B...
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 0% Completed | 0/4 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 25% Completed | 1/4 [00:18<00:56, 18.74s/it]
Loading safetensors checkpoint shards: 25% Completed | 1/4 [00:18<00:56, 18.72s/it]
Loading safetensors checkpoint shards: 50% Completed | 2/4 [00:43<00:44, 22.34s/it]
Loading safetensors checkpoint shards: 50% Completed | 2/4 [00:43<00:44, 22.35s/it]
Loading safetensors checkpoint shards: 75% Completed | 3/4 [01:02<00:20, 20.72s/it]
Loading safetensors checkpoint shards: 75% Completed | 3/4 [01:02<00:20, 20.73s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [01:08<00:00, 15.02s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [01:08<00:00, 15.02s/it]
Loading safetensors checkpoint shards: 100% Completed | 4/4 [01:08<00:00, 17.17s/it]
2025-06-15T03:03:32.295Z INFO loader.load_model: Loading weights took 68.73 seconds
2025-06-15T03:03:32.316Z INFO loader.load_model: Loading weights took 68.74 seconds
2025-06-15T03:03:32.349Z INFO loader.load_model: Loading weights took 68.80 seconds
2025-06-15T03:03:32.352Z INFO loader.load_model: Loading weights took 68.79 seconds
2025-06-15T03:03:32.545Z INFO model_runner.load_model: Model loading took 13.9477 GiB and 68.891135 seconds
2025-06-15T03:03:32.615Z INFO model_runner.load_model: Model loading took 13.9477 GiB and 68.958333 seconds
2025-06-15T03:03:32.644Z INFO model_runner.load_model: Model loading took 13.9477 GiB and 68.910343 seconds
2025-06-15T03:03:32.647Z INFO model_runner.load_model: Model loading took 13.9477 GiB and 68.958805 seconds
2025-06-15T03:03:38.653Z INFO worker.determine_num_available_blocks: Memory profiling takes 5.77 seconds
the current vLLM instance can use total_gpu_memory (21.99GiB) x gpu_memory_utilization (0.90) = 19.79GiB
model weights take 13.95GiB; non_torch_memory takes 0.20GiB; PyTorch activation peak memory takes 0.89GiB; the rest of the memory reserved for KV Cache is 4.75GiB.
2025-06-15T03:03:38.769Z INFO worker.determine_num_available_blocks: Memory profiling takes 5.89 seconds
the current vLLM instance can use total_gpu_memory (21.99GiB) x gpu_memory_utilization (0.90) = 19.79GiB
model weights take 13.95GiB; non_torch_memory takes 0.20GiB; PyTorch activation peak memory takes 0.89GiB; the rest of the memory reserved for KV Cache is 4.75GiB.
2025-06-15T03:03:39.013Z INFO executor_base.initialize_cache: # cuda blocks: 809, # CPU blocks: 682
2025-06-15T03:03:39.013Z INFO executor_base.initialize_cache: Maximum concurrency for 10240 tokens per request: 5.06x
2025-06-15T03:03:41.134Z INFO model_runner.capture_model: Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasing `gpu_memory_utilization` or switching to eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
2025-06-15T03:03:41.573Z INFO model_runner.capture_model: Capturing cudagraphs for decoding. This may lead to unexpected consequences if the model is not static. To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI. If out-of-memory error occurs during cudagraph capture, consider decreasing `gpu_memory_utilization` or switching to eager mode. You can also reduce the `max_num_seqs` as needed to decrease memory usage.
Capturing CUDA graph shapes: 67%|██████████████████████████████████████████████████ | 4/6 [00:02<00:01, 1.72it/s]2025-06-15T03:03:43.990Z INFO custom_all_reduce.register_graph_buffers: Registering 582 cuda graph addresses
Capturing CUDA graph shapes: 100%|███████████████████████████████████████████████████████████████████████████| 6/6 [00:03<00:00, 1.68it/s]
2025-06-15T03:03:45.149Z INFO custom_all_reduce.register_graph_buffers: Registering 582 cuda graph addresses
2025-06-15T03:03:45.161Z INFO model_runner.capture_model: Graph capturing finished in 4 secs, took 0.07 GiB
2025-06-15T03:03:45.168Z INFO model_runner.capture_model: Graph capturing finished in 4 secs, took 0.07 GiB
2025-06-15T03:03:45.169Z INFO llm_engine._initialize_kv_caches: init engine (profile, create kv cache, warmup model) took 12.52 seconds
2025-06-15T03:03:45.212Z INFO nixl.__init__: Initializing NIXL wrapper
2025-06-15T03:03:45.221Z INFO nixl.__init__: Initializing NIXL wrapper
(VllmWorkerProcess pid=19063) Backend UCX was instantiated
(VllmWorkerProcess pid=19063) Initialized NIXL agent: 0e238e52-2b2d-4760-82aa-6702d7625c0f
Backend UCX was instantiated
Initialized NIXL agent: c4c022bc-68a3-4882-b1cc-e76c14285e93
2025-06-15T03:03:45.678Z INFO worker.create_metrics_publisher_endpoint: [VllmWorker:1] Creating metrics publisher endpoint with lease: <builtins.PyLease object at 0x7f871b94a910>
2025-06-15T03:03:45.688Z INFO worker.async_init: [VllmWorker:1] VllmWorker has been initialized
2025-06-15T03:03:45.688Z INFO serve_dynamo.worker: [VllmWorker:1] Starting VllmWorker instance with all registered endpoints
2025-06-15T03:03:45.688Z INFO serve_dynamo.worker: [VllmWorker:1] Serving VllmWorker with lease: 7587887483020983091
2025-06-15T03:03:45.689Z WARN utils.append_dynamo_state: [VllmWorker:1] Skipping append to state file /root/.dynamo/state/dynamo.json because it doesn't exist
2025-06-15T03:03:45.689Z INFO serve_dynamo.worker: [VllmWorker:1] Appended lease 7587887483020983091/694d9776a5193b33 to dynamo_VllmWorker
2025-06-15T03:03:45.809Z INFO logging.check_required_workers: [Processor:1] Waiting for more workers to be ready.
Current: 1, Required: 1
Workers ready: [7587887483020983091]
2025-06-15T03:03:45.816Z INFO processor._start_worker_tasks: [Processor:1] Started 4 queue worker tasks
2025-06-15T03:03:45.816Z INFO serve_dynamo.worker: [Processor:1] Starting Processor instance with all registered endpoints
2025-06-15T03:03:45.816Z INFO serve_dynamo.worker: [Processor:1] Serving Processor with primary lease
2025-06-15T03:03:45.816Z INFO processor._process_queue: [Processor:1] Queue worker 0 started
2025-06-15T03:03:45.817Z INFO processor._process_queue: [Processor:1] Queue worker 1 started
2025-06-15T03:03:45.817Z INFO processor._process_queue: [Processor:1] Queue worker 2 started
2025-06-15T03:03:45.817Z INFO processor._process_queue: [Processor:1] Queue worker 3 started
2025-06-15T03:03:47.498Z INFO worker.determine_num_available_blocks: Memory profiling takes 14.60 seconds
the current vLLM instance can use total_gpu_memory (21.99GiB) x gpu_memory_utilization (0.90) = 19.79GiB
model weights take 13.95GiB; non_torch_memory takes 0.20GiB; PyTorch activation peak memory takes 2.84GiB; the rest of the memory reserved for KV Cache is 2.80GiB.
2025-06-15T03:03:47.521Z INFO worker.determine_num_available_blocks: Memory profiling takes 14.67 seconds
the current vLLM instance can use total_gpu_memory (21.99GiB) x gpu_memory_utilization (0.90) = 19.79GiB
model weights take 13.95GiB; non_torch_memory takes 0.20GiB; PyTorch activation peak memory takes 2.84GiB; the rest of the memory reserved for KV Cache is 2.80GiB.
2025-06-15T03:03:47.716Z INFO executor_base.initialize_cache: # cuda blocks: 478, # CPU blocks: 682
2025-06-15T03:03:47.716Z INFO executor_base.initialize_cache: Maximum concurrency for 10240 tokens per request: 2.99x
2025-06-15T03:03:49.951Z INFO llm_engine._initialize_kv_caches: init engine (profile, create kv cache, warmup model) took 17.31 seconds
2025-06-15T03:03:50.010Z INFO nixl.__init__: Initializing NIXL wrapper
Backend UCX was instantiated
Initialized NIXL agent: 2c291c65-e981-4af1-a8dd-6b8a95834a2e
2025-06-15T03:03:50.144Z INFO nixl.__init__: Initializing NIXL wrapper
(VllmWorkerProcess pid=19059) Backend UCX was instantiated
(VllmWorkerProcess pid=19059) Initialized NIXL agent: 1c8683a7-4b97-4a93-a6b7-a9780fb7b150
2025-06-15T03:03:50.370Z INFO prefill_worker.async_init: [PrefillWorker:1] PrefillWorker initialized
2025-06-15T03:03:50.370Z INFO serve_dynamo.worker: [PrefillWorker:1] Starting PrefillWorker instance with all registered endpoints
2025-06-15T03:03:50.371Z INFO serve_dynamo.worker: [PrefillWorker:1] Serving PrefillWorker with lease: 7587887483020983089
2025-06-15T03:03:50.371Z WARN utils.append_dynamo_state: [PrefillWorker:1] Skipping append to state file /root/.dynamo/state/dynamo.json because it doesn't exist
2025-06-15T03:03:50.371Z INFO serve_dynamo.worker: [PrefillWorker:1] Appended lease 7587887483020983089/694d9776a5193b31 to dynamo_PrefillWorker
2025-06-15T03:03:50.371Z INFO prefill_worker.prefill_queue_handler: [PrefillWorker:1] Prefill queue handler entered
2025-06-15T03:03:50.371Z INFO prefill_worker.prefill_queue_handler: [PrefillWorker:1] Prefill queue: nats://localhost:4222:vllm
2025-06-15T03:03:50.381Z INFO prefill_worker.prefill_queue_handler: [PrefillWorker:1] prefill queue handler started
6. 调用服务
curl -X POST -s http://0.0.0.0:8009/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "RAG_LLM",
"messages": [{"role": "user", "content": "你好,请你分析一下深度学习发展的历史重大节点"}],
"max_tokens": 6000,
"temperature": 0.1, "stream": true
}'
输出日志:
2025-06-15T03:04:10.287Z INFO chat_utils._log_chat_template_content_format: Detected the chat template content format to be 'string'. You can set `--chat-template-content-format` to override this.
2025-06-15T03:04:10.373Z INFO disagg_router.prefill_remote: [VllmWorker:1] Remote prefill: True (prefill length: 14/1, prefill queue size: 0/10)
2025-06-15T03:04:10.373Z INFO worker.generate: [VllmWorker:1] Prefilling remotely for request fdcc73c7-40a9-4e40-a803-6a86aa632274 with length 14
2025-06-15T03:04:10.380Z INFO engine._handle_process_request: Added request fdcc73c7-40a9-4e40-a803-6a86aa632274.
(VllmWorkerProcess pid=19063) /opt/dynamo/venv/lib/python3.12/site-packages/vllm/distributed/parallel_state.py:426: UserWarning: The given buffer is not writable, and PyTorch does not support non-writable tensors. This means you can write to the underlying (supposedly non-writable) buffer using the tensor. You may want to copy the buffer to protect its data or make it writable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_new.cpp:1561.)
(VllmWorkerProcess pid=19063) object_tensor = torch.frombuffer(pickle.dumps(obj), dtype=torch.uint8)
2025-06-15T03:04:10.394Z INFO prefill_worker.prefill_queue_handler: [PrefillWorker:1] Dequeued prefill request: fdcc73c7-40a9-4e40-a803-6a86aa632274
2025-06-15T03:04:10.397Z INFO prefill_worker.generate: [PrefillWorker:1] Loaded nixl metadata from engine 78d98639-043c-49cf-a588-cf0ecddba5b7 into engine f11c5232-b214-4f02-bb5e-25e344d85f15
2025-06-15T03:04:10.522Z INFO engine._handle_process_request: Added request fdcc73c7-40a9-4e40-a803-6a86aa632274.
2025-06-15T03:04:10.695Z INFO metrics.log: Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 2.8 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.1%, CPU KV cache usage: 0.0%.
2025-06-15T03:04:10.695Z INFO metrics.log: Prefix cache hit rate: GPU: 0.00%, CPU: 0.00%
(VllmWorkerProcess pid=19059) /opt/dynamo/venv/lib/python3.12/site-packages/vllm/distributed/parallel_state.py:426: UserWarning: The given buffer is not writable, and PyTorch does not support non-writable tensors. This means you can write to the underlying (supposedly non-writable) buffer using the tensor. You may want to copy the buffer to protect its data or make it writable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /pytorch/torch/csrc/utils/tensor_new.cpp:1561.)
(VllmWorkerProcess pid=19059) object_tensor = torch.frombuffer(pickle.dumps(obj), dtype=torch.uint8)
2025-06-15T03:04:15.394Z INFO metrics.log: Avg prompt throughput: 2.8 tokens/s, Avg generation throughput: 0.2 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.2%, CPU KV cache usage: 0.0%.
blog from https://michael.blog.csdn.net/
7. benchmark测试
参考文章:
- https://mp.weixin.qq.com/s/DHdtsDNIJODJKRK1ePoDtA
- https://github.com/vllm-project/production-stack/tree/main/benchmarks/multi-round-qa
测试命令
python3 multi-round-qa.py \
--time 60 \
--num-users 20 \
--num-rounds 3 \
--qps 10 \
--shared-system-prompt 1000 \
--user-history-prompt 2000 \
--answer-len 100 \
--model RAG_LLM \
--base-url http://0.0.0.0:8009/v1
dynamo测试结果
==================== Performance summary ======================
QPS: 10.0000 reqs/s
Processing speed: 0.4918 reqs/s
Requests on-the-fly: 147
Input tokens per second: 1496.0399 tokens/s
Output tokens per second: 49.1831 tokens/s
Average generation throughput (per request): 20.4575 tokens/req/s
Average TTFT: 22.0041s
Time range: 1750058018.8378131 - 1750058081.8675487 (63.03s)
===============================================================
可以看到还有147个请求没有响应完,日志报错了
2025-06-15T07:28:11.934Z ERROR dynamo_runtime::pipeline::network::tcp::client: failed to join reader and writer tasks
request_output = await queue.get()
2025-06-15T07:28:11.935Z ERROR dynamo_runtime::pipeline::network::tcp::client: failed to join reader and writer tasks
File "/opt/dynamo/venv/lib/python3.12/site-packages/vllm/engine/multiprocessing/client.py", line 787, in _process_request
await getter
async for item in func(*args_list, **kwargs):
async for item in func(*args_list, **kwargs):
request_output = await queue.get()
^^^^^^^^^^^^^^^^^
^^^^^^^^^^^^^^^^^
asyncio.exceptions.CancelledError
File "/usr/lib/python3.12/asyncio/queues.py", line 158, in get
File "/usr/lib/python3.12/asyncio/queues.py", line 158, in get
^^^^^^^^^^^^^^^^^
File "/workspace/examples/llm/components/worker.py", line 216, in generate
await getter
File "/usr/lib/python3.12/asyncio/queues.py", line 158, in get
File "/workspace/examples/llm/components/worker.py", line 216, in generate
asyncio.exceptions.CancelledError
await getter
2025-06-15T07:28:11.938Z ERROR dynamo_runtime::pipeline::network::tcp::client: failed to join reader and writer tasks
async for response in self.engine_client.generate(
async for response in self.engine_client.generate(
asyncio.exceptions.CancelledError
File "/opt/dynamo/venv/lib/python3.12/site-packages/vllm/engine/multiprocessing/client.py", line 787, in _process_request
2025-06-15T07:28:11.939Z ERROR dynamo_runtime::pipeline::network::tcp::client: failed to join reader and writer tasks
await getter
2025-06-15T07:28:11.940Z ERROR dynamo_runtime::pipeline::network::tcp::client: failed to join reader and writer tasks
File "/opt/dynamo/venv/lib/python3.12/site-packages/vllm/engine/multiprocessing/client.py", line 787, in _process_request
asyncio.exceptions.CancelledError
request_output = await queue.get()
2025-06-15T07:28:11.941Z ERROR dynamo_runtime::pipeline::network::tcp::client: failed to join reader and writer tasks
request_output = await queue.get()
^^^^^^^^^^^^^^^^^
^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.12/asyncio/queues.py", line 158, in get
error handling callback was invoked with status -25 (Connection reset by remote peer)
File "/usr/lib/python3.12/asyncio/queues.py", line 158, in get
await getter
await getter
asyncio.exceptions.CancelledError
asyncio.exceptions.CancelledError
2025-06-15T07:28:11.943Z ERROR dynamo_runtime::pipeline::network::tcp::client: failed to join reader and writer tasks
2025-06-15T07:28:11.944Z ERROR dynamo_runtime::pipeline::network::tcp::client: failed to join reader and writer tasks
2025-06-15T07:28:12.706Z ERROR multiproc_worker_utils.run: Worker VllmWorkerProcess pid 29094 died, exit code: -15
2025-06-15T07:28:12.706Z INFO multiproc_worker_utils.run: Killing local vLLM worker processes
Exception ignored in: <function LLMEngine.__del__ at 0x7fe87f4acea0>
Traceback (most recent call last):
File "/opt/dynamo/venv/lib/python3.12/site-packages/vllm/engine/llm_engine.py", line 597, in __del__
model_executor.collective_rpc("shutdown_nixl")
File "/opt/dynamo/venv/lib/python3.12/site-packages/vllm/executor/executor_base.py", line 331, in collective_rpc
return self._run_workers(method, *args, **(kwargs or {}))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/dynamo/venv/lib/python3.12/site-packages/vllm/executor/mp_distributed_executor.py", line 181, in _run_workers
worker.execute_method(sent_method, *args, **kwargs)
File "/opt/dynamo/venv/lib/python3.12/site-packages/vllm/executor/multiproc_worker_utils.py", line 183, in execute_method
self._enqueue_task(future, method, args, kwargs)
File "/opt/dynamo/venv/lib/python3.12/site-packages/vllm/executor/multiproc_worker_utils.py", line 179, in _enqueue_task
raise ChildProcessError("worker died") from e
ChildProcessError: worker died
[rank0]:[W616 07:28:13.097161642 ProcessGroupNCCL.cpp:1496] Warning: WARNING: destroy_process_group() was not called before program exit, which can leak resources. For more info, please see https://pytorch.org/docs/stable/distributed.html#shutdown (function operator())
2025-06-15T07:28:15.310Z ERROR serve_dynamo: [VllmWorker:1] Error in main: Event loop stopped before Future completed.
/usr/lib/python3.12/multiprocessing/resource_tracker.py:254: UserWarning: resource_tracker: There appear to be 1 leaked shared_memory objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
/usr/lib/python3.12/multiprocessing/resource_tracker.py:254: UserWarning: resource_tracker: There appear to be 1 leaked shared_memory objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
2025-06-15T07:28:17.609Z INFO watcher._stop: dynamo_VllmWorker stopped
再单独使用 VLLM 启动同样模型,张量并行=4,不使用pd分离,进行测试
==================== Performance summary ======================
QPS: 10.0000 reqs/s
Processing speed: 1.5851 reqs/s
Requests on-the-fly: 0
Input tokens per second: 4851.8923 tokens/s
Output tokens per second: 158.5126 tokens/s
Average generation throughput (per request): 17.4184 tokens/req/s
Average TTFT: 48.2792s
Time range: 1750057556.1626415 - 1750057680.4430168 (124.28s)
===============================================================
由于dynamo还在快速迭代中,以上测试存在缺陷,做个不太科学的对比:
dynamo pd分离 | vllm no pd分离 | |
|---|---|---|
TTFT 首token延迟 | 22 s | 48 s |
Average generation throughput (per request) 输出token速度 | 20.5 tokens/req/s | 17.4 tokens/req/s |
可以看到dynamo在首token上快了一倍,输出速度也略快。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号