AI 小记


有小伙伴说松哥好久没有发文章了,今年主要是工作比较忙,有时候还有一些技术活动,一来一去一耽搁,公众号就随缘更了。这周末有空,和小伙伴们随便聊一聊。
今天这篇文章我们我们先大致梳理一下神经网络和自然语言处理的发展脉络,从宏观层面先来看下这两项技术的发展历程。
学术界普遍将 1956 年达特茅斯会议视为人工智能发展的起点。此次会议汇聚了计算机科学家、数学家、语言学家等领域的专家学者,共同探讨智能机器的发展前景。此后,诸多人工智能相关的核心概念与技术相继涌现。
但是和很多技术的发展一样,人工智能技术的发展也是有高潮有低谷。那么接下来松哥尝试从神经网络和自然语言处理这两个方向,和小伙伴们聊一聊人工智能技术发展的起起落落。
一 神经网络发展脉络
神经网络技术的发展大致可以分为三个阶段。
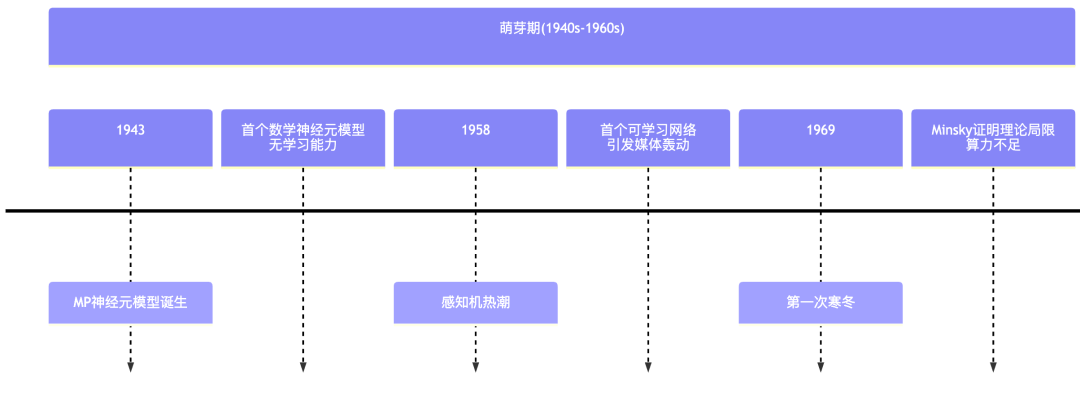
1.1 萌芽期(1940-1960):从神经元到感知机
神经网络的发展最早可以追溯到 1943 年,当时数学家 McCulloch 和逻辑学家 Pitts 用数学公式模拟生物神经元,输入信号加权求和后,超过阈值则“激活”(输出1),否则不输出。这是神经网络的“积木块”,我们称之为 McCulloch-Pitts神经元模型。
这种模型有很大的局限性:无学习能力,并且参数需人工设定,因此只能做简单逻辑运算。
转眼到了 1958 年,也就是达特茅斯会议之后两年,心理学家 Frank Rosenblatt 发明首个可学习的神经网络,也就是感知机,通过调整权重自动分类数据(如识别字母 “A” 和 “B”)。当时《纽约时报》预言它将实现“行走、说话、看和写作”。虽然这只是一种线性分类器,但却具有重要的历史地位,是现代神经网络的雏形和起点。
感知机首次展示了“机器学习”的潜力,引发学术界和媒体狂热。
狂热之后,很快迎来 AI 的第一次寒冬。
1969年,AI 先驱 Marvin Minsky 在感知机一书中证明感知机无法解决“异或问题”(如区分对角线方向),且单层网络无法处理复杂模式。给火热的感知机技术破了一盆冷水,同时由于硬件算力不足(1960 计算机速度慢)、理论瓶颈被放大,政府资助锐减,研究停滞近 20 年。
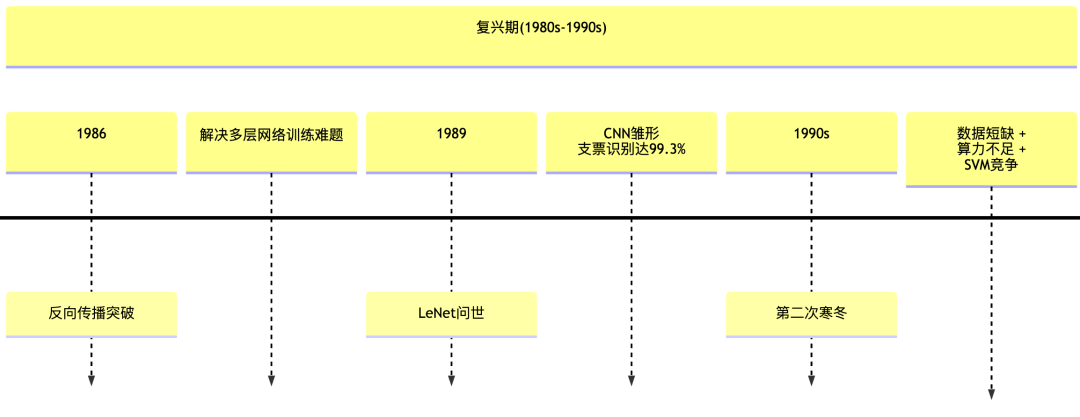
1.2 复兴期(1980-1990):多层网络与算法突破
1986 年,Hinton 团队提出“多层反向传播算法(Backpropagation)”,像剥洋葱一样从输出层逐层调整参数,解决多层网络训练难题。例如,教网络识别手写数字时,错误会反向传递并修正权重。
这一时期,由于算法突破 + 计算机性能提升,神经网络能处理非线性问题,应用扩展到语音识别(如电话按键音识别)、医疗诊断等领域。
时间到了 1989 年,法国计算机科学家 Yann LeCun 用卷积层(局部感知)和池化层(压缩信息)构建 LeNet,成功识别银行支票手写数字(准确率 99.3%),这就是卷积神经网络(Convolutional Neural Network,CNN),这是一种特殊的深度学习模型,使用卷积层来学习局部特征,被广泛应用于图像识别和计算机视觉领域。
随后在 1995 年出现的支持向量机(SVM),由于算法优美,训练快,并且在中小数据集上训练效果更好。这不得不让人们怀疑神经网络到底有没有发展前景?
同时,神经网络往往被视为“黑箱”(结果难解释)、易过拟合(死记硬背不会举一反三),学术论文甚至因“使用神经网络”被拒稿。
神经网络的发展迎来又一次的低潮。
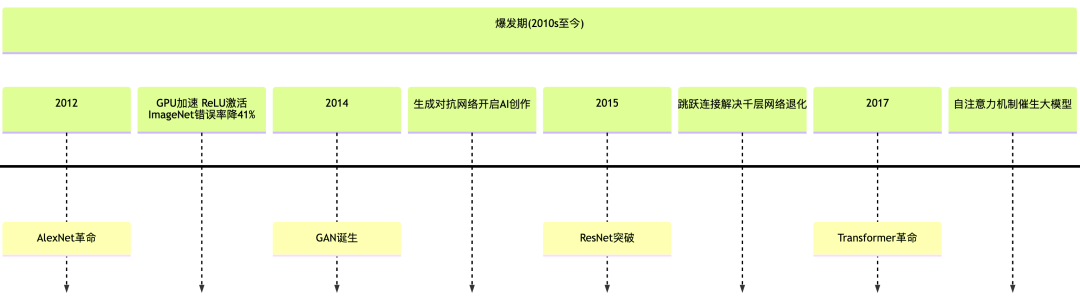
1.3 爆发期(2010 至今):深度学习的黄金时代
随着计算机技术的发展,算力和数据都有了很大的提升,借着硬件与数据的东风,神经网络的发展又迎来了黄金时代。
这里有几个里程碑事件。
首先是 2012 年问世的 AlexNet,这助力 Hinton 团队在 ImageNet 图像识别大赛中夺冠,错误率骤降 41%(26%→15%)。AlexNet 通过 ReLU 激活函数(缓解梯度消失)、GPU 训练以及 Dropout 防过拟合。
AlexNet 的出现点燃了人们深度学习热潮,资本涌入 AI 领域。
到了 2017 年,Google用自注意力机制(Self-Attention)替代循环结构,实现文本并行处理。模型可同时关注句子中所有词(如“猫追老鼠”中“追”关联两个名词)。 这就是 Transformer,由 Ashish Vaswani 等人在 2017 年的论文 《Attention is All you Need》 中首次提出。
这是一次重大的突破,成为了后来 GPT、BERT 等大模型的基石,并且推动了后来 ChatGPT 的诞生。
画图总结下神经网络发展脉络,如下:
二 自然语言处理发展脉络
自然语言处理的整体发展脉络则是从规则到统计。
2.1 规则系统时代(1950-1980)
这一时期的核心思想是让计算机像人类一样通过“语法规则”理解语言,类似背字典和学语法。 早在 1954 年,IBM 实验首次实现俄语→英语的机器翻译,仅用 6 条语法规则翻译 60 句话,引发“机器翻译五年内普及”的乐观预期。
到了 1966 年,ELIZA 聊天机器人通过模拟心理咨询师,用关键词匹配生成预设回答(如用户说“我难过”,它回复“为什么难过?”)。虽效果简陋,却是人机对话的起点。
但是基于规则的自然语言处理最终却没有发展起来,究其原因,主要有如下两方面:
- 语言复杂性远超预期:一词多义(如“苹果”指水果还是公司?)、方言、俚语等让规则数量爆炸式增长。
- 1966 年 ALPAC 报告:美国政府评估发现机器翻译错误百出,投入十年仍未实用,经费遭大幅削减,NLP 进入“寒冬”。
2.2 统计方法崛起(1990-2010)
这一时期的核心思想从“教规则”转向“让机器从数据中学习规律”,利用概率模型处理语言。
在 1990 年,IBM 提出基于概率的翻译模型(SMT),通过分析双语对照文本,计算“apple”翻译成“苹果”的概率。
到了 2000 年后的垃圾邮件过滤器,用贝叶斯算法分析邮件关键词(如“免费”“中奖”),计算垃圾邮件概率,准确率大幅提升。
2003 年 Word2Vec 初具雏形,首次将单词转为数学向量,让计算机捕捉语义(如“国王-男人+女人≈女王”)。
这一时期由于互联网的爆发提供海量文本数据(邮件、网页、新闻),同时算力提升使统计模型可处理大规模语料库。
2.3 深度学习革命(2010中期-至今)
这一时期的核心思想是用神经网络模拟人脑,自动学习语言深层规律。
一些里程碑的事件松哥这里列出来供大家参考:
- 2013 年的 Word2Vec 词向量技术,让机器理解近义词(如“快乐”和“开心”)。
- 2014 年的 Seq2Seq 模型,实现端到端翻译(如输入中文直接输出英文),取代统计机器翻译。
- 2017 年的 Transformer 架构引入自注意力机制,解决长距离语义依赖问题(如理解段落首尾关联)。
到了大模型时代:
- 2018 年 BERT/GPT:通过预训练模型吸收全网知识,微调后胜任翻译、问答等任务。例如 BERT 在医疗问答中准确率超 95%。
- 2020 年 GPT-3:1750 亿参数模型,可写小说、编代码,实现“零样本学习”(无需训练直接执行新任务)。
- 2022年 ChatGPT:基于GPT优化对话能力,实现拟人化交互(如连续对话、承认错误)。
- 再往后的故事相信大家都知道了
这一时期由于 GPU 算力飞跃再加上互联网数据指数级增长,极大的促进了人工智能的发展。

以上是一个大致的发展脉络,上文涉及到的很多技术名词,松哥将在后面的文章中和小伙伴们逐一详聊,敬请期待。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号