机器学习经典算法:高斯朴素贝叶斯(Gaussian Naive Bayes)原理、手动计算与Python/Java双代码实战
原创
机器学习经典算法:高斯朴素贝叶斯(Gaussian Naive Bayes)原理、手动计算与Python/Java双代码实战
原创
jack.yang
发布于 2026-03-29 13:34:40
发布于 2026-03-29 13:34:40
一句话答案:高斯朴素贝叶斯是朴素贝叶斯的连续版,假设特征服从正态分布。无需离散化,直接处理身高、温度、成绩等连续数据,3行代码即可实现鸢尾花分类!
如果你在搜索:
- “高斯朴素贝叶斯怎么算的?”
- “Gaussian NB 手动计算例子”
- “连续数据如何用朴素贝叶斯分类?”
- “Python 和 Java 怎么实现高斯朴素贝叶斯?”
那么,这篇文章就是为你写的——从概率密度函数到代码落地,一步不跳。
一、什么是高斯朴素贝叶斯?它和普通朴素贝叶斯有何不同?
朴素贝叶斯家族有多个成员,选择哪个取决于你的数据类型:
算法类型 | 适用数据 | 核心假设 |
|---|---|---|
多项式朴素贝叶斯 | 离散计数(如词频) | 特征服从多项式分布 |
伯努利朴素贝叶斯 | 二值特征(0/1) | 特征是布尔值 |
高斯朴素贝叶斯 | 连续数值(如身高、价格、温度) | 特征服从高斯(正态)分布 |
🤔 为什么需要高斯版本?
普通朴素贝叶斯只能处理“词是否出现”这类离散数据。但现实世界充满连续值:
- 鸢尾花的花瓣长度(5.1cm, 4.9cm...)
- 用户的收入(8500元, 12000元...)
- 传感器的温度读数(23.5°C, 24.1°C...)
如果强行将这些连续值分箱(如“5.0-5.5cm”),会丢失精度。高斯朴素贝叶斯则直接建模其概率密度,更优雅、更准确。
💡 核心思想:对于每个类别,每个连续特征都拟合一个独立的正态分布(由均值μ和标准差σ决定)。新样本的概率,由它在该分布中的“位置”决定。
二、数学原理:高斯分布 + 贝叶斯定理
我们要计算:
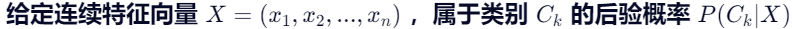
根据贝叶斯定理和独立性假设:

📐 高斯概率密度函数(PDF)

三、手工推演:一步步计算鸢尾花分类(带完整数据)
📊 训练数据集(简化版鸢尾花,仅2个类别、2个特征)
花样 | 花瓣长 (cm) | 花瓣宽 (cm) | 品种(类别) |
|---|---|---|---|
1 | 5.0 | 3.6 | Setosa (0) |
2 | 5.4 | 3.4 | Setosa (0) |
3 | 5.4 | 3.0 | Versicolor (1) |
4 | 5.6 | 3.0 | Versicolor (1) |
5 | 5.7 | 2.9 | Versicolor (1) |
目标:预测新样本
[5.5, 3.2]属于哪个品种?
🔢 步骤1:计算先验概率 (P(C))
- 总样本数 = 5
- Setosa (0) 数 = 2 → (P(0) = 2/5 = 0.4)
- Versicolor (1) 数 = 3 → (P(1) = 3/5 = 0.6)
🔢 步骤2:为每个类别-特征组合计算 μ 和 σ
对于 Setosa (类别 0):
- 花瓣长: [5.0, 5.4]
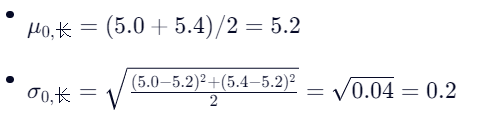
- 花瓣宽: [3.6, 3.4]
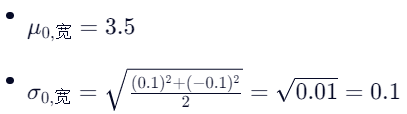
对于 Versicolor (类别 1):
- 花瓣长: [5.4, 5.6, 5.7]

- 花瓣宽: [3.0, 3.0, 2.9]
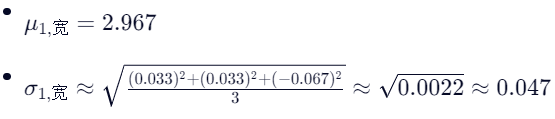
🔢 步骤3:计算新样本 [5.5, 3.2] 在两类下的似然
为避免下溢,我们计算对数似然:
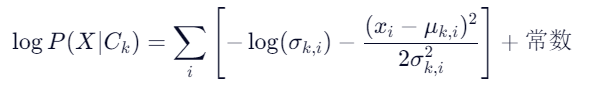
对于 Setosa (0):
对于 Versicolor (1):

🔢 步骤4:比较并决策
- Setosa 得分: -2.630
- Versicolor 得分: -7.859
✅ 结论:-2.630 > -7.859 → 判定为 Setosa (0)
尽管花瓣长更接近Versicolor的均值,但花瓣宽(3.2 vs Versicolor的~2.97)偏离太大,导致其概率密度极低,最终被判为Setosa。
四、Python 实现(scikit-learn + 手写版)
✅ 方式1:使用 scikit-learn(推荐生产环境)
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
data = load_iris()
X, y = data.data, data.target
# 为简化,只取前两类(Setosa 和 Versicolor)
X = X[y != 2]
y = y[y != 2]
# 划分训练/测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 训练模型
clf = GaussianNB()
clf.fit(X_train, y_train)
# 预测新样本 [5.5, 3.2, ...](后两个特征用均值填充)
import numpy as np
new_sample = np.array([[5.5, 3.2, X_train[:, 2].mean(), X_train[:, 3].mean()]])
pred = clf.predict(new_sample)
print("预测类别:", "Setosa" if pred[0] == 0 else "Versicolor")✅ 方式2:手写核心逻辑
import numpy as np
class GaussianNB:
def fit(self, X, y):
self.classes = np.unique(y)
self.params = {}
for c in self.classes:
X_c = X[y == c]
# 计算每个特征的均值和方差
mean = np.mean(X_c, axis=0)
var = np.var(X_c, axis=0) + 1e-9 # 防止除零
self.params[c] = (mean, var)
# 先验概率
self.priors = {c: np.mean(y == c) for c in self.classes}
def _gaussian_pdf(self, x, mean, var):
# 计算高斯概率密度(对数形式)
return -0.5 * np.sum(np.log(2 * np.pi * var)) - 0.5 * np.sum((x - mean) ** 2 / var)
def predict(self, X):
predictions = []
for x in X:
posteriors = {}
for c in self.classes:
mean, var = self.params[c]
log_likelihood = self._gaussian_pdf(x, mean, var)
log_prior = np.log(self.priors[c])
posteriors[c] = log_likelihood + log_prior
predictions.append(max(posteriors, key=posteriors.get))
return np.array(predictions)
# 使用简化数据
X_train = np.array([[5.0, 3.6], [5.4, 3.4], [5.4, 3.0], [5.6, 3.0], [5.7, 2.9]])
y_train = np.array([0, 0, 1, 1, 1])
gnb = GaussianNB()
gnb.fit(X_train, y_train)
pred = gnb.predict(np.array())
print("预测结果:", "Setosa" if pred[0] == 0 else "Versicolor") # 输出: Setosa五、Java 实现(纯手写,无第三方库)
import java.util.*;
public class GaussianNaiveBayes {
private Map<Integer, double[]> classMeans = new HashMap<>();
private Map<Integer, double[]> classVars = new HashMap<>();
private Map<Integer, Double> priors = new HashMap<>();
private int numFeatures;
public void fit(double[][] X, int[] y) {
// 获取所有唯一类别
Set<Integer> classes = new HashSet<>();
for (int label : y) classes.add(label);
numFeatures = X[0].length;
// 为每个类别计算均值和方差
for (int c : classes) {
List<double[]> classData = new ArrayList<>();
for (int i = 0; i < y.length; i++) {
if (y[i] == c) {
classData.add(X[i]);
}
}
// 计算均值
double[] mean = new double[numFeatures];
for (double[] row : classData) {
for (int j = 0; j < numFeatures; j++) {
mean[j] += row[j];
}
}
for (int j = 0; j < numFeatures; j++) {
mean[j] /= classData.size();
}
classMeans.put(c, mean);
// 计算方差
double[] variance = new double[numFeatures];
for (double[] row : classData) {
for (int j = 0; j < numFeatures; j++) {
variance[j] += Math.pow(row[j] - mean[j], 2);
}
}
for (int j = 0; j < numFeatures; j++) {
variance[j] = variance[j] / classData.size() + 1e-9; // 防止除零
}
classVars.put(c, variance);
// 先验概率
priors.put(c, (double) classData.size() / y.length);
}
}
private double gaussianLogPdf(double[] x, double[] mean, double[] var) {
double logProb = 0.0;
for (int i = 0; i < numFeatures; i++) {
logProb -= 0.5 * Math.log(2 * Math.PI * var[i]);
logProb -= 0.5 * Math.pow(x[i] - mean[i], 2) / var[i];
}
return logProb;
}
public int predict(double[] x) {
Map<Integer, Double> posteriors = new HashMap<>();
for (int c : priors.keySet()) {
double logLikelihood = gaussianLogPdf(x, classMeans.get(c), classVars.get(c));
double logPrior = Math.log(priors.get(c));
posteriors.put(c, logLikelihood + logPrior);
}
// 返回后验概率最大的类别
return Collections.max(posteriors.entrySet(), Map.Entry.comparingByValue()).getKey();
}
// 测试
public static void main(String[] args) {
double[][] X = {
{5.0, 3.6},
{5.4, 3.4},
{5.4, 3.0},
{5.6, 3.0},
{5.7, 2.9}
};
int[] y = {0, 0, 1, 1, 1};
GaussianNaiveBayes gnb = new GaussianNaiveBayes();
gnb.fit(X, y);
double[] testSample = {5.5, 3.2};
int prediction = gnb.predict(testSample);
System.out.println("预测结果: " + (prediction == 0 ? "Setosa" : "Versicolor"));
// 输出: Setosa
}
}六、优缺点 & 适用场景总结
优点 | 缺点 |
|---|---|
✅ 直接处理连续数据,无需离散化 | ❌ 假设特征服从高斯分布(现实中未必成立) |
✅ 计算高效,O(n)复杂度 | ❌ 无法捕捉特征间相关性(协方差为0) |
✅ 对小样本鲁棒 | ❌ 对异常值敏感(影响均值和方差) |
✅ 输出概率,可解释性强 | ❌ 当特征分布严重偏斜时效果下降 |
🎯 最佳应用场景:
- 生物特征识别(身高、体重、血压)
- 金融风控(收入、信用分)
- 传感器数据分析(温度、湿度、压力)
- 任何特征近似正态分布的连续数据分类任务
七、后续算法预告(均含手工推演 + 双语言代码)
本系列将持续更新以下算法,每篇均包含:
- 真实数据手工一步步计算
- Python + Java 完整可运行代码
即将发布:
- K近邻(KNN):从欧氏距离到手写数字识别
- 决策树(ID3/C4.5):信息增益如何分裂节点?
- 支持向量机(SVM):硬间隔、软间隔、核函数全解析
- 逻辑回归:从sigmoid到梯度下降
✅ 结语
高斯朴素贝叶斯用最简单的分布假设,解锁了连续数据的分类能力。它不追求复杂,只求在合适的场景下,快速、稳定地给出答案。
记住:在机器学习中,“合适”比“先进”更重要。
现在,你已经能:
- 手动计算高斯朴素贝叶斯分类结果
- 用Python或Java从零实现它
- 判断何时该用高斯NB而非其他分类器
相关链接
- 📂 大模型技术专栏: 欢迎您到访 「大模型系列」。 在这个由参数驱动、以数据为燃料的新智能时代,大语言模型(LLM)已不再是实验室里的前沿概念,而是正在重塑搜索、办公、编程、教育、医疗乃至整个数字世界的底层引擎。从 GPT 到 Llama,从 Claude 到 Qwen,从推理到多模态,大模型正以前所未有的速度进化——它们既是工具,也是平台,更可能是下一代人机交互的“操作系统”。 本系列将带你:
- 🔍 深入原理:从 Transformer 架构、注意力机制到训练范式(预训练、微调、RLHF);
- ⚙️ 动手实践:本地部署、模型微调、RAG 构建、Agent 设计等实战指南;
- 🧠 理解边界:幻觉、偏见、安全对齐、推理瓶颈与当前能力天花板;
- 🌍 洞察趋势:开源 vs 闭源、端侧部署、MoE 架构、世界模型与 AGI 路径;
- 💼 落地应用:如何在企业中安全、高效、低成本地集成大模型能力。
无论你是想写代码调用 API 的开发者,设计 AI 产品的 PM,评估技术路线的管理者,还是单纯好奇智能本质的思考者,这里都有值得你驻足的内容。 不追 hype,只讲逻辑;不谈玄学,专注可复现的认知。 让我们一起,在这场百年一遇的智能革命中,看得更清,走得更稳 https://cloud.tencent.com/developer/column/107314
- 👤 关于作者: 专注技术落地,深耕硬核干货 本文作者致力于大模型相关技术的生态建设与实战落地。不同于浅层的概念科普,作者坚持 “手算 + 代码” 的深度分享模式,主张通过手动推演理解算法本质,结合生产级代码验证理论可行性。 请关注我主页:https://cloud.tencent.com/developer/user/2276240
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号