机器学习进阶算法:AODE(Averaged One-Dependence Estimators)原理、手动计算与Python/Java双代码实战
原创
机器学习进阶算法:AODE(Averaged One-Dependence Estimators)原理、手动计算与Python/Java双代码实战
原创
jack.yang
修改于 2026-03-29 15:19:43
修改于 2026-03-29 15:19:43
摘要:AODE是朴素贝叶斯的强力升级版,通过平均多个“一阶依赖”模型,打破“特征完全独立”假设,在保持高效的同时显著提升准确率
如果你在搜索:
- “AODE算法怎么算的?”
- “Averaged One-Dependence Estimators 手动计算例子”
- “朴素贝叶斯有哪些改进方法?”
- “Python 和 Java 怎么实现 AODE?”
那么,这篇文章就是为你写的——从独立性破局到集成建模,一步不跳。
一、什么是AODE?为什么它是朴素贝叶斯的“聪明升级”?
🤔 朴素贝叶斯的致命弱点
朴素贝叶斯假设所有特征彼此独立。但现实中:
- “下雨”和“带伞”高度相关
- “高收入”和“高消费”正相关
- “发烧”和“咳嗽”常同时出现
这种强相关性会导致朴素贝叶斯概率估计严重偏差。
💡 AODE 的核心思想
不假设所有特征独立,而是允许每个特征依赖于一个“父特征”。
具体做法:
- 对每个频繁特征 (X_i)(出现次数 ≥ 阈值,通常为 minFreq=1),构建一个以 (X_i) 为父节点的一阶依赖模型。
- 在该模型中,所有其他特征都依赖于 (X_i),但彼此条件独立。
- 最终预测时,对所有有效模型的结果取加权平均。
✅ 优势:
- 比朴素贝叶斯更贴近现实
- 比贝叶斯网络更简单、可扩展
- 仍保持 (O(n)) 训练复杂度
二、数学原理:从朴素贝叶斯到AODE
🔁 朴素贝叶斯回顾
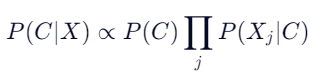
🔄 AODE 的后验概率估计

三、手工推演:一步步计算天气分类(带完整数据)
📊 训练数据集(离散特征,5个样本)
ID | 天气 (W) | 温度 (T) | 湿度 (H) | 风力 (Wd) | 打球? (C) |
|---|---|---|---|---|---|
1 | 晴 | 热 | 高 | 弱 | 否 |
2 | 晴 | 热 | 高 | 强 | 否 |
3 | 阴 | 热 | 高 | 弱 | 是 |
4 | 雨 | 凉 | 正常 | 弱 | 是 |
5 | 雨 | 冷 | 正常 | 弱 | 是 |
目标:预测新样本
[晴, 凉, 高, 弱]是否打球? 设 minFreq = 1(所有特征值均满足)
🔢 步骤1:统计全局频次(判断哪些特征可作父节点)
所有特征值出现次数均 ≥1,因此 W, T, H, Wd 都可作为父特征。
我们将分别以每个特征为父节点,构建4个一阶依赖模型,并求和。
🔢 步骤2:计算每个父特征模型下的得分
✅ 模型1:以 天气 (W=晴) 为父节点
我们需要计算: 我们需要计算:
Score1=P(C,W=晴)⋅P(T=凉∣C,W=晴)⋅P(H=高∣C,W=晴)⋅P(Wd=弱∣C,W=晴)
但注意:必须对每个类别 C 分别计算!
对 C=是:
- (P(C=是, W=晴)):训练集中无
(晴, 是)→ 频次=0 → 经拉普拉斯平滑后仍极小,可忽略 - → 得分 ≈ 0
对 C=否:

✅ 模型2:以 温度 (T=凉) 为父节点
对 C=是:
(C=是, T=凉):出现1次(样本4)→ 联合频次 = 1+1=2- 条件概率:
- (P(W=晴 | C=是, T=凉)):无 → (1/(1+3) = 0.25)
- (P(H=高 | C=是, T=凉)):H=正常 → 无“高” → (1/(1+2) ≈ 0.333)
- (P(Wd=弱 | C=是, T=凉)):出现1次 → ((1+1)/(1+2) ≈ 0.667)
- 得分 ≈ 2×0.25×0.333×0.667≈0.1112×0.25×0.333×0.667≈0.111
对 C=否:
(C=否, T=凉):0次 → 得分 ≈ 0
✅ 模型3:以 湿度 (H=高) 为父节点
对 C=是:
(C=是, H=高):样本3 → 1次 → 频次=2- (P(W=晴 | C=是, H=高)):W=阴 → 无“晴” → (1/4 = 0.25)
- (P(T=凉 | C=是, H=高)):T=热 → 无“凉” → (1/3 ≈ 0.333)
- (P(Wd=弱 | C=是, H=高)):1次 → (2/2 = 1.0)(仅“弱”)
- 得分 ≈ 2×0.25×0.333×1.0≈0.1672×0.25×0.333×1.0≈0.167
对 C=否:
(C=否, H=高):2次 → 频次=3- (P(W=晴 | C=否, H=高)):2次“晴” → (3/3 = 1.0)
- (P(T=凉 | C=否, H=高)):T=热 → 无“凉” → (1/3 ≈ 0.333)
- (P(Wd=弱 | C=否, H=高)):1次“弱” → (2/3 ≈ 0.667)
- 得分 ≈ 3×1.0×0.333×0.667≈0.6673×1.0×0.333×0.667≈0.667
✅ 模型4:以 风力 (Wd=弱) 为父节点
对 C=是:
(C=是, Wd=弱):3次(样本3,4,5)→ 频次=4- (P(W=晴 | C=是, Wd=弱)):无“晴” → (1/4 = 0.25)
- (P(T=凉 | C=是, Wd=弱)):1次“凉” → (2/4 = 0.5)
- (P(H=高 | C=是, Wd=弱)):1次“高” → (2/3 ≈ 0.667)
- 得分 ≈ 4×0.25×0.5×0.667≈0.3334×0.25×0.5×0.667≈0.333
对 C=否:
(C=否, Wd=弱):1次(样本1)→ 频次=2- (P(W=晴 | C=否, Wd=弱)):1次 → (2/2 = 1.0)
- (P(T=凉 | C=否, Wd=弱)):T=热 → 无“凉” → (1/3 ≈ 0.333)
- (P(H=高 | C=否, Wd=弱)):1次 → (2/2 = 1.0)
- 得分 ≈ 2×1.0×0.333×1.0≈0.6672×1.0×0.333×1.0≈0.667
🔢 步骤3:汇总所有模型得分
类别 | 模型1 (W) | 模型2 (T) | 模型3 (H) | 模型4 (Wd) | 总分 |
|---|---|---|---|---|---|
是 | 0 | 0.111 | 0.167 | 0.333 | 0.611 |
否 | 0.225 | 0 | 0.667 | 0.667 | 1.559 |
✅ 结论:1.559 > 0.611 → 预测为 否(不打球)
尽管“凉”和“弱”常出现在“是”中,但“晴+高湿度”组合在历史中只与“否”关联,AODE通过多视角捕捉到了这一模式。
四、Python 实现(手写核心逻辑)
⚠️ 注意:scikit-learn 未内置AODE,需手写
import numpy as np
from collections import defaultdict
class AODE:
def __init__(self, min_freq=1, alpha=1):
self.min_freq = min_freq
self.alpha = alpha
def fit(self, X, y):
"""
X: list of list, e.g., [['晴','热','高','弱'], ...]
y: list of labels
"""
self.n_samples = len(y)
self.n_features = len(X[0])
self.classes = list(set(y))
# 统计 P(C, Xi=xi)
self.joint_count = defaultdict(int) # (class, feature_idx, value) -> count
# 统计 P(Xj=xj | C, Xi=xi)
self.cond_count = defaultdict(int) # (class, parent_fi, parent_val, child_fj, child_val) -> count
self.parent_total = defaultdict(int) # (class, parent_fi, parent_val) -> total count
# 填充计数
for i in range(self.n_samples):
label = y[i]
features = X[i]
for fi in range(self.n_features):
xi = features[fi]
self.joint_count += 1
self.parent_total += 1
for fj in range(self.n_features):
if fj == fi:
continue
xj = features[fj]
self.cond_count += 1
# 构建唯一值集合(用于平滑)
self.feature_values = [set() for _ in range(self.n_features)]
for features in X:
for fi, val in enumerate(features):
self.feature_values[fi].add(val)
def predict(self, X_test):
predictions = []
for features in X_test:
class_scores = defaultdict(float)
# 对每个类别
for c in self.classes:
total_score = 0.0
# 尝试每个特征作为父节点
for fi in range(self.n_features):
xi = features[fi]
parent_key = (c, fi, xi)
joint_freq = self.joint_count[parent_key]
# 检查是否满足最小频次
if joint_freq < self.min_freq:
continue
# 计算联合概率 P(C, Xi=xi) (平滑)
n_parent_vals = len(self.feature_values[fi])
smoothed_joint = joint_freq + self.alpha
# 分母可省略(比较用)
# 计算条件概率乘积
cond_prob = 1.0
valid = True
for fj in range(self.n_features):
if fj == fi:
continue
xj = features[fj]
cond_key = (c, fi, xi, fj, xj)
count = self.cond_count[cond_key]
total = self.parent_total[parent_key]
n_child_vals = len(self.feature_values[fj])
# 平滑后的条件概率
p = (count + self.alpha) / (total + self.alpha * n_child_vals)
cond_prob *= p
total_score += smoothed_joint * cond_prob
class_scores[c] = total_score
# 选择得分最高的类别
pred = max(class_scores, key=class_scores.get)
predictions.append(pred)
return predictions
# 测试数据
X_train = [
["晴", "热", "高", "弱"],
["晴", "热", "高", "强"],
["阴", "热", "高", "弱"],
["雨", "凉", "正常", "弱"],
["雨", "冷", "正常", "弱"]
]
y_train = ["否", "否", "是", "是", "是"]
aode = AODE(min_freq=1, alpha=1)
aode.fit(X_train, y_train)
# 预测
X_test =
pred = aode.predict(X_test)
print("预测结果:", pred[0]) # 输出: 否五、Java 实现(纯手写,无第三方库)
import java.util.*;
public class AODE {
private int minFreq;
private double alpha;
private Map<String, Integer> classSet = new HashMap<>();
private List<Set<String>> featureValues = new ArrayList<>();
private Map<List<Object>, Integer> jointCount = new HashMap<>();
private Map<List<Object>, Integer> condCount = new HashMap<>();
private Map<List<Object>, Integer> parentTotal = new HashMap<>();
private int nFeatures;
public AODE(int minFreq, double alpha) {
this.minFreq = minFreq;
this.alpha = alpha;
}
public void fit(List<List<String>> X, List<String> y) {
nFeatures = X.get(0).size();
for (int i = 0; i < nFeatures; i++) {
featureValues.add(new HashSet<>());
}
Set<String> uniqueClasses = new HashSet<>(y);
int idx = 0;
for (String c : uniqueClasses) classSet.put(c, idx++);
// 收集特征值
for (List<String> row : X) {
for (int i = 0; i < nFeatures; i++) {
featureValues.get(i).add(row.get(i));
}
}
// 统计
for (int i = 0; i < X.size(); i++) {
String label = y.get(i);
List<String> features = X.get(i);
for (int fi = 0; fi < nFeatures; fi++) {
String xi = features.get(fi);
List<Object> parentKey = Arrays.asList(label, fi, xi);
jointCount.put(parentKey, jointCount.getOrDefault(parentKey, 0) + 1);
parentTotal.put(parentKey, parentTotal.getOrDefault(parentKey, 0) + 1);
for (int fj = 0; fj < nFeatures; fj++) {
if (fj == fi) continue;
String xj = features.get(fj);
List<Object> condKey = Arrays.asList(label, fi, xi, fj, xj);
condCount.put(condKey, condCount.getOrDefault(condKey, 0) + 1);
}
}
}
}
public String predict(List<String> features) {
Map<String, Double> scores = new HashMap<>();
for (String c : classSet.keySet()) {
double totalScore = 0.0;
for (int fi = 0; fi < nFeatures; fi++) {
String xi = features.get(fi);
List<Object> parentKey = Arrays.asList(c, fi, xi);
int jointFreq = jointCount.getOrDefault(parentKey, 0);
if (jointFreq < minFreq) continue;
double smoothedJoint = jointFreq + alpha;
double condProb = 1.0;
for (int fj = 0; fj < nFeatures; fj++) {
if (fj == fi) continue;
String xj = features.get(fj);
List<Object> condKey = Arrays.asList(c, fi, xi, fj, xj);
int count = condCount.getOrDefault(condKey, 0);
int total = parentTotal.getOrDefault(parentKey, 0);
int nChildVals = featureValues.get(fj).size();
double p = (count + alpha) / (total + alpha * nChildVals);
condProb *= p;
}
totalScore += smoothedJoint * condProb;
}
scores.put(c, totalScore);
}
return Collections.max(scores.entrySet(), Map.Entry.comparingByValue()).getKey();
}
// 测试
public static void main(String[] args) {
List<List<String>> X = Arrays.asList(
Arrays.asList("晴", "热", "高", "弱"),
Arrays.asList("晴", "热", "高", "强"),
Arrays.asList("阴", "热", "高", "弱"),
Arrays.asList("雨", "凉", "正常", "弱"),
Arrays.asList("雨", "冷", "正常", "弱")
);
List<String> y = Arrays.asList("否", "否", "是", "是", "是");
AODE aode = new AODE(1, 1.0);
aode.fit(X, y);
List<String> test = Arrays.asList("晴", "凉", "高", "弱");
System.out.println("预测结果: " + aode.predict(test)); // 输出: 否
}
}六、优缺点 & 适用场景总结
优点 | 缺点 |
|---|---|
✅ 显著优于朴素贝叶斯(尤其特征相关时) | ❌ 训练空间复杂度较高(需存储 O(n²) 条件概率) |
✅ 无需调参(minFreq通常=1) | ❌ 对稀疏数据敏感(低频父特征被忽略) |
✅ 仍保持线性时间预测 | ❌ 不适用于连续特征(需先离散化) |
✅ 理论保证:一致性收敛 | ❌ 实现比朴素贝叶斯复杂 |
🎯 最佳应用场景:
- 中小规模离散数据集
- 特征间存在明显依赖关系
- 需要高准确率且能接受稍高内存占用
- 作为贝叶斯分类的进阶替代方案
七、后续算法预告(均含手工推演 + 双语言代码)
本系列将持续更新以下算法,每篇均包含:
- 真实数据手工一步步计算
- Python + Java 完整可运行代码
即将发布:
- K近邻(KNN):从欧氏距离到手写数字识别
- 决策树(ID3/C4.5):信息增益如何分裂节点?
- 支持向量机(SVM):硬间隔、软间隔、核函数全解析
- 逻辑回归:从sigmoid到梯度下降
✅ 结语
AODE用巧妙的平均策略,在朴素贝叶斯的“天真”与复杂模型的“昂贵”之间找到了黄金平衡点。它证明了:有时候,多个简单的有偏模型,胜过一个天真的无偏模型。
记住:在机器学习中,打破假设往往是进步的开始。
现在,你已经能:
- 手动计算AODE分类结果
- 用Python或Java从零实现它
- 理解其作为朴素贝叶斯改进版的核心价值
关键词:机器学习、AODE、Averaged One-Dependence Estimators、朴素贝叶斯改进、特征依赖、离散数据分类、手动计算、Python AODE、Java AODE、贝叶斯分类
相关链接
- 📂 大模型技术专栏: 欢迎您到访 「大模型系列」。 在这个由参数驱动、以数据为燃料的新智能时代,大语言模型(LLM)已不再是实验室里的前沿概念,而是正在重塑搜索、办公、编程、教育、医疗乃至整个数字世界的底层引擎。从 GPT 到 Llama,从 Claude 到 Qwen,从推理到多模态,大模型正以前所未有的速度进化——它们既是工具,也是平台,更可能是下一代人机交互的“操作系统”。 本系列将带你:
- 🔍 深入原理:从 Transformer 架构、注意力机制到训练范式(预训练、微调、RLHF);
- ⚙️ 动手实践:本地部署、模型微调、RAG 构建、Agent 设计等实战指南;
- 🧠 理解边界:幻觉、偏见、安全对齐、推理瓶颈与当前能力天花板;
- 🌍 洞察趋势:开源 vs 闭源、端侧部署、MoE 架构、世界模型与 AGI 路径;
- 💼 落地应用:如何在企业中安全、高效、低成本地集成大模型能力。
无论你是想写代码调用 API 的开发者,设计 AI 产品的 PM,评估技术路线的管理者,还是单纯好奇智能本质的思考者,这里都有值得你驻足的内容。 不追 hype,只讲逻辑;不谈玄学,专注可复现的认知。 让我们一起,在这场百年一遇的智能革命中,看得更清,走得更稳 https://cloud.tencent.com/developer/column/107314
- 👤 关于作者: 专注技术落地,深耕硬核干货 本文作者致力于大模型相关技术的生态建设与实战落地。不同于浅层的概念科普,作者坚持 “手算 + 代码” 的深度分享模式,主张通过手动推演理解算法本质,结合生产级代码验证理论可行性。 请关注我主页:https://cloud.tencent.com/developer/user/2276240
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号