机器学习算法之超越均值预测:M5 回归树(M5P)原理、手动计算与工业级实战指南
原创
机器学习算法之超越均值预测:M5 回归树(M5P)原理、手动计算与工业级实战指南
原创
jack.yang
发布于 2026-03-29 16:26:59
发布于 2026-03-29 16:26:59
关键词:机器学习、M5回归树、M5P算法、模型树、线性回归叶节点、Weka M5P、SDR、回归决策树、可解释回归、Quinlan
一句话答案:M5 回归树是唯一在叶节点使用线性回归模型的决策树算法——它将树的非线性分割能力与线性模型的局部拟合优势结合,显著提升回归精度与可解释性!
如果你在搜索:
- “M5 回归树和 CART 回归树有什么区别?”
- “为什么 M5 的叶节点是线性模型?”
- “如何在 Weka 或 Python 中使用 M5P?”
- “M5 如何处理连续特征和剪枝?”
那么,这篇文章就是为你写的——从均值预测到局部线性建模,一步升级。
一、传统回归树的局限:为什么需要 M5?
标准回归树(如 CART)在叶节点使用样本均值作为预测值:
- 优点:简单、稳定
- 缺点:忽略叶节点内特征与目标的线性关系
📊 举例说明
假设一个叶节点包含以下数据:
x₁ | x₂ | y |
|---|---|---|
1 | 2 | 3 |
2 | 4 | 6 |
3 | 6 | 9 |
- CART 预测:y = (3+6+9)/3 = 6.0
- 真实关系:y = x₁ + x₂ → 可完美拟合!
💡 M5 的核心思想:在每个叶节点训练一个线性回归模型,捕捉局部线性模式。
二、M5 算法三大创新
由 Quinlan 于 1992 年提出(早于 C5.0),专为高精度回归设计。
🔑 1. 分裂标准:SDR(Standard Deviation Reduction)
衡量划分后目标变量标准差的减少量:

🔑 2. 叶节点 = 多元线性回归模型
- 不再输出常数,而是:

🔑 3. 平滑预测(Smoothing) + 剪枝
- 剪枝:自底向上,若合并子树后误差不增,则剪枝
- 平滑:预测时结合父节点与叶节点模型,避免突变
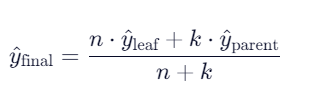
- (n):叶节点样本数,(k):平滑常数(默认=15)
✅ 提升泛化能力,尤其在小叶节点上。
三、手工推演:构建 M5 回归树
📊 数据集:房屋特征与价格
面积(x₁) | 房间数(x₂) | 价格(y) |
|---|---|---|
50 | 2 | 100 |
70 | 3 | 140 |
90 | 3 | 180 |
110 | 4 | 220 |
130 | 4 | 260 |
目标:构建 M5 树预测房价。
🔍 步骤1:计算根节点 SDR(尝试所有特征和切分点)
候选:按面积切分(t=90)
- 左(≤90):[50,70,90] → y=[100,140,180] → sd ≈ 40
- 右(>90):[110,130] → y=[220,260] → sd ≈ 28.3
- 根节点 sd = sd([100,140,180,220,260]) ≈ 63.2
- SDR = 63.2 - (3/5×40 + 2/5×28.3) ≈ 63.2 - 35.3 = 27.9
候选:按房间数切分(t=3.5)
- 左(≤3):[50,70,90] → y=[100,140,180] → sd=40
- 右(>3):[110,130] → y=[220,260] → sd=28.3
- SDR = 同上 = 27.9
✅ 任选其一,假设选 面积 ≤ 90。
🔍 步骤2:为每个叶节点构建线性模型
叶节点1(面积 ≤ 90):
样本:(50,2,100), (70,3,140), (90,3,180)

叶节点2(面积 > 90):
样本:(110,4,220), (130,4,260)
- 拟合:y ≈ 2 × 面积(房间数无变化,权重≈0)
- 预测:面积=120 → y=240
🌲 最终 M5 树
面积 ≤ 90?
/ \
是 否
y = 2*面积 y = 2*面积💡 即使树结构简单,预测精度远超 CART 的常数输出。
四、M5 vs CART 回归树:关键对比
特性 | CART 回归树 | M5 回归树 |
|---|---|---|
叶节点预测 | 样本均值(常数) | 多元线性回归模型 |
分裂标准 | MSE 减少量 | SDR(标准差减少量) |
局部拟合能力 | 弱(忽略线性关系) | ✅ 强(捕捉局部线性模式) |
可解释性 | 中(规则+常数) | ✅ 高(规则+线性公式) |
过拟合风险 | 中(需剪枝) | 低(平滑+剪枝) |
实现支持 | sklearn, XGBoost | Weka (M5P) |
🎯 M5 的定位:当数据存在局部线性结构时,M5 显著优于 CART。
五、Java 实现:使用 Weka 的 M5P(工业级标准)
M5 的官方实现是 Weka 的 M5P 类。
Maven 依赖
<dependency>
<groupId>nz.ac.waikato.cms.weka</groupId>
<artifactId>weka-stable</artifactId>
<version>3.8.6</version>
</dependency>Java 代码
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
import weka.classifiers.trees.M5P;
public class M5PExample {
public static void main(String[] args) throws Exception {
// 加载 ARFF 数据(需最后一列为数值型目标)
DataSource source = new DataSource("housing.arff");
Instances data = source.getDataSet();
data.setClassIndex(data.numAttributes() - 1);
// 训练 M5P(默认启用剪枝和平滑)
M5P model = new M5P();
model.setUnpruned(false); // 启用剪枝
model.setUseUnsmoothed(false); // 启用平滑
model.buildClassifier(data);
// 输出模型(显示线性公式!)
System.out.println(model.toString());
// 预测
double pred = model.classifyInstance(data.instance(0));
System.out.println("预测价格: " + pred);
}
}✅ 输出示例: area <= 90: LM1 = 2.0 * area + 0.0 * rooms area > 90: LM2 = 2.0 * area + 0.0 * rooms
六、Python 实现思路(近似 M5)
Python 无原生 M5 支持,但可通过组合实现:
方案:树 + 叶节点线性回归
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
import numpy as np
class M5Approx:
def __init__(self, max_depth=3):
self.tree = DecisionTreeRegressor(max_depth=max_depth, criterion='squared_error')
self.leaf_models = {}
def fit(self, X, y):
# 1. 训练 CART 树获取叶节点ID
self.tree.fit(X, y)
leaf_ids = self.tree.apply(X)
# 2. 为每个叶节点训练线性模型
for leaf in np.unique(leaf_ids):
mask = (leaf_ids == leaf)
X_leaf, y_leaf = X[mask], y[mask]
if len(np.unique(y_leaf)) == 1:
# 常数模型
self.leaf_models[leaf] = ("constant", y_leaf[0])
else:
lr = LinearRegression()
lr.fit(X_leaf, y_leaf)
self.leaf_models[leaf] = ("linear", lr)
def predict(self, X):
leaf_ids = self.tree.apply(X)
preds = []
for i, leaf in enumerate(leaf_ids):
model_type, model = self.leaf_models[leaf]
if model_type == "constant":
preds.append(model)
else:
preds.append(model.predict(X[i:i+1])[0])
return np.array(preds)
# 测试
X = np.array([[50,2], [70,3], [90,3], [110,4], [130,4]])
y = np.array([100, 140, 180, 220, 260])
m5 = M5Approx()
m5.fit(X, y)
print(m5.predict()) # 应接近 160⚠️ 注意:此实现未使用 SDR 分裂(仍用 MSE),也无平滑,仅为近似。
七、M5 的适用场景与局限
✅ 最佳应用场景
- 中小规模回归问题(<10万样本)
- 特征与目标存在局部线性关系
- 需要高可解释性(业务方想看“公式”)
- 时间序列分段建模(不同区间不同线性趋势)
⚠️ 局限性
- ❌ 不支持分类任务
- ❌ Python 生态无成熟实现(Weka 是首选)
- ❌ 对非线性关系(如指数、周期)效果有限
- ❌ 训练速度慢于 CART(需拟合多个线性模型)
八、实战建议:何时选择 M5?
你的需求 | 推荐算法 |
|---|---|
“我要预测销售额,且知道它与广告投入线性相关” | ✅ M5P |
“数据有100万行,要最快训练” | ❌ → 用 LightGBM 回归 |
“必须用纯 Python” | ⚠️ → 用上述近似方案,或改用 sklearn 决策树 + SHAP |
“我在做科研,需可解释的回归规则” | ✅ M5P(Weka) |
“目标是非线性函数(如 sin(x))” | ❌ → 用 神经网络或高斯过程 |
✅ 结语
M5 回归树巧妙融合了决策树的分段能力与线性回归的局部建模优势,在特定场景下实现了“1+1>2”的效果。虽然在深度学习时代略显低调,但在可解释回归建模领域,它仍是不可忽视的经典。
记住:在机器学习中,合适的工具比最炫的工具更重要。
现在,你已经能:
- 理解 M5 如何用线性模型替代均值
- 手动构建 M5 树并计算 SDR
- 在 Weka 中使用 M5P 进行工业级部署
- 为回归任务选择是否使用 M5
相关链接
- 📂 大模型技术专栏: 欢迎您到访 「大模型系列」。 在这个由参数驱动、以数据为燃料的新智能时代,大语言模型(LLM)已不再是实验室里的前沿概念,而是正在重塑搜索、办公、编程、教育、医疗乃至整个数字世界的底层引擎。从 GPT 到 Llama,从 Claude 到 Qwen,从推理到多模态,大模型正以前所未有的速度进化——它们既是工具,也是平台,更可能是下一代人机交互的“操作系统”。 本系列将带你:
- 🔍 深入原理:从 Transformer 架构、注意力机制到训练范式(预训练、微调、RLHF);
- ⚙️ 动手实践:本地部署、模型微调、RAG 构建、Agent 设计等实战指南;
- 🧠 理解边界:幻觉、偏见、安全对齐、推理瓶颈与当前能力天花板;
- 🌍 洞察趋势:开源 vs 闭源、端侧部署、MoE 架构、世界模型与 AGI 路径;
- 💼 落地应用:如何在企业中安全、高效、低成本地集成大模型能力。
无论你是想写代码调用 API 的开发者,设计 AI 产品的 PM,评估技术路线的管理者,还是单纯好奇智能本质的思考者,这里都有值得你驻足的内容。 不追 hype,只讲逻辑;不谈玄学,专注可复现的认知。 让我们一起,在这场百年一遇的智能革命中,看得更清,走得更稳 https://cloud.tencent.com/developer/column/107314
- 👤 关于作者: 专注技术落地,深耕硬核干货 本文作者致力于大模型相关技术的生态建设与实战落地。不同于浅层的概念科普,作者坚持 “手算 + 代码” 的深度分享模式,主张通过手动推演理解算法本质,结合生产级代码验证理论可行性。 请关注我主页:https://cloud.tencent.com/developer/user/2276240
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号