ICLR | CGFlow:组合生成流用于3D分子生成与合成路径协同设计

ICLR | CGFlow:组合生成流用于3D分子生成与合成路径协同设计

DrugIntel
发布于 2026-03-30 16:10:47
发布于 2026-03-30 16:10:47

论文全称:Compositional Flows for 3D Molecule and Synthesis Pathway Co-design 发表会议:ICLR 2025 作者团队:Tony Shen*、Seonghwan Seo*(共同一作)、Ross Irwin、Kieran Didi、Simon Olsson、Woo Youn Kim、Martin Ester 机构:Simon Fraser University · KAIST · AstraZeneca · Chalmers University · University of Oxford · NVIDIA 代码:https://github.com/tsa87/cgflow
目录
- 1. 研究背景与动机
- 2. 核心问题定义
- 3. 方法论:CGFlow 框架
- • 3.1 数据表示
- • 3.2 组合流(Compositional Flow)
- • 3.3 状态流(State Flow)
- • 3.4 采样算法
- • 3.5 训练目标
- 4. 应用:3DSynthFlow
- • 4.1 状态流模型架构
- • 4.2 组合流模型架构
- • 4.3 动作空间设计
- 5. 实验设置与结果
- • 5.1 口袋特异性优化(LIT-PCBA)
- • 5.2 口袋条件生成(CrossDocked2020)
- • 5.3 采样效率分析
- • 5.4 消融实验
- 6. 理论基础
- 7. 与相关工作的关系
- 8. 局限性与未来方向
1. 研究背景与动机
1.1 药物设计的双重挑战
基于结构的药物设计(Structure-Based Drug Design, SBDD)需要同时满足两个核心目标:
- • 结合亲和力:生成的分子须与靶蛋白口袋形成良好的空间互补和物理化学相互作用(氢键、疏水效应、范德华力等)。
- • 可合成性:生成的分子须能在实验室中通过现有化学反应切实合成,以支撑湿实验验证。
然而,大多数现有生成模型只能顾及其一:
方法类型 | 3D结构建模 | 合成路径建模 | 代表方法 |
|---|---|---|---|
扩散/流匹配模型 | ✅ 强 | ❌ 无 | DiffSBDD, TargetDiff, MolCRAFT |
GFlowNet 合成路径模型 | ❌ 仅2D | ✅ 强 | SynFlowNet, RxnFlow, RGFN |
自回归片段模型 | ⚠️ 有误差累积 | ❌ 无 | Pocket2Mol, FRAG-AR-Diff |
1.2 现有方法的核心局限
扩散/流匹配模型的局限:标准扩散和流匹配对对象的所有维度同时建模,无法对构建步骤加以约束。这导致:
- 1. 无法屏蔽无效的组合动作,组合对象的合法性得不到保证;
- 2. 在组合空间中难以有效进行奖励信用分配(reward credit assignment);
- 3. 生成的分子往往不符合化学合成规则,可合成性极低。
序列模型(如GFlowNet)的局限:
- 1. 当前GFlowNet-based合成分子设计方法均局限于2D分子图,无法感知蛋白质口袋的3D几何;
- 2. 缺乏对连续状态(原子坐标)的精细建模能力;
- 3. 自回归模型存在错误累积问题——早期位置预测的微小偏差会在后续步骤中级联放大。
2. 核心问题定义
2.1 正式定义
给定靶蛋白口袋 ,目标是生成分子 ,其中:
- • :组合结构,即有序的合成单元序列(合成路径)
- • :连续状态,即每个合成单元对应的原子3D坐标
生成过程须使 的奖励函数 (综合结合亲和力与药物性质)最大化,同时保证合成路径的合法性。
2.2 问题的核心难点
将序列化组合建模与连续状态建模统一于一个生成框架,需要解决:
- 1. 不同时刻加入的组合单元,其连续状态的噪声水平应如何协调?
- 2. 如何在GFlowNet的轨迹平衡目标中处理状态流模型引入的随机性?
- 3. 组合动作的采样如何与连续状态的精化过程相互感知?
3. 方法论:CGFlow 框架
3.1 数据表示
对象 的数学形式化:
- • 组合结构 :有序序列 ,第 个单元 在第 步生成轨迹中被加入
- • 连续状态 :,其中 , 为第 个单元的原子数
边界条件:
初始状态 :(空图),(零维)。
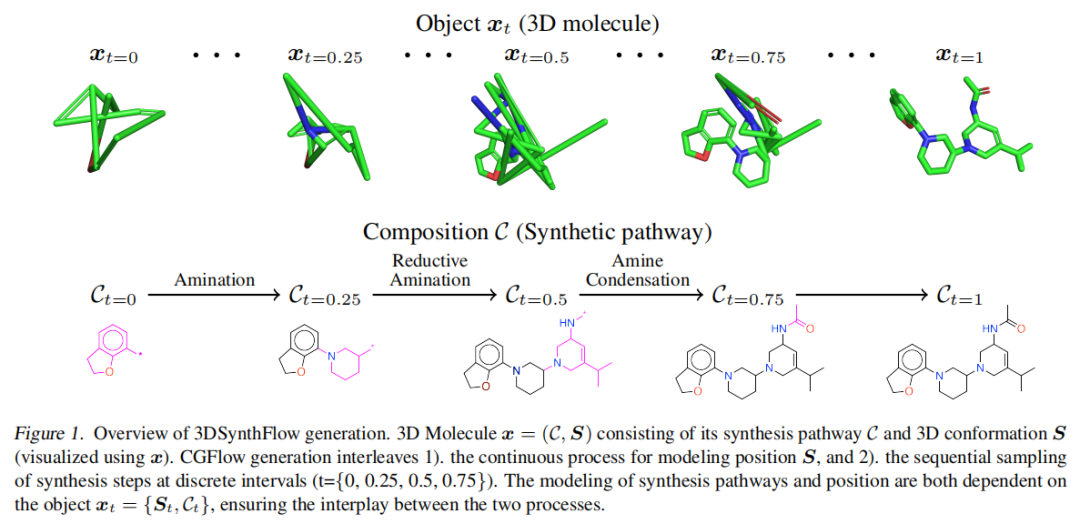
3.2 组合流(Compositional Flow)
核心思想:将组合结构的条件概率流从空图 渐进过渡到完整结构 ,在离散时间点依次加入各个组合单元。
时间函数 ——决定在时刻 已加入的单元数:
其中 为相邻单元间的时间间隔,须满足 。
第 个单元的生成时刻为:
时刻 的组合结构:
与先前工作的区别:Campbell et al. (2023) 使用速率函数对维度转换进行连续建模;本文采用固定离散间隔,保留了自回归生成的优点(简化的似然评估与学习目标)。
3.3 状态流(State Flow)
核心思想:对连续状态 进行条件概率路径建模,通过引入时序偏置(temporal bias)处理不同单元的生成时间差异。
组件局部时间 :
其中 为插值时间窗口, 将值约束于 。
- • :当 ,单元刚被加入,处于最高噪声水平
- • :当 ,插值完成,状态已精化
状态插值(线性插值 + 高斯噪声):
物理直觉:越晚加入的单元,噪声消除的时间越短,模型对其3D位置的不确定性越大,这与分子逐步组装的物理直觉完全一致。此设计借鉴了 Ruhe et al. (2024) 在扩散视频生成中使用的帧级噪声调度策略。
向量场与欧拉步:
状态更新速率:
欧拉方法更新:
其中 为状态流模型 对干净状态的预测。若 ,则直接令 。
3.4 采样算法
采样过程交替执行两个步骤:
初始化: t=0, C_t=∅, S_t=[], Ŝ¹_t=[]
while t < 1:
# 自条件输入
x_t = (C_t, S_t, Ŝ¹_t)
# 1. 组合流:在离散时间点采样新单元
if t mod λ == 0:
C^(i) ~ π_θ(x_t) # 组合流策略
S^(i)_t ~ N(0,1) [固定随机种子] # 初始化新单元状态
x_t = T(x_t, C^(i), S^(i)_t) # 转移函数
# 2. 状态流:预测并更新所有已生成单元的坐标
对所有 j ≤ i:
t^(j)_local = clip((t - t^(j)_gen) / t_window)
Ŝ^(j)_1 = p^θ_{1|t}(x_t, t^(j)_local) # 状态流模型预测
S^(j)_{t+Δt} = S^(j)_t + (Ŝ^(j)_1 - S^(j)_t) · κ^(j) · Δt
t = t + Δt
return x_1自条件(Self-Conditioning)的作用:组合流模型不仅接收当前含噪状态 ,还接收上一步预测的干净状态估计 。这一策略在蛋白-配体相互作用建模中尤为重要(Harris et al., 2023),使模型能基于更清晰的状态估计做出合成决策。
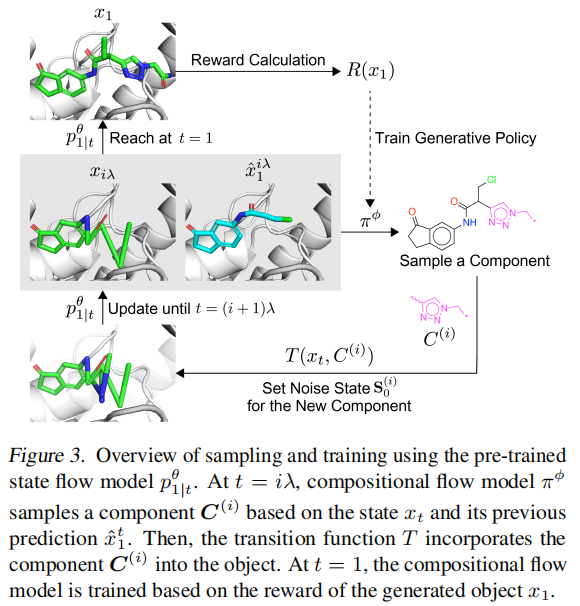
3.5 训练目标
状态流损失(无需模拟,独立训练)
对每个对象 ,先按其组合结构 分配一个生成轨迹,再采样时刻 ,对所有已生成单元的坐标预测计算 MSE 损失。
组合流损失(在线训练,基于 GFlowNet)
基于**轨迹平衡(Trajectory Balance, TB)**目标:
关键推导:由于固定了初始状态的随机种子,状态流模型 ODE 是确定性的,从而对象 被轨迹 唯一确定,大大简化了前向转移概率的估计:
这一关键简化使得 TB 损失中的后向策略项和最终状态项相互抵消(自回归假设 ),得到上述简洁形式。
替代训练目标(无奖励函数时)
当奖励函数不可用或目标为拟合数据分布时,采用交叉熵损失:
4. 应用:3DSynthFlow
4.1 状态流模型架构
基于 SemlaFlow(Irwin et al., 2024)架构,进行以下关键扩展:
分层蛋白质编码(HierSemla)
受 AlphaFold3 启发,提出两级蛋白质编码策略:
- 1. 原子级编码:Semla 层分别编码每个氨基酸残基内的原子类型、键连接和位置
- 2. 残基级聚合:对残基内的不变和等变特征做均值池化,得到残基级嵌入
该策略将全原子分辨率建模的内存复杂度从 ( 为全蛋白原子数,可达2000+)降低到可处理范围,同时保持对精细原子相互作用的感知。
附着点信息嵌入
在原子输入特征中加入布尔特征 IS_ATTACHMENT_POINT,指示当前原子是否为下一个合成单元的连接点,引导模型为未来单元预留空间。
蛋白质-配体注意力层
在每个修改的 Semla 层中,引入蛋白质残基嵌入与配体原子嵌入的跨模态消息传递:
蛋白质-配体消息与配体内消息聚合后用于注意力更新,实现对结合关键相互作用的有效建模。
4.2 组合流模型架构
基于 RxnFlow(Seo et al., 2024)架构改造,以图变换器(Graph Transformer)为骨干:
初始合成单元选择(FirstSynthon):
后续合成单元添加(AddSynthon):
蛋白质以 图表示,配体与所有蛋白节点连接,所有节点对的3D距离编码在图边中,使模型能推理3D空间关系。
动作空间掩码:限制生成分子不超过40个重原子,防止分子量膨胀导致的虚假评分提升。
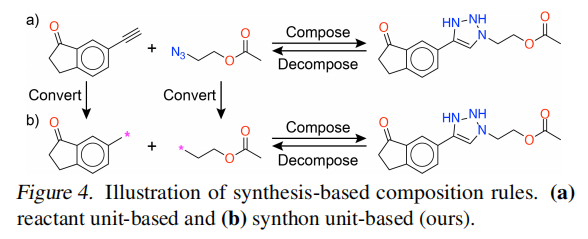
4.3 动作空间设计
采用合成子(Synthon)表示而非反应物(Reactant)表示:
表示方式 | 特点 | 问题 |
|---|---|---|
反应物表示 | 完整的反应物分子 | 离去基团原子在中间态会出现又消失,破坏坐标预测连续性 |
合成子表示(本文) | 去除离去基团的反应中间体 | 每步加入的原子永久保留,与状态流的连续建模完全兼容 |
两类合成子:
- • Brick(砖块):含一个连接点,作为起始单元或终止单元
- • Linker(连接子):含两个连接点,用于连接两个单元
动作空间:
使用 38 条 Enamine 双分子合成协议,限制最多2个合成步骤(对应 Enamine REAL Space)。
5. 实验设置与结果
5.1 口袋特异性优化(LIT-PCBA)
评估设置:
- • 15个 LIT-PCBA 靶标蛋白
- • 每个靶标最多生成64,000个分子
- • 多目标优化:同时优化 UniDock 对接分和 QED
- • 过滤条件:QED > 0.5;结构多样性 Tanimoto 距离 > 0.5
- • 评估指标:前100个多样化模式的平均 Vina 对接分、配体效率、AiZynthFinder成功率、PoseCheck相互作用
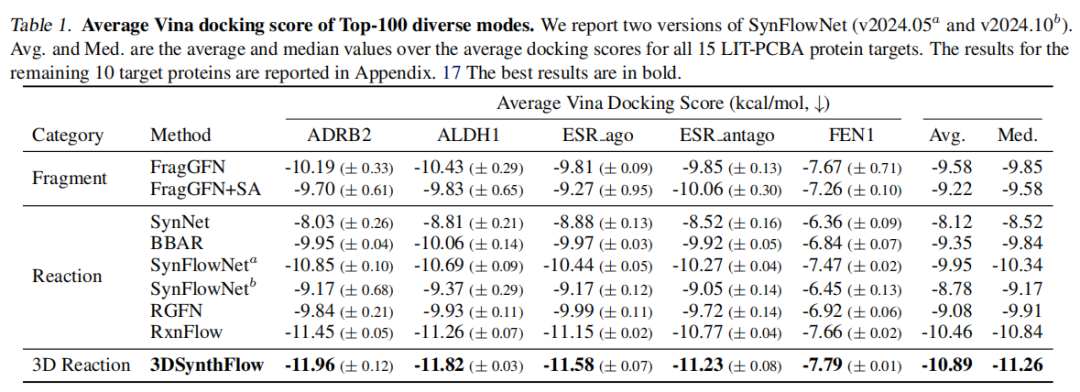
核心结果(部分靶标 Vina 对接分,单位 kcal/mol,越小越好):
方法 | ADRB2 | ALDH1 | ESR_ago | ESR_antago | FEN1 | 平均 |
|---|---|---|---|---|---|---|
FragGFN | -10.19 | -10.43 | -9.81 | -9.85 | -7.67 | -9.58 |
SynFlowNet (v2024.05) | -10.85 | -10.69 | -10.44 | -10.27 | -7.47 | -9.95 |
RGFN | -9.84 | -9.93 | -9.99 | -9.72 | -6.92 | -9.08 |
RxnFlow | -11.45 | -11.26 | -11.15 | -10.77 | -7.66 | -10.46 |
3DSynthFlow | -11.96 | -11.82 | -11.58 | -11.23 | -7.79 | -10.89 |
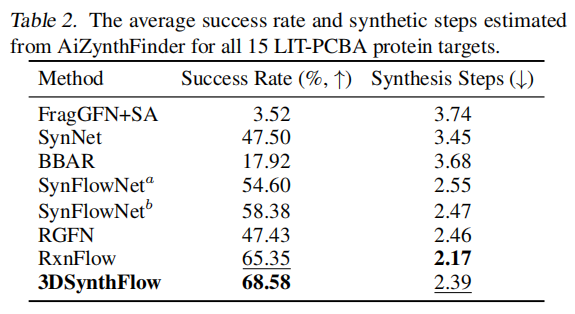
可合成性结果(AiZynthFinder 成功率):
方法 | 成功率 (%) | 平均合成步骤 |
|---|---|---|
FragGFN+SA | 3.52 | 3.74 |
RxnFlow | 65.35 | 2.17 |
3DSynthFlow | 68.58 | 2.39 |
蛋白质-配体相互作用(PoseCheck,前5个靶标均值):
方法 | 氢键受体 | 氢键供体 | 总和 |
|---|---|---|---|
RxnFlow | 0.22 | 0.10 | 0.32 |
3DSynthFlow | 0.33 | 0.17 | 0.50 |
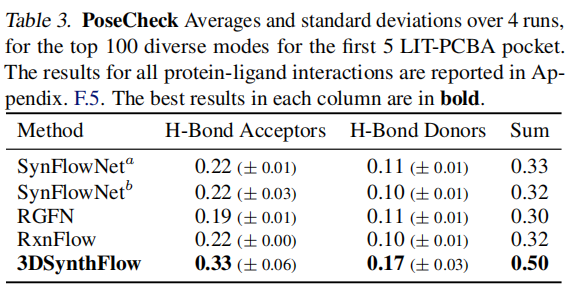
3DSynthFlow 的氢键相互作用数比最优2D基线提升约56%,体现了3D协同设计在精细物理相互作用层面的优越性。
5.2 口袋条件生成(CrossDocked2020)
评估设置:每种方法对100个测试口袋各生成100个分子,使用 CrossDocked 训练集上预训练的代理模型评分。
核心结果:
方法 | Vina 均值 ↓ | QED 均值 ↑ | AiZynth 成功率 ↑ | 多样性 ↑ | 生成时间 ↓ |
|---|---|---|---|---|---|
参考活性分子 | -7.71 | 0.48 | 36.1% | — | — |
MolCRAFT-large | -9.25 | 0.45 | 3.9% | 0.82 | >141s |
RxnFlow | -8.85 | 0.67 | 34.8% | 0.81 | 4s |
3DSynthFlow (low β) | -9.14 | 0.69 | 36.2% | 0.78 | 6s |
3DSynthFlow (med β) | -9.30 | 0.72 | 35.1% | 0.74 | 6s |
3DSynthFlow (high β) | -9.42 | 0.73 | 36.1% | 0.69 | 6s |
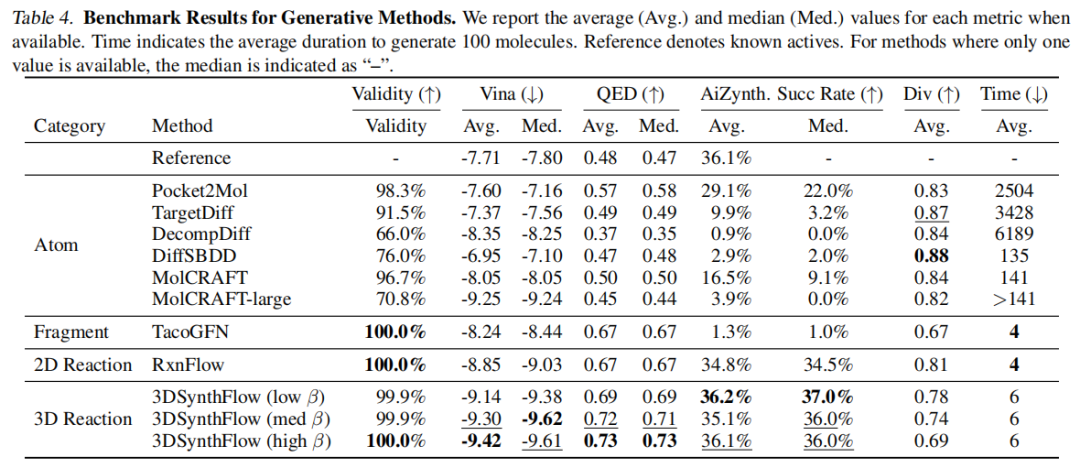
关键对比分析:
- • MolCRAFT-large 的 Vina 分接近 3DSynthFlow(-9.25 vs -9.42),但可合成性仅 3.9% vs 36.1%
- • RxnFlow 可合成性与 3DSynthFlow 接近,但 Vina 分差距明显(-8.85 vs -9.42)
- • 3DSynthFlow 是首个在结合亲和力和可合成性上同时达到参考活性分子水准的生成方法
β 参数控制奖励指数化(探索-利用权衡):low β 鼓励更多探索,high β 偏向高奖励区域集中采样。
5.3 采样效率分析
定义高质量多样化模式:Vina < -10 kcal/mol,QED > 0.5,分子间 Tanimoto 距离 > 0.5。
生成64,000个分子后的发现模式数(前5个靶标均值):
方法 | 1,000 | 5,000 | 10,000 | 30,000 | 64,000 |
|---|---|---|---|---|---|
RxnFlow | 3.8 | 21.7 | 54.6 | 400.6 | 1,062.6 |
3DSynthFlow | 9.6 | 71.2 | 242.4 | 1,520.5 | 4,432.3 |
提升倍数 | 2.5× | 3.3× | 4.4× | 3.8× | 4.2× |
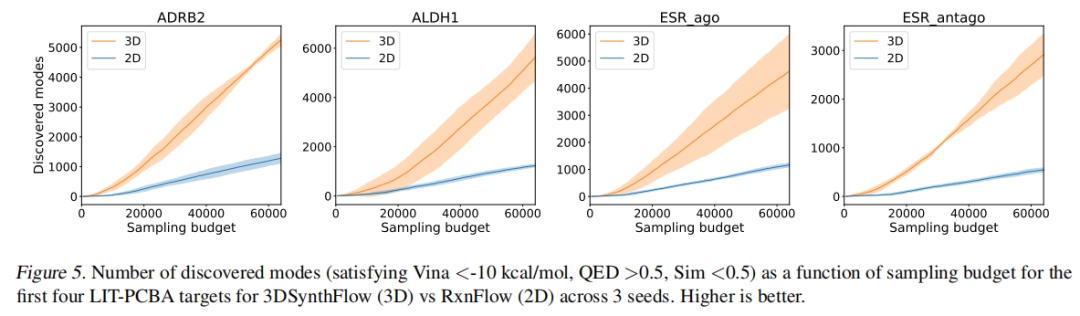
3DSynthFlow 的采样效率优势随采样预算增加而稳定保持,表明3D协同设计显著提升了 GFlowNet 在高价值区域的探索效率,而非仅仅提升了单个分子的质量上限。
5.4 消融实验
时间调度策略消融(ALDH1靶标,局部优化Vina分)
策略 | 参数 | 10,000分子 | 30,000分子 |
|---|---|---|---|
No overlap(严格自回归) | λ=0.33, t_window=0.33 | -6.33 | -7.02 |
Overlapping(部分重叠) | λ=0.30, t_window=0.40 | -7.28 | -7.22 |
Till end(全程联合精化) | λ=0.33, t_window=1.0 | -7.60 | -7.79 |
所有合成单元的坐标持续精化直到 (Till end 策略)显著优于严格自回归方式,表明全局联合精化对解决坐标预测误差累积问题至关重要。
奖励计算方式消融(ALDH1靶标)
方法 | 奖励计算 | Vina 对接分 |
|---|---|---|
RxnFlow | 完整对接 | -11.26 |
3DSynthFlow | 完整对接 | -11.82 |
3DSynthFlow | 局部优化 | -11.44 |
3DSynthFlow(微调pose预测器) | 局部优化 | -11.62 |
即使使用7× 更快的局部优化对接,3DSynthFlow 仍优于2D基线,在计算资源受限场景下具有显著优势。
流匹配步数消融(ALDH1靶标)
流匹配步数 | 平均 Vina | Top-100 Vina | 训练时间(s/iter) | 采样时间(s/mol) |
|---|---|---|---|---|
20 | -8.55 | -12.86 | 16 | 0.058 |
40 | -8.57 | -13.03 | 22 | 0.086 |
60 | -8.84 | -13.50 | 24 | 0.115 |
80 | -8.47 | -13.15 | 27 | 0.153 |
性能在 40–60 步左右趋于饱和,适度增加步数的收益递减。
6. 理论基础
6.1 GFlowNet 基础回顾
GFlowNet 学习一个随机策略,按比例 采样终态 。在有向无环图 上定义流 :
- • 前向策略:
- • 后向策略:
- • 边界条件:,
轨迹平衡(TB)损失(Malkin et al., 2023):
6.2 CGFlow中TB损失的推导简化
由于自回归假设 且状态流 ODE 的确定性(命题B.1),前向转移概率可简化为:
展开 TB 损失,后向策略项 和最终状态的条件概率项 均为1,得到最终的简洁形式(见式10)。
核心洞察:固定随机种子这一技术处理,使状态流模型对GFlowNet而言等价于一个确定性的"世界模型"(world model),从而使 TB 优化在连续-离散混合设置下依然可行。
7. 与相关工作的关系
7.1 方法定位矩阵
方法 | 3D建模 | 合成约束 | 多步组合 | 在线优化 |
|---|---|---|---|---|
TargetDiff / DiffSBDD | ✅ | ❌ | ❌ | ❌ |
MolCRAFT | ✅ | ❌ | ❌ | ❌ |
Fragment AR-Diff(Peng2023) | ✅ | ❌ | ✅(片段自回归) | ❌ |
SynFlowNet / RxnFlow | ❌(仅2D) | ✅ | ✅ | ✅ |
3DSynthFlow | ✅ | ✅ | ✅ | ✅ |
7.2 与片段自回归扩散方法的关键区别
Peng et al. (2023), Ghorbani et al. (2023), Li et al. (2024) 等方法也采用逐片段生成策略,但:
- 1. 坐标固定问题:这些方法在片段生成后固定其原子位置,早期片段的位置误差无法纠正
- 2. 合成约束缺失:片段划分不遵循合成化学规则
- 3. CGFlow的优势:状态流持续精化所有已生成单元的坐标直到 ,同时组合流强制执行合成约束
7.3 与视频扩散(Rolling Diffusion)的联系
Ruhe et al. (2024) 的 Rolling Diffusion 使用帧级噪声调度实现变长序列生成,CGFlow 的 State Flow 将这一思想推广到具有离散组合结构的组合对象,并从理论上与 GFlowNet 的轨迹平衡框架相结合。
8. 局限性与未来方向
8.1 当前局限性
合成动作空间的限制:基于 Arm-and-Linker 合成子的表示目前不支持:
- • 成环反应(ring-forming reactions)
- • 非线性合成路径
这一限制的根本原因是:成环反应会导致中间态合成子的离去基团形成新的环或消失,破坏中间态坐标预测的连续性假设。
Pose预测精度:当前状态流模型有时产生空间碰撞(steric clashes),导致局部优化对接分估计不准,限制了用局部优化替代完整对接的效果。
代理模型精度:口袋条件生成场景下,预训练代理模型的精度限制了奖励信号质量,导致性能提升幅度小于口袋特异性设置。
8.2 未来方向
- 1. 扩展合成动作空间:纳入成环反应模板,增大构建模块库(参考 Sadybekov et al. (2021) 的110亿化合物虚拟库)
- 2. 改进Pose预测模型:提升中间态配体的对接姿态预测精度,减少空间碰撞,使局部优化对接分更可靠
- 3. CGFlow通用框架推广:应用于因果图学习(Nishikawa-Toomey et al., 2024)、材料设计等其他需要组合结构+连续状态联合建模的领域
- 4. 多轮迭代优化:结合主动学习,利用实验反馈迭代提升代理模型质量
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号