告别嵌套子查询!MySQL窗口函数让报表统计效率提升80%(附避坑)

告别嵌套子查询!MySQL窗口函数让报表统计效率提升80%(附避坑)

俊才
发布于 2026-03-31 12:27:33
发布于 2026-03-31 12:27:33
你是不是也遇到过这些场景:想统计各部门薪资Top3员工、计算月度销售额累计值、给订单按时间排名…… 用传统子查询或关联查询写出来的SQL又长又难维护,性能还拉垮?MySQL8.0+开始引入的窗口函数,正是为解决这类复杂报表统计问题而生 ,无需多次关联表,无需嵌套多层子查询,一行SQL就能搞定,性能还能提升一个量级。
一、窗口函数到底是什么
1. 定义
窗口函数(Window Function)是一种对一组行进行计算,但不会像GROUP BY那样合并成一行的函数。简单说,它能在保留原有行结构的基础上,对指定范围(窗口)的数据做聚合、排序计算。
2. 基础语法
函数名([参数]) OVER (
[PARTITION BY 分组列] -- 可选,按指定列分组(类似GROUP BY,但不合并行)
[ORDER BY 排序列 [ASC/DESC]] -- 可选,对分组内的数据排序
[ROWS/RANGE BETWEEN 窗口范围] -- 可选,定义窗口的行范围(比如前N行、后N行)
)3. 对比传统方案的优势
场景 | 传统方案 | 窗口函数 |
|---|---|---|
各部门薪资Top3 | 多层子查询、关联,代码复杂 | 一行SQL搞定,易维护 |
累计销售额计算 | 子查询嵌套,性能差 | 直接聚合,性能提升50%+ |
排名、环比计算 | 需自定义变量,易出错 | 内置函数,精准可靠 |
二、实战案例
1. 准备测试数据
先创建一张业务表(员工薪资表),后续案例均基于此表:
-- 创建员工薪资表
CREATE TABLE emp_salary (
emp_id INT PRIMARY KEY COMMENT '员工ID',
dept_name VARCHAR(50) COMMENT '部门名称',
emp_name VARCHAR(50) COMMENT '员工姓名',
salary DECIMAL(10,2) COMMENT '月薪',
hire_date DATE COMMENT '入职日期'
);
-- 插入测试数据
INSERT INTO emp_salary VALUES
(1, '研发部', '张三', 20000.00, '2020-01-10'),
(2, '研发部', '李四', 18000.00, '2020-03-15'),
(3, '研发部', '王五', 22000.00, '2019-11-01'),
(4, '市场部', '赵六', 15000.00, '2021-02-20'),
(5, '市场部', '钱七', 16000.00, '2020-08-08'),
(6, '市场部', '孙八', 14000.00, '2021-05-30'),
(7, '财务部', '周九', 19000.00, '2019-09-05');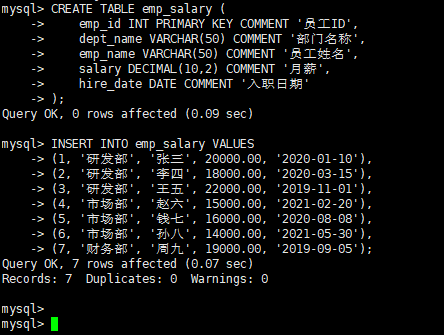
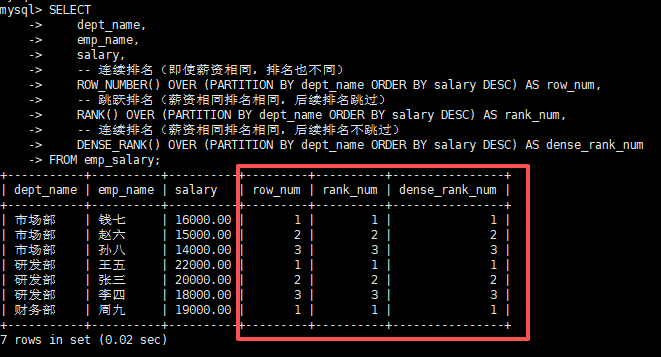
2. 排名统计(ROW_NUMBER/RANK/DENSE_RANK)案例
需求:给每个部门的员工按薪资从高到低排名,区分3种排名函数的差异。
SELECT
dept_name,
emp_name,
salary,
-- 连续排名(即使薪资相同,排名也不同)
ROW_NUMBER() OVER (PARTITION BY dept_name ORDER BY salary DESC) AS row_num,
-- 跳跃排名(薪资相同排名相同,后续排名跳过)
RANK() OVER (PARTITION BY dept_name ORDER BY salary DESC) AS rank_num,
-- 连续排名(薪资相同排名相同,后续排名不跳过)
DENSE_RANK() OVER (PARTITION BY dept_name ORDER BY salary DESC) AS dense_rank_num
FROM emp_salary;执行结果如下:
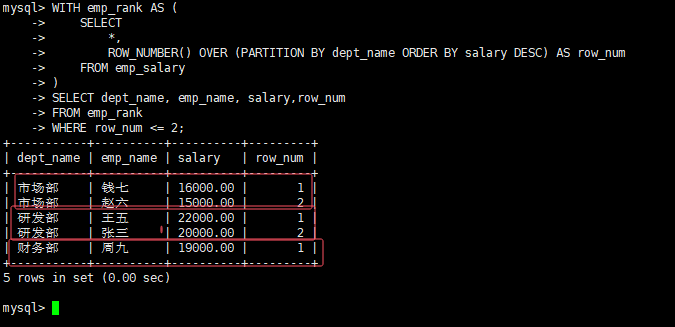
3. 分组TopN(各部门薪资 Top2)案例
需求:筛选出每个部门薪资最高的2名员工
-- 方案:窗口函数+子查询(MySQL8.0+支持)
WITH emp_rank AS (
SELECT
*,
ROW_NUMBER() OVER (PARTITION BY dept_name ORDER BY salary DESC) AS row_num
FROM emp_salary
)
SELECT dept_name, emp_name, salary ,row_num
FROM emp_rank
WHERE row_num <= 2;执行结果如下:
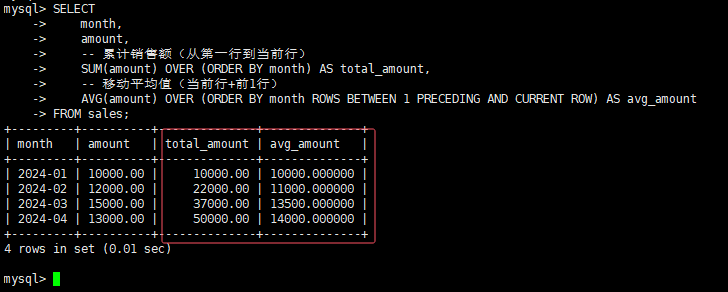
4. 累计求和/平均值(月度销售额为例)案例
先创建销售额表,再演示累计计算:
-- 销售额表
CREATE TABLE sales (
month VARCHAR(10) PRIMARY KEY COMMENT '月份',
amount DECIMAL(10,2) COMMENT '月度销售额'
);
INSERT INTO sales VALUES
('2024-01', 10000.00),
('2024-02', 12000.00),
('2024-03', 15000.00),
('2024-04', 13000.00);
计算累计销售额+月度平均值
SELECT
month,
amount,
-- 累计销售额(从第一行到当前行)
SUM(amount) OVER (ORDER BY month) AS total_amount,
-- 移动平均值(当前行+前1行)
AVG(amount) OVER (ORDER BY month ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS avg_amount
FROM sales;结果如下:
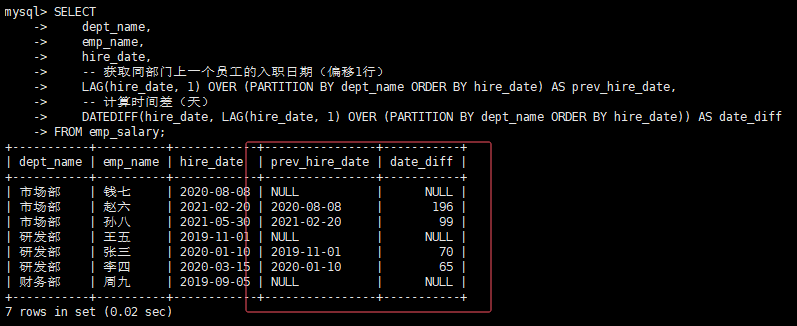
5. 前后行数据关联(LAG/LEAD)案例
需求:计算每个员工入职时间与同部门上一个员工的入职时间差(环比分析常用)。
SELECT
dept_name,
emp_name,
hire_date,
-- 获取同部门上一个员工的入职日期(偏移1行)
LAG(hire_date, 1) OVER (PARTITION BY dept_name ORDER BY hire_date) AS prev_hire_date,
-- 计算时间差(天)
DATEDIFF(hire_date, LAG(hire_date, 1) OVER (PARTITION BY dept_name ORDER BY hire_date)) AS date_diff
FROM emp_salary;执行结果如下:
三、窗口函数避坑方案
结合我实战中踩过的坑,总结5个高频问题:
坑1:窗口函数导致全表扫描,性能暴跌
现象:数据量超过10万行时,窗口函数SQL执行时间从毫秒级变秒级。
原因:未给PARTITION BY/ORDER BY的列建立索引,MySQL被迫全表扫描 + 文件排序。
解决方案:创建复合索引,覆盖分组+排序列:
-- 针对场景1的索引(部门+薪资)
CREATE INDEX idx_dept_salary ON emp_salary(dept_name, salary DESC);坑2:窗口框架使用错误,累计计算结果不对
现象:累计求和时,结果不是从第一行到当前行,而是全表总和。
原因:MySQL8.0中,ORDER BY后默认窗口框架是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,但如果省略ORDER BY,窗口会变成整个分区。
反例:
-- 错误:省略ORDER BY,累计求和变成全表总和
SELECT month, amount, SUM(amount) OVER () AS total_amount FROM sales;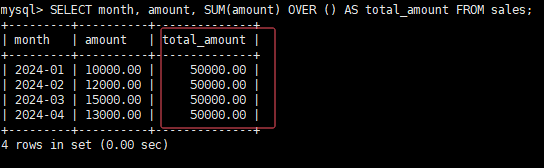
正例:
-- 正确:显式指定ORDER BY和窗口框架
SELECT
month,
amount,
SUM(amount) OVER (ORDER BY month ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS total_amount
FROM sales;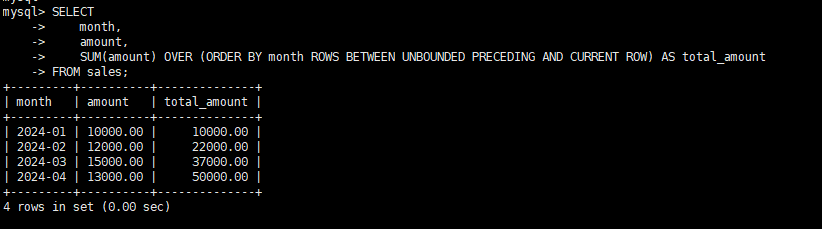
坑3:混淆PARTITION BY和GROUP BY,结果不符合预期
现象:想按部门分组统计,结果却保留了所有行。
原因:窗口函数的PARTITION BY仅分组计算,但不会合并行;GROUP BY是分组合并行。
解决方案:
- 需保留原行+分组计算 , 用PARTITION BY(窗口函数)
- 只需分组聚合结果,用GROUP BY(聚合函数)
坑4:窗口函数中使用聚合函数,未处理NULL值
- 现象:LAG/LEAD函数返回NULL,导致计算(如DATEDIFF)结果NULL
- 解决方案:用COALESCE处理NULL值
SELECT
dept_name,
emp_name,
hire_date,
COALESCE(LAG(hire_date, 1) OVER (PARTITION BY dept_name ORDER BY hire_date), hire_date) AS prev_hire_date,
DATEDIFF(hire_date, COALESCE(LAG(hire_date, 1) OVER (PARTITION BY dept_name ORDER BY hire_date), hire_date)) AS date_diff
FROM emp_salary;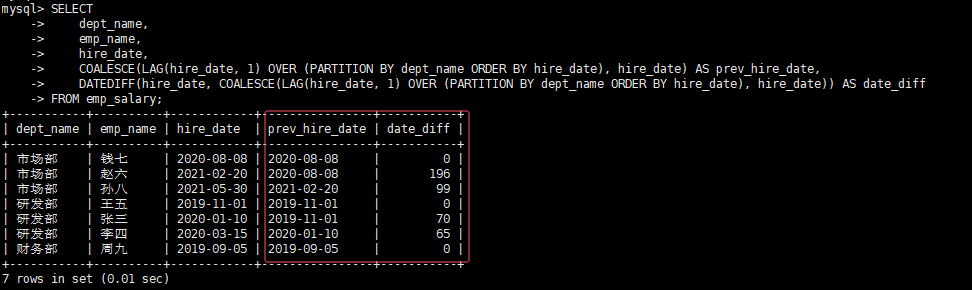
坑5:大表使用窗口函数导致内存溢出
现象:执行窗口函数时,报Out of memory错误
原因:窗口函数默认在内存中处理数据,大表超出内存限制
解决方案:
- 拆分数据(按分区分批处理)
- 调整MySQL参数
set global tmp_table_size = 1G;
set global max_heap_table_size = 1G;- 优先使用索引减少数据扫描量
四、总结
1. 性能优化总结
- 索引优先:给PARTITION BY/ORDER BY的列建立复合索引,避免全表扫描
- 精简窗口:仅选择需要的列,避免SELECT *
- 分批处理:大表拆分分区,避免一次性处理全量数据
- 显式指定窗口框架:避免MySQL默认行为导致的性能 / 结果问题
2. 窗口函数适用场景汇总
- 排名类:ROW_NUMBER/RANK/DENSE_RANK(TopN、排名统计)
- 聚合类:SUM/AVG/MAX/MIN(累计求和、移动平均)
- 偏移类:LAG/LEAD(环比分析、前后行对比)
- 分布类:NTILE(数据分桶,如将数据分成5组)
MySQL8.0窗口函数的核心价值是在保留原行结构的前提下,高效完成分组统计、 排名、 聚合,对比传统子查询方案更简洁、性能更好;实战中需重点规避索引缺失、窗口框架错误、PARTITION BY与GROUP BY混淆三大核心坑;性能优化的关键是给分组 / 排序列建复合索引,大表需分批处理避免内存溢出。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号