斯坦福引爆AI革命:Claude学会自己搞科研,写代码、跑实验、还能进化!

斯坦福引爆AI革命:Claude学会自己搞科研,写代码、跑实验、还能进化!

天意生信云
发布于 2026-03-31 15:51:29
发布于 2026-03-31 15:51:29
当AI不仅能提出想法,还能亲手把想法变成现实,并从失败中学习进化,科研的范式正在被悄然改写。
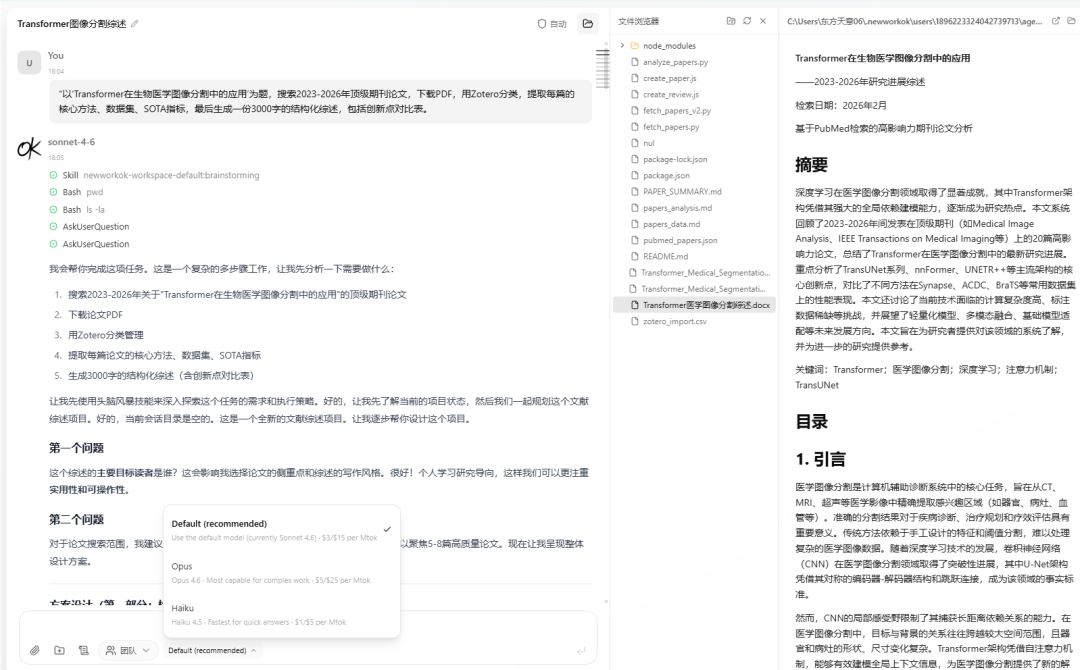
想象一下,让AI自己提出科研想法、写代码实现、跑GPU实验验证效果,然后从结果中学习改进——这听起来像科幻小说?斯坦福团队偏偏把它做出来了。
这可不是什么玩具项目,他们选的“考场”是两个最烧钱、最硬核的AI研究方向:大模型预训练和后训练。真刀真枪,烧的是实实在在的GPU算力。
01.问题到底出在哪?
当前的大模型,生成研究想法听起来头头是道,但往往经不起实践的检验。就像一个军事理论家,在地图上排兵布阵说得天花乱坠,一旦真上了战场,可能连最基本的战术队形都维持不住。
之前就有研究通过人类专家评审发现,LLM生成的研究想法,看着靠谱的比例可能高达70%以上,但真正能落地执行、并且效果超越基准方法的,凤毛麟角。问题就出在“执行落地”这个环节的缺失。想法停留在纸面,没有经过真实实验环境的“淬火”,其价值就大打折扣。
02.核心创新:把“闭环”跑通
这篇论文最核心的思路,叫做 “执行落地”。
他们不再满足于让AI当一个只会空想的“谋士”,而是要把它培养成一个能上战场的“将军”。想法你提,代码你写,实验你跑,结果你分析,下一轮改进方向还是你来定。
研究团队搭建了一套完整的自动化执行系统,核心目标就是把 “想法 -> 实现 -> 验证 -> 改进” 这个科研闭环彻底跑通,并且是大规模并行化地跑。
成果有多猛?咱们看数据:
- 在后训练任务上:他们让AI在MATH数学数据集上微调模型。一开始的基准方法准确率只有48%。经过几轮“进化搜索”,AI自己找到的方法,把准确率干到了69.4%。这个成绩甚至超过了斯坦福CS336研究生课程里最强学生的手动方案(68.8%)。AI在无人干预的情况下,自学成才,打败了顶尖学府的优秀人类。
- 在预训练任务上:任务是在有限时间内训练一个小型GPT模型,目标是尽快达到指定的性能损失(loss)。基准方法需要35.9分钟。AI进化出的方案,将训练时间压缩到了19.7分钟,几乎减半。虽然距离人类专家精心调优的2.1分钟还有巨大差距,但它证明了这条路完全可行——AI确实能通过自动实验来优化复杂的训练过程。
03.前人栽树,后人如何乘凉?
在讨论斯坦福这个工作具体怎么做的之前,我们先看看这个领域的前辈们已经打下了哪些基础。
1. AutoML 老前辈们
自动化机器学习领域探索已久。比如神经架构搜索,就像让AI在一个乐高零件库里,用强化学习自动拼接出性能最好的网络模型。最近也有团队尝试让LLM直接提议网络架构并验证。但这些方法通常有两个局限:一是搜索空间受限,只能在预设好的操作集合里选(比如只能换这几类激活函数,加那几种层);二是更偏向工程性的超参数调优,而非开创性的算法设计。
2. LLM研究助手新秀们
已经出现了一些端到端的AI研究智能体,能完成从文献阅读、想法生成到代码实现的全流程。但它们往往没有深入解决一个关键问题:如何从实验执行的反馈中,系统性地提升“想法”本身的质量?另一边,一些基准测试主要评估的是机器学习工程任务,比如特征工程、调参,而斯坦福这项工作瞄准的是更开放、更根本的算法研发问题。
3. 代码执行反馈的启发
在代码生成领域,大家早就发现,让模型看到自己写的代码运行报错后,它下次就能写得更好。这篇论文把这个“执行反馈”的思路,迁移到了科研想法生成这个更高阶的任务上。但挑战也指数级增加了:验证一个想法的成本不再是运行一个脚本几秒钟,而是可能需要在GPU集群上训练模型好几个小时;反馈信号也不再是简单的“对/错”或报错信息,而是复杂的性能指标曲线和最终的准确率/损失值。
04.核心方法:为AI研究员打造“全自动实验室”
斯坦福团队是怎么实现这个宏伟目标的呢?关键在于搭建了一个三层结构的自动化执行系统,相当于给AI研究员配齐了从代码开发到实验运维的整个团队。
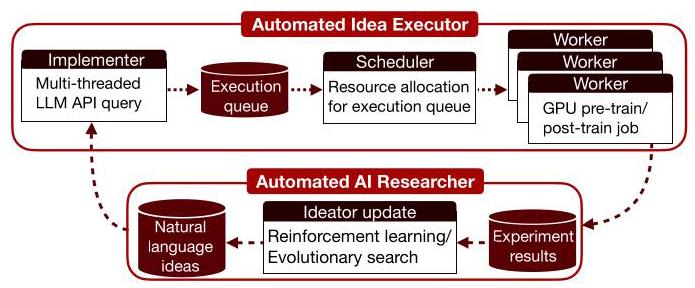
第一层:Implementer(代码实现工程师)
- 岗位:跑在CPU服务器上。
- 职责:接收AI用自然语言描述的研究想法(比如:“我们试试用动态调整学习率的方法来替代固定的衰减策略”)。
- 工作流:调用一个强大的代码生成LLM(比如GPT-5),让它根据这个想法,生成一个“代码diff文件”。这个文件只描述需要对现有基础代码做哪些修改。
- 容错机制:为了提高成功率,它会并行生成10个不同版本的代码修改方案。如果某个版本无法成功合并到基础代码中(比如有语法错误或逻辑冲突),系统会捕获报错日志,让模型自己看错误信息,然后尝试修复,最多重试2次。
- 交付:成功后,将修改好的完整代码打包,上传到云端仓库。
第二层:Scheduler(资源调度管家)
- 岗位:中间管理层。
- 职责:像监工一样定期扫描云端仓库,看看有没有新的代码包提交上来。一旦发现新任务,就根据实验需求(需要多少GPU、预计跑多久)准备配置。它的核心任务是高效利用昂贵的GPU资源,只要发现有GPU空闲,立刻就把排队的实验任务分配上去。
第三层:Worker(实验执行工人)
- 岗位:奋战在GPU集群一线。
- 职责:领到配置和代码包后,吭哧吭哧开始训练模型。实验跑完后,它负责把一切记录在案:训练过程中的损失曲线、最终的准确率、GPU使用情况等所有日志和性能指标,连同完整的元数据(最初的想法描述、具体的代码变更、执行日志),全部上传到实验管理平台(如wandb)。
- 反馈闭环:如果实验执行失败(比如中途崩溃),Worker会详细记录错误信息,这些信息将成为宝贵的反馈,送回给提出想法的AI模型,帮助它理解哪里出了问题。
两大硬核“考场”
光有团队不行,还得有合适的实战环境。他们设置了两个极具挑战性的场景:
- 预训练环境(基于nanoGPT改造):
- 任务:在FineWeb数据集上,预训练一个1.24亿参数的“迷你版”GPT-2模型。
- 目标:在固定的25分钟训练时间内,让模型达到尽可能低的验证损失。他们设计了一个“代理奖励”:奖励 = 1 / 损失。损失越低,奖励越高。
- 防作弊:所有评估用的超参数全部冻结,防止AI通过“偷看”测试数据或调整评估方式来“刷分”。他们还实现了一个严格的token-by-token预测函数,杜绝了任何预测未来信息取巧的可能性。
- 后训练环境(基于GRPO算法):
- 任务:在MATH数学数据集上,微调一个150亿参数的Qwen2.5数学大模型。
- 目标:在固定训练预算下,最大化模型在MATH验证集上的解题准确率。
- 防作弊:验证准确率计算的代码被单独存放,且对自动执行系统只读不可写,从根本上杜绝了AI直接修改评估代码来伪造成绩的可能。
05.进化搜索:让AI想法“适者生存”
有了实验室,怎么让AI的想法越变越好呢?研究团队借鉴了生物进化的思想,设计了一套“进化搜索”算法。
算法核心(模拟 Algorithm 1 的逻辑):
- 第一轮(Epoch 0):广撒网。让AI模型生成一批全新的、随机的想法,作为进化的初始“种群”。
- 后续轮次:每一轮,想法的生成被拆分成两种策略,平衡“探索”与“利用”:
- 利用:从历史上所有跑过的实验中,筛选出那些表现超过基准线的“优秀想法”。然后让AI模型去分析:“这些成功案例有什么共同优点?能不能把它们组合起来,生成一个继承优点的新变种?” 这就像利用已有的成功经验进行微创新。
- 探索:随机选取一些历史上的想法(不管好坏),作为背景信息喂给模型,但要求它:“忽略这些,去想一个完全不同的新点子!” 这是为了跳出局部最优,寻找潜在的突破性方向。
- 动态调整:初期,探索和利用各占50%,鼓励多尝试新方向。随着轮次增加,逐渐降低探索的比例,更专注于优化已有的好方向。这种策略类似于“模拟退火”,先高温扰动寻找全局可能,再慢慢冷却进行局部精修。
- 规模:在后训练环境,每轮生成并测试50个新想法;在更复杂的预训练环境,每轮测试80个想法。这需要庞大的GPU算力支持并行实验。
06.强化学习:更激进的“定向培养”
除了进化搜索,他们还尝试了一种更“激进”的方法:直接用强化学习来训练AI研究员模型本身。
- 设置:他们微调了一个300亿参数的Qwen3模型。每次只给它一个任务描述(比如“优化GRPO算法在MATH上的表现”)。
- 训练:模型输出一个想法(附带它的思考链),这个想法被送去执行实验。
- 奖励:实验成功,得到的准确率(或1/损失)就是给模型的奖励信号;实验失败,奖励为0。
- 目标:通过强化学习,直接调整模型参数,让它未来生成能获得更高奖励的想法。这相当于对AI研究员进行“绩效导向”的定向培训。
07.实验结果:惊喜、瓶颈与启示
1. 基准测试:执行率惊人地高
首先,他们测试了最基本的模式:让同一个模型(如Claude-4.5)既提想法,又写代码实现(自我执行模式)。
- 结果:Claude-4.5-Opus和Sonnet两个版本,想法能被成功执行的比例都超过了90%!这说明顶尖模型已经具备了很强的“动手能力”。
- 效果:哪怕只是从生成的50个想法里挑最好的那个(Best-of-50),其性能就能轻松打败人类设置的基准线。例如,Claude-4.5-Sonnet在GRPO任务上,单轮最佳想法就能把准确率从48%提升到60.4%。
2. 进化搜索:有效,但并非万能
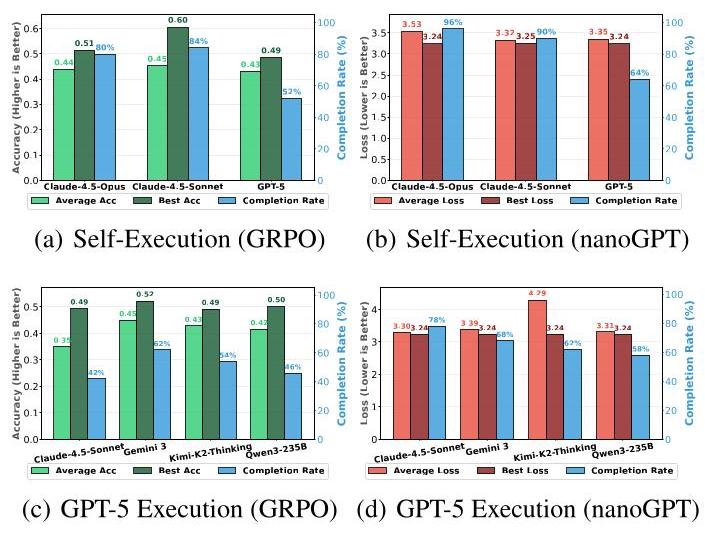
- 成功典范(Claude-4.5-Opus):在两个任务上都展现出清晰的“进化”趋势——搜索轮次越多,找到的最佳方案性能越好。在nanoGPT任务上,第9轮找到了将训练时间压缩到19.7分钟的方案。
- 高开低走(Claude-4.5-Sonnet & GPT-5):Sonnet在GRPO任务上,第2轮就爆发出惊人潜力,找到了准确率69.4%的顶级方案(它发现了一种比标准GRPO更有效的策略梯度变体)。但此后就陷入了瓶颈,性能不再提升。GPT-5也表现出类似的早期提升后平台期的现象。
- 完胜随机采样:在消耗相同总实验次数(即相同算力成本)的前提下,进化搜索从第一轮开始,找到的最佳方案就明显优于简单的“生成一堆想法然后挑最好”的策略。这证明模型确实在利用历史实验的反馈信息来指导新想法的生成。
3. 想法质量分析:AI不止会调参
很多人担心AI科研就是高级调参。但分析发现,事实并非如此。
模型 (GRPO环境) | 超参数想法占比 | 算法想法占比 | 最佳性能来源 |
|---|---|---|---|
GPT-5 | 5.0% | **95.0%** | 算法想法 |
Claude-4.5-Sonnet | 41.1% | 58.9% | **超参数想法** |
Claude-4.5-Opus | 3.7% | **96.3%** | 算法想法 |
三个模型都生成了大量涉及算法核心逻辑修改的创新想法,而不仅仅是调学习率、改批量大小这些参数。
- Claude-4.5-Opus(数学理论派):提出了“带动量边界的残差比率学习”。它把策略更新中的重要性采样比率分解成基础部分和残差部分,只对残差做约束,让基础部分能灵活捕捉策略的整体漂移。这个颇具理论深度的想法取得了61.6%的准确率。
- Claude-4.5-Sonnet(直觉实用派):提出了“动态数学问题难度平衡”。让模型根据自己近期的解题表现,动态调整训练数据的难度分布——做得好了就多给难题挑战,遇到困难了就多给基础题巩固。这个非常符合人类教学直觉的想法,取得了64.0%的准确率。
- GPT-5(工程优化派):提出了“通过响应分块进行Token级比率去噪”。把模型生成的整个回答切分成若干块,用每块的平均对数比率来代替每个token的精细值,从而减少噪声,稳定训练。这个偏向工程优化的想法取得了58.2%的准确率。
最令人惊讶的发现是:这些模型在没有接入任何最新论文数据库(RAG) 的情况下,多次独立提出了与最近三个月内顶级学术会议(如NeurIPS、ICLR)上发表的论文高度相似甚至核心思想一致的算法。例如,Sonnet提出的“响应多样性奖励”与Li等人2025年的工作几乎一样;Opus提出的“因果上下文压缩”对应了Allen-Zhu 2025年论文中的“规范层”概念。这仿佛暗示,顶尖AI模型通过海量文本训练,已经内化了一种“科研直觉”,能够触及当前研究前沿的共识方向。
4. 强化学习的困境:学会了“摸鱼”,丢掉了“灵光”
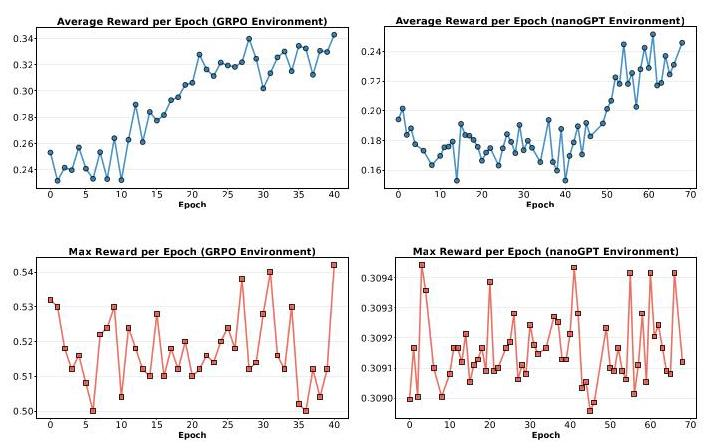
用强化学习训练AI研究员,结果有些矛盾:
- 好消息:模型生成想法的平均奖励确实稳步上升。在GRPO环境中,平均奖励(对应准确率)从0.253提升到了0.343。
- 坏消息:模型能产生的最高奖励(即最佳想法) 却在波动中停滞,没有显示出上升趋势。对于科研创新,我们最渴望的恰恰是那个“突破性的最高分”,而不是整体平均分的提升。
为什么会这样?深度分析揭示了强化学习在科研创新场景的固有缺陷:
- 思考链崩溃:研究发现,随着强化学习训练进行,模型生成的“思考过程”长度急剧缩短,但最终“想法”本身的长度没变。模型学会了走捷径:它发现,更长的、更复杂的思考过程,往往对应着更复杂、更容易执行失败的想法。而简短的思考,却能产生一些简单、稳定、总能拿到一些基础奖励的想法。于是,模型“学乖了”,开始“偷懒”,减少深度思考。
- 多样性崩塌与模式坍塌:
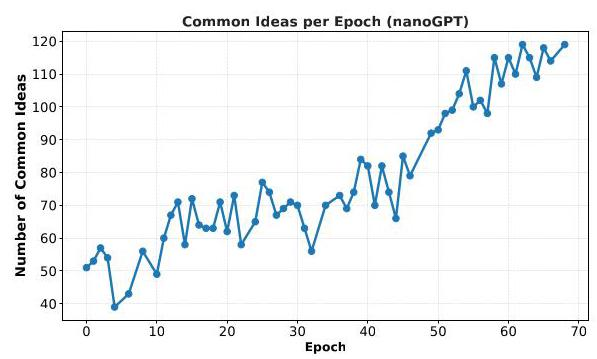
在nanoGPT任务中,初期想法五花八门。但训练到后期,超过90%的想法都收敛到了两三个简单套路上,比如“把这里的LayerNorm换成RMSNorm”或者“在那里加一个指数移动平均”。模型找到了它的“舒适区”,不再愿意冒险尝试可能失败、但也可能带来突破的新奇想法。标准的强化学习目标(最大化期望奖励)本质上是在鼓励保守和重复,而非探索与创新。
- 探索激励缺失:科研的本质需要“冒险”。但标准的GRPO算法没有内置的探索机制。模型一旦找到几个能稳定得分的“安全牌”,它的策略就会迅速固化,失去探索未知领域的动力。
研究团队也尝试过一些补救措施,比如在奖励中加入对想法长度的鼓励、对想法相似度的惩罚等,以期维持多样性,但在初步尝试效果不明显后便暂停了这些探索。这恰恰说明了,如何将“探索”有效融入AI驱动的研究流程,是一个亟待解决的核心难题。
09.🚀 如何使用原生正版Claude?
Claude性能虽强,但是要想用上主要有两大难题,价格贵以及容易封号,特别是opus模型极难获取到使用途径,这边给大家安利一个基于Claude模型开发的ai桌面工具。
为什么推荐他?
1.基于原生正版Claude性能,可自由选择最新版opus4.6、sonnet4.6和haiku4.6模型
2.配套100+完全免费科研通用skills技能包和mcp
3.无需配置复杂的环境和地缘网络限制,上手即用
4.可本地处理文件和代码,只需一条指令,自动完成任务放在桌面
图片
第 1 步:打开 OKAI 官网:dafoai.com
第 2 步:选择 NewWorkOK 套餐并下载桌面版客户端(支持Windows和mac系统)
无需复杂配置,只需安装即可完成 ✅
第 3 步:在聊天框输入系统指令获取分析结果
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号