没产品没收入,投资人又给了 10 亿美金

没产品没收入,投资人又给了 10 亿美金

数据微光
发布于 2026-03-31 18:12:16
发布于 2026-03-31 18:12:16
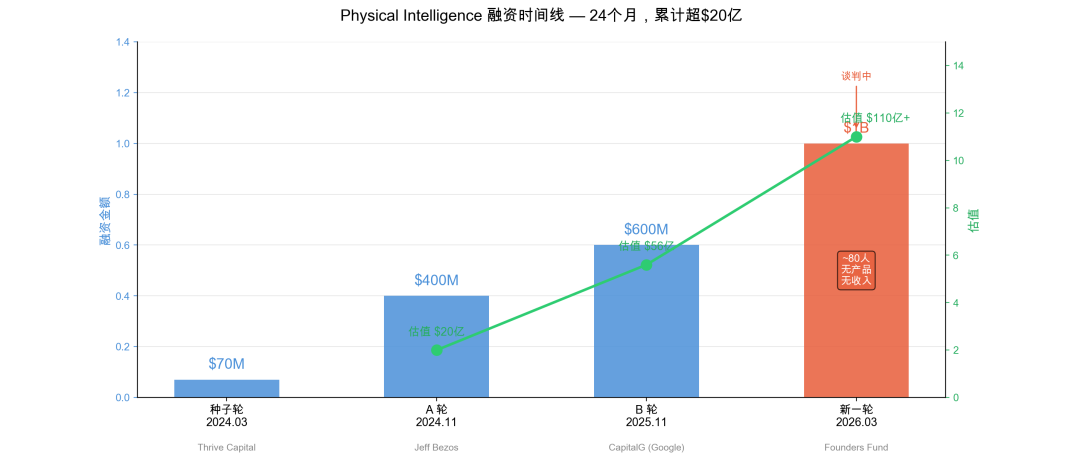
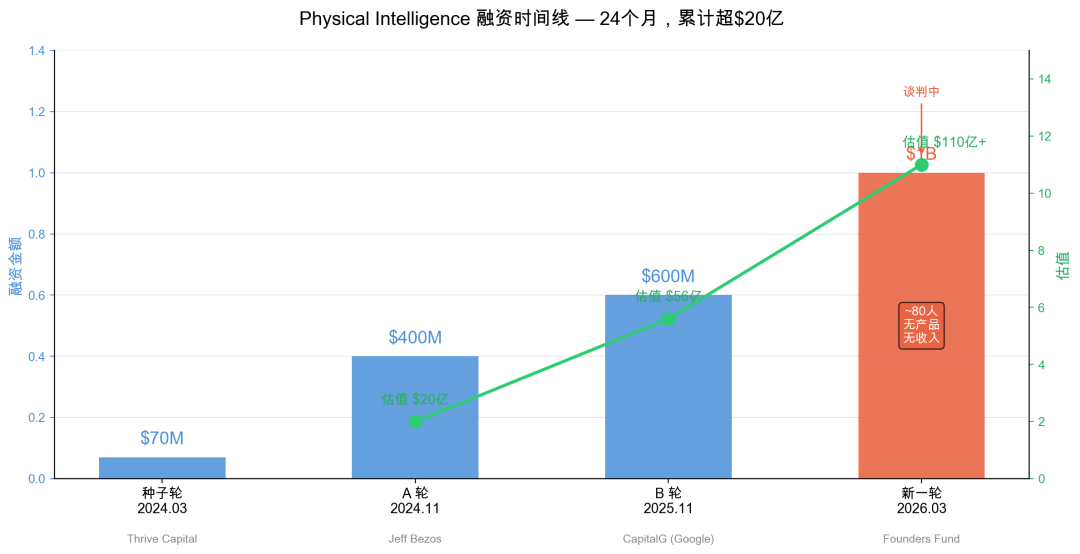
Bloomberg 3 月 28 日的消息,Physical Intelligence 正在谈新一轮融资,10 亿美金,估值超过 110 亿。
上一轮是去年 11 月,6 亿美金,估值 56 亿。四个月,翻了一倍。
之前写过一篇 PI 的公司画像,创始团队和技术路线聊得比较细了。今天换个角度,就聊一件事:这钱为什么给得出去?
先看数字
轮次 | 时间 | 金额 | 估值 | 领投 |
|---|---|---|---|---|
种子轮 | 2024.03 | $70M | — | Thrive Capital |
A 轮 | 2024.11 | $400M | $20 亿 | Jeff Bezos |
B 轮 | 2025.11 | $600M | $56 亿 | CapitalG, Google 旗下 |
新一轮 | 2026.03, 谈判中 | $1B | $110 亿+ | Founders Fund |
如果这轮 close,PI 累计融资超过 20 亿美金。
团队 80 人左右。没有产品。没有收入。没有商业化时间表。
联合创始人 Lachy Groom 接受采访说了一句话:There's no limit to how much money we can really put to work. 钱永远不够花,因为永远有更多算力可以投。
投资人在赌什么
110 亿美金,放在具身智能赛道是什么概念?
宇树前阵子交了上市申请,估值大概在 80 亿美金出头。宇树有产品,Go2、B2 机器狗,有收入,2025 年营收 4.6 亿美元,有出货量。
PI 什么都没有。但估值比宇树还高。
这说明投资人赌的不是今天的产品,是一个位置。
PI 的逻辑和 2020 年的 OpenAI 一模一样:先不管商业化,全力把基座模型做到足够好。谁先做出通用的机器人基础模型,后面所有机器人公司都得来买大脑。
区别是什么呢。OpenAI 2020 年有 GPT-3,证明语言模型的 scaling law 成立了。PI 需要证明同样的事情在物理世界也成立。
他们正在证明。
四个月里发生了什么
从 B 轮(2025.11)到现在,PI 发了三篇研究:
π*0.6(2025.11):给 π0 加了强化学习。以前模型只会模仿人类示范,现在能自己练习、自己进步。核心成果:任务完成效率翻倍。
MEM(2026.03):多尺度记忆系统。之前模型只能处理几十秒的任务,MEM 让它能记住前面发生了什么,持续执行超过 10 分钟的复杂任务。
RL Token(2026.03):从 VLA 模型里提取一个 token 做快速在线强化学习。只需要 15 分钟的实际操作数据,就能大幅提升新任务上的精细表现。

三篇论文,三个具体瓶颈被突破。不是在实验室刷指标,是在真实机器人上跑通的。
这大概就是估值能翻倍的原因。投资人看的不是你现在有没有产品,而是模型能力的进化速度。如果每隔几个月都能解决一个关键瓶颈,那故事就还在。
风险也摆在那
110 亿美金,零收入。这个估值全靠模型能力的进化速度撑着。π 系列一旦停滞,或者 Google DeepMind、Tesla Optimus 从别的方向赶上来,故事就讲不下去了。
还有一个时间问题。OpenAI 从 GPT-3 到 ChatGPT 花了两年半。PI 从 π0 到能卖钱的产品,中间还隔着硬件适配、安全认证、客户集成。80 人的精英团队在研究阶段效率极高,但规模化阶段需要的是完全不同的能力。
写在最后
四个月前写 PI 的公司画像时,我的判断是:如果具身智能领域会出一个 OpenAI 级别的公司,PI 目前最接近。
现在估值从 56 亿翻到了 110 亿,这个判断没变。但赔率也在变,越来越贵了。
看清方向,比跑得快更重要。我是向光,下次见。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号