深度学习中的下采样(步长卷积)详解


1
步长卷积是什么?
步长卷积 是指 卷积步长(stride)大于1的卷积操作 。
在标准卷积中,我们通常设置步长stride=1,即卷积核每次移动一个像素,这样可以保持特征图尺寸基本不变(配合适当填充)。而步长卷积设置stride=2或更大,让卷积核每次跳跃多个像素,从而实现 下采样 ——即主动减小特征图的空间尺寸。
一个直观的理解:
标准卷积(stride=1):像用放大镜一寸一寸地仔细扫描图像
步长卷积(stride=2):像每隔一个点跳着扫描,一次看两格
数学表达: 给定输入尺寸 H_in,卷积核尺寸 K,步长 S,填充 P,输出 尺寸为:
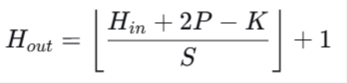
当 S=2 时 ,输出尺寸大约减半。
2
步长卷积的工作原理
1. 基本操作
以一个简单的例子说明:
输入:5×5 的特征图
卷积核:3×3
步长:2
填充:0
计算过程:
- 卷积核放在左上角(0,0)到(2,2),计算得到一个输出值
- 向右移动2格,放在(0,2)到(2,4),计算第二个值
- 向下移动2格,放在(2,0)到(4,2),计算第三个值
- 依此类推...
最终输出尺寸 = floor((5 - 3)/2) + 1 = 2,得到一个 2×2 的输出特征图。
2. 与池化的对比
步长卷积可以看作是将 特征提取 和 下采样 两个步骤合二为一:
传统方式 | 现代方式 |
|---|---|
Conv (stride=1) → 提取特征 | Conv (stride=2) → 同时完成提取和下采样 |
Pooling → 下采样 |
3
步长卷积的核心作用
1. 下采样(Downsampling)
这是步长卷积最直接的作用。通过设置 stride=2,可以将特征图尺寸减半,逐步构建层次化的特征表示。
典型模式:
输入 (224×224)
↓ Conv stride=2
特征图 (112×112)
↓ Conv stride=2
特征图 (56×56)
↓ Conv stride=2
特征图 (28×28)
...2. 替代池化层
在现代CNN架构中,步长卷积越来越倾向于 替代传统的池化层 。原因如下:
对比维度 | 池化层 | 步长卷积 |
|---|---|---|
参数 | 无参数 | 有可学习参数 |
特征提取 | 只做下采样,不提取新特征 | 边下采样边提取特征 |
信息保留 | 可能丢失信息(最大池化只保留最强响应) | 可以通过学习保留更丰富的信息 |
位置信息 | 对位置变化不敏感 | 能保留相对位置关系 |
端到端学习 | 固定操作 | 可参与端到端优化 |
关键洞察 :步长卷积让下采样过程也变得 可学习 ,网络可以根据任务需求自行调整如何在下采样的同时提取特征。
3. 扩大感受野
通过步长卷积逐步减小特征图尺寸,后续层的每个神经元对应输入图像的区域(感受野)会快速增大,这对于识别大物体或理解全局上下文至关重要。
4. 减少计算量
特征图尺寸减半后,后续卷积的计算量会减少约4倍(因为空间维度减半,像素数减为1/4)。这是构建高效网络的重要策略。
4
步长卷积的特点
- 优点
特点 | 说明 | 意义 |
|---|---|---|
可学习下采样 | 下采样的方式由数据驱动学习得到 | 比固定规则的池化更灵活、更适应任务 |
端到端统一 | 整个网络只有卷积一种操作 | 简化架构设计,便于优化 |
避免信息丢失 | 不像最大池化只取最大值 | 可以学习保留对任务重要的信息 |
计算效率 | 一次操作完成两步工作 | 减少层数,降低延迟 |
梯度流动好 | 全程可微,没有池化的梯度中断问题 | 训练更稳定 |
- 缺点
特点 | 说明 | 应对 |
|---|---|---|
参数量增加 | 相比无参数的池化,增加了可学习参数 | 对于大网络,增加的参数可接受;对于小网络需权衡 |
可能过拟合 | 可学习下采样在小数据集上可能过拟合 | 配合数据增强、正则化 |
失去平移不变性 | 没有池化那种“不管物体在哪都能识别”的特性 | 对于分类任务可能需配合数据增强 |
5
步长卷积的使用方法(以PyTorch为例)
在PyTorch中,设置步长卷积非常简单:
import torch.nn as nn
# 标准卷积 (stride=1)
conv1 = nn.Conv2d(in_channels=64, out_channels=128,
kernel_size=3, stride=1, padding=1)
# 步长卷积 (stride=2) 用于下采样
conv2 = nn.Conv2d(in_channels=128, out_channels=256,
kernel_size=3, stride=2, padding=1)
# 更激进的步长 (stride=4) 用于快速下采样
conv3 = nn.Conv2d(in_channels=256, out_channels=512,
kernel_size=3, stride=4, padding=1)一个典型的卷积块设计:
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels,
kernel_size=3, stride=stride, padding=1)
self.bn = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
return self.relu(self.bn(self.conv(x)))
# 使用 stride=2 的下采样块
down_block = ConvBlock(256, 512, stride=2)6
步长卷积在经典网络中的应用
1. ResNet(残差网络)
ResNet是步长卷积的典型代表。在每个残差块的第一个卷积中设置stride=2来实现下采样:
输入 (56×56×256)
↓
Conv 3×3, stride=2, 512 → 输出 (28×28×512)
↓
Conv 3×3, stride=1, 512
↓
...
同时,shortcut连接也需要处理尺寸变化:
- 如果stride=2,shortcut也需要 stride=2 的卷积来匹配尺寸2. 全卷积网络(FCN)
在语义分割等需要保持空间信息的任务中,步长卷积的使用需要更加谨慎:
- 编码器部分:使用步长卷积逐步下采样,提取高层次特征
- 解码器部分:使用转置卷积(可视为步长卷积的逆操作)逐步上采样,恢复分辨率
3. 生成对抗网络(GAN)
在生成器中,常用 转置卷积 (也叫反卷积)进行上采样,它本质上是步长卷积的逆过程:
步长卷积:输入大 → 输出小(下采样)
转置卷积:输入小 → 输出大(上采样)
7
步长卷积 vs 其他下采样方法
方法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
最大池化 | 取窗口内最大值 | 无参数、平移不变性强 | 可能丢失信息、不可学习 | 分类任务、传统CNN |
平均池化 | 取窗口内平均值 | 无参数、平滑 | 可能弱化强特征 | 需要平滑特征时 |
步长卷积 | 卷积步长=2 | 可学习、端到端 | 有参数、可能过拟合 | 现代CNN主流 |
空洞卷积 | 膨胀卷积核 | 保持分辨率扩大感受野 | 计算量稍大 | 分割、检测任务 |
8
在机器人应用中的考量
对于机器人团队,选择是否使用步长卷积以及如何使用,需要考虑以下因素:
1. 任务类型
- 分类/检测 :步长卷积是理想选择,可以逐步构建层次化特征
- 分割/定位 :需要平衡下采样程度,避免过度损失空间信息
- 实时控制 :步长卷积可以减少后续计算量,利于实时性
2. 资源约束
- 边缘设备 :步长卷积可替代池化+卷积的组合,减少层数,降低延迟
- 内存受限 :通过步长卷积快速减小特征图尺寸,节省内存
3. 数据量
- 大数据 :步长卷积的可学习特性可以充分发挥优势
- 小数据 :考虑用池化+标准卷积替代,避免过拟合
4. 部署考虑
- 推理引擎优化 :大多数推理引擎(TensorRT、ONNX Runtime)对步长卷积有良好支持
- 量化敏感度 :步长卷积对量化可能比池化更敏感,需测试
9
步长卷积的变体和进阶
1. 深度可分离卷积中的步长
在MobileNet等轻量网络中,步长卷积应用在深度卷积上:
# 深度可分离卷积 + 步长=2
depthwise_conv = nn.Conv2d(in_channels, in_channels,
kernel_size=3, stride=2, padding=1,
groups=in_channels)
pointwise_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)这种方式参数量极少,非常适合移动端部署。
2. 可变形卷积中的步长
可变形卷积也可以设置步长,在采样点学习偏移的同时进行下采样。
3. 步长与空洞卷积结合
可以通过设置步长>1的同时使用空洞卷积,实现快速下采样并扩大感受野。
10
总结:什么时候用步长卷积?
场景 | 推荐用法 | 理由 |
|---|---|---|
通用图像分类 | 全程用步长卷积下采样 | ResNet风格,效果好且简单 |
移动端/边缘设备 | 深度可分离卷积+步长 | MobileNet风格,计算量小 |
语义分割 | 编码器用步长卷积,解码器用转置卷积 | 保持端到端可学习 |
目标检测 | 主干网络用步长卷积,检测头保持分辨率 | 平衡速度和精度 |
小数据集 | 考虑用池化替代部分步长卷积 | 减少可学习参数,防过拟合 |
需要强平移不变性 | 仍可用步长卷积,配合数据增强 | 数据增强可弥补 |
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号