Transformer的自注意力机制详细解析


1
自注意力是什么?
1. 核心思想:让序列“自我关注”
想象你正在读一句话:“这只动物没看见那只鸟,因为它飞得太快了。” 当你读到“它”时,你的大脑会主动去寻找“它”指代的是“动物”还是“鸟”。这个过程就是 注意力 ——根据当前词,动态地从上下文筛选相关信息。
自注意力 做的就是这件事:对于序列中的每个元素(比如句子中的每个词),它计算该元素与序列中 所有元素 (包括它自己)的关联程度,然后根据这些关联程度,从所有元素中聚合信息来重新表示当前元素。
用一句话概括: 自注意力让每个位置都能看到全局,并决定关注哪里 。
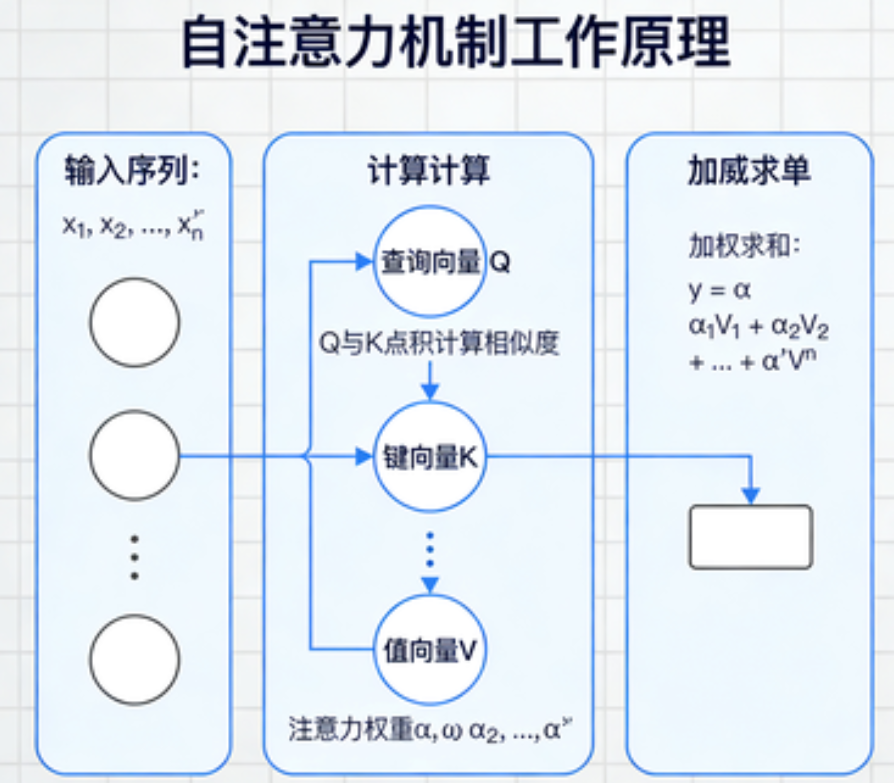
2. 三个核心角色:Q、K、V
为了实现上述过程,自注意力为每个输入元素引入了三个角色:
- Q(查询,Query) :表示当前元素“想找什么”。 例如,“它”作为当前词,会发出查询:“我想知道前面哪个名词是我的指代对象”。
- K(键,Key) :表示当前元素“有什么特征可以被匹配”。 每个词都会提供自己的键,比如“动物”这个词的键可能包含“有生命、名词”等信息。
- V(值,Value) :表示当前元素“实际携带的信息”。 一旦找到了与查询匹配的键,就会取出对应的值作为有效信息。
比喻 :这就像你在图书馆找书。Q是你的查询关键词(“机器学习”),K是每本书的标签,V是书的内容。你通过比较Q和K找到最相关的几本书,然后阅读它们的内容(V)来充实自己的知识。
在自注意力中,Q、K、V都是由同一个输入向量通过线性变换得到的,因此称为“自”(self)——自己在自己身上做注意力。
2
为什么需要自注意力?
在自注意力出现之前,处理序列主要靠RNN和CNN,它们各有短板:
模型 | 优点 | 缺点 | 自注意力如何解决 |
|---|---|---|---|
RNN | 天然处理变长序列,有记忆 | 串行计算,无法并行;长距离信息容易衰减 | 自注意力一次看到所有位置,完全并行,且直接连接任意距离 |
CNN | 可以并行 | 感受野有限,需堆叠多层才能看到全局 | 自注意力一层就能捕获全局依赖,无需堆叠 |
此外,自注意力还能提供 可解释性 ——注意力权重可以可视化,告诉我们模型在关注什么,这在调试和分析中很有价值。
3
自注意力怎么实现?
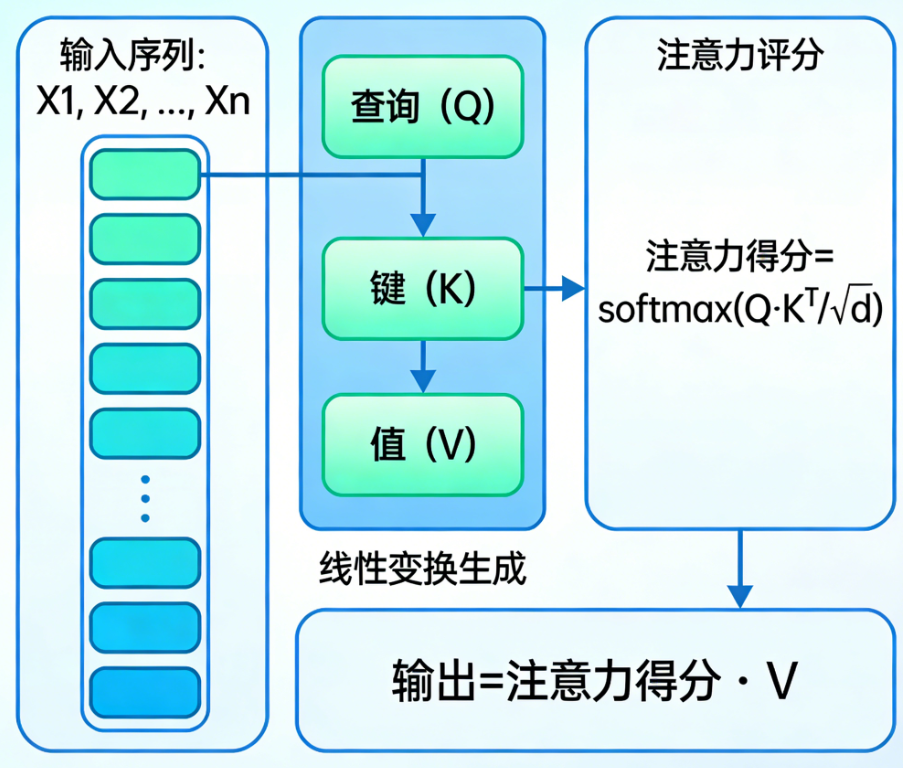
下面 我们一步步拆解计算过程。假设输入是一个长度为 n 的序列,每个元素用一个 d 维向量表示(例如词嵌入)。我们将 这些向量堆叠成矩阵 $X∈R^{n×d}$。
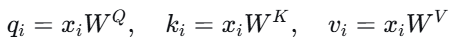
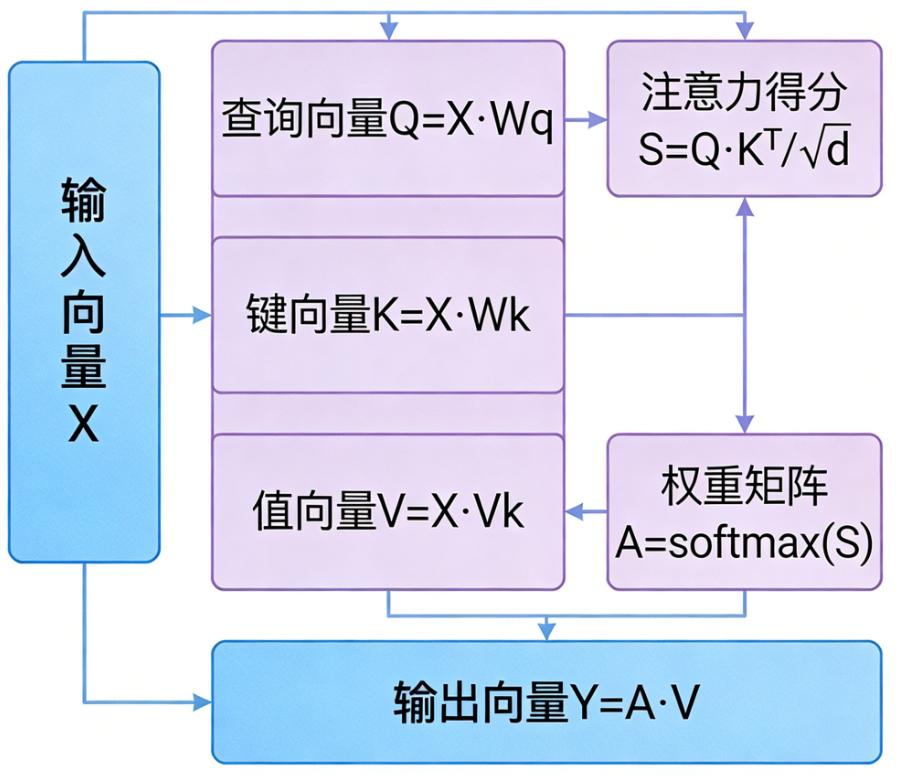
第1步:生成Q、K、V
对每个输入向量 $xi$,我们通过三个可训练的权重矩阵 $WQ,WK,WV∈R^{d×dk}$分别计算对应的查询、键、值向量(这里为了简单,设 $dk=d$,实际中 $d_k$ 常小于 d 以降低计算量):
将 所有 $qi$ 堆叠成矩阵 $Q∈R^{n×dk}$,同样得到 $K,V$。
并行实现 :实际上,我们直接用矩阵乘法一次算出所有Q、K、V:
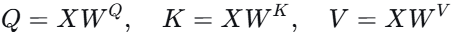
第2步:计算注意力分数
对于 第 $i$个位置的查询 $qi$,它与所有位置的键 $kj$ 的相似度用点积表示:
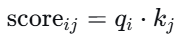
将所有分数 组成矩阵 $S=QK^T$,尺寸为 $n×n$。$S_{ij}$ 表示第 $i$个位置对第 $j$个位置的“关注度原始分”。
第3步:缩放(Scale)
点积 的结果会随着维度 $dk$增大而变大,导致softmax后的梯度极小,因此,我们除以 $dk$ 进行缩放:
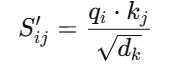
第4步:Softmax归一化
对每一行(即每个查询对应的所有键的分数)应用softmax,使每一行的和为1,得到注意力 权重矩阵 $A∈R^{n×n}$:
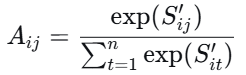
$A_{ij}$ 就是位置 $i$分配给位置 $j$的注意力权重。
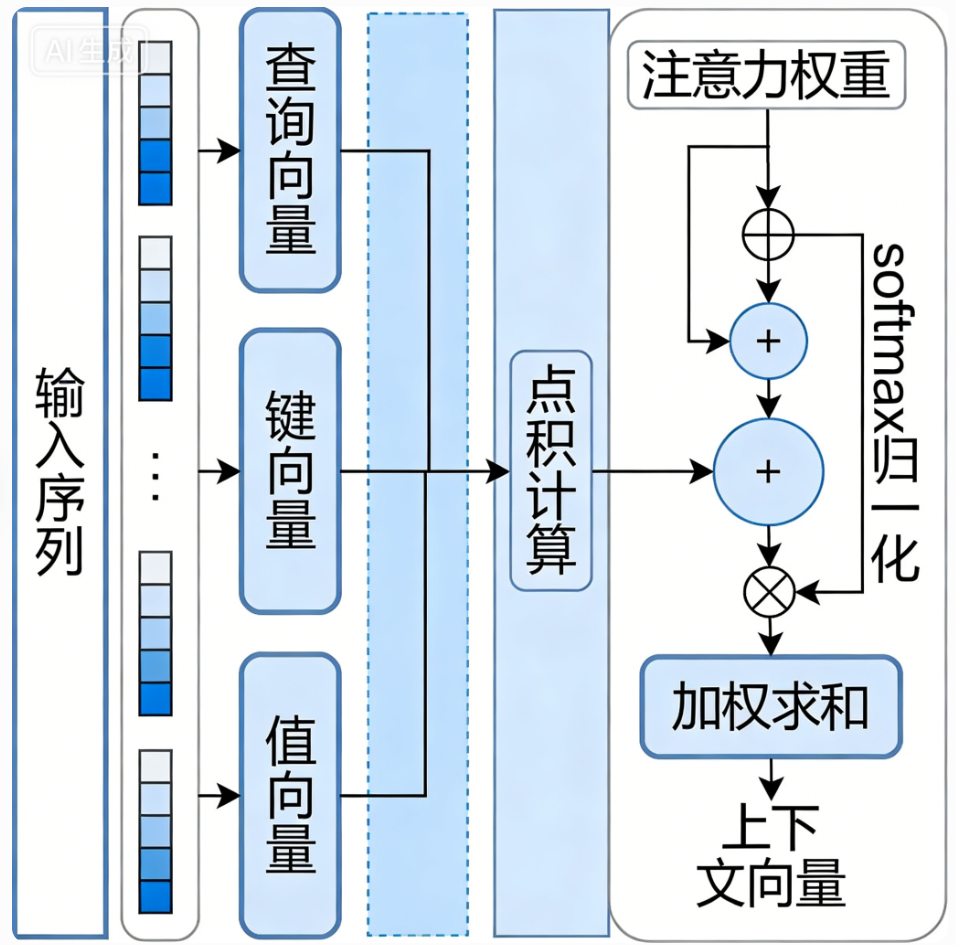
第5步:加权求和
用注意力权 重对值矩阵 $V$ 进行加权求和,得到最终的输出矩阵 $Z∈R^{n×d_k}$:
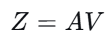
对于位置 $i$,其输出向量
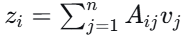
,即融合了全局信息后的新表示。
全部公式(矩阵形式)
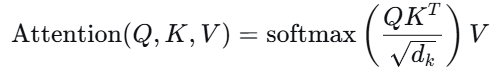
这就是经典的自注意力计算公式。
4
一个简单的代码示例(PyTorch)
下面用伪代码实现一个简化版的自注意力层:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, d_model, d_k):
super().__init__()
self.d_k = d_k
self.W_q = nn.Linear(d_model, d_k) # 可学习矩阵
self.W_k = nn.Linear(d_model, d_k)
self.W_v = nn.Linear(d_model, d_k)
def forward(self, x):
# x shape: (batch_size, seq_len, d_model)
Q = self.W_q(x) # (batch, seq_len, d_k)
K = self.W_k(x)
V = self.W_v(x)
scores = torch.matmul(Q, K.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.d_k, dtype=torch.float32))
# scores shape: (batch, seq_len, seq_len)
attn_weights = F.softmax(scores, dim=-1)
out = torch.matmul(attn_weights, V)
return out5
延伸:多头注意力和计算复杂度
多头注意力
为了让模型能从不同子空间学习关系,Transformer使用了 多头注意力 :并行运行多个自 注意力(每个头有独立的 $WQ,WK,W_V$),然后将所有头的输出拼接起来,再经过一个线性层。这相当于让模型同时关注不同类型的依赖(例如语法关系、语义相似性等)。
计算复杂度
自注意力的主要计算量在 $QK^T$这一步,复杂度为 $O(n^2⋅d)$,其中 $n$是序列长度。当 $n$ 很大(如长文档)时,平方复杂度会成为瓶颈。因此后续出现了稀疏注意力、滑动窗口注意力、线性注意力等变体来优化。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号