学术圈大地震!顶会21%审稿竟是AI代写?当“同行评审”变成“机器互搏”

学术圈大地震!顶会21%审稿竟是AI代写?当“同行评审”变成“机器互搏”

沈宥
发布于 2026-03-31 19:15:30
发布于 2026-03-31 19:15:30
导读:你熬夜三个月打磨的论文,可能只用了审稿人3分钟——他把你的文章扔给ChatGPT,然后复制粘贴了一段由AI生成的“正确的废话”。这不是科幻电影,而是刚刚发生在全球最顶级AI会议 ICLR 2026 上的真实荒诞剧。
01 事件始末:一场由“直觉”引发的信任危机
时间回到2025年底,正值 ICLR 2026(国际学习表征会议)的审稿高峰期。作为与NeurIPS、ICML并列的三大顶会之一,ICLR一直是机器学习领域的“奥林匹克”。
然而,今年气氛有些诡异。
卡内基梅隆大学(CMU)的著名AI研究员 Graham Neubig 在收到几份审稿意见后,感到了一种难以名状的“违和感”。
- 篇幅异常冗长:审稿意见洋洋洒洒几千字,看似详尽,实则空洞。
- 要求离谱:审稿人要求进行的统计分析,根本不是该领域论文的标准操作,甚至逻辑不通。
- **“幻觉”频出:有哥本哈根大学的团队更发现,审稿人竟然在批评论文中根本不存在的数值结果**,并据此给出了低分。
“这不像是一个人类专家写的,倒像是大模型在‘一本正经地胡说八道’。”
为了验证直觉,Graham Neubig在社交媒体上发出了一个50美元的悬赏令:“谁能系统性地检测出ICLR论文和审稿中到底夹杂了多少AI文本?”
接榜的是专门从事AI文本检测的 Pangram Labs。他们利用自研工具 EditLens,对ICLR 2026公开的 75,800条 审稿意见进行了地毯式扫描。
结果令人咋舌:
- 🔴 21% 的审稿意见被判定为 **“完全由AI生成”**(约1.59万份)。
- 🟠 35% 的审稿意见经过 重度或中度AI编辑。
- 🟢 仅有 43% 被认为是 纯人类撰写。
这意味着,每5份审稿意见中,就有1份是AI“全自动”完成的。 曾经神圣的“同行评审”(Peer Review),正在演变成一场“机器审机器”的荒诞游戏。
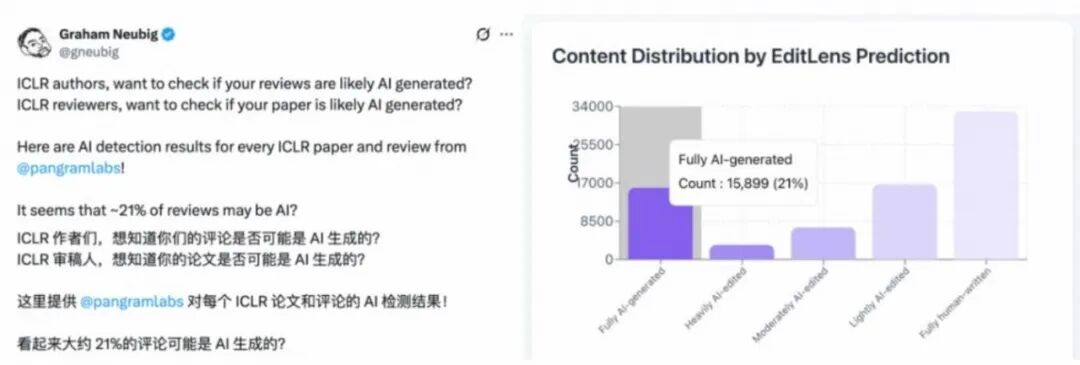
(数据来源:Pangram Labs / Graham Neubig)
02 技术揭秘:AI是如何“抓出”AI审稿人的?
很多人好奇:既然都是大模型生成的,检测工具凭什么能分辨?难道也是“用魔法打败魔法”?
Pangram Labs 和其他检测机构主要利用了以下几个维度的统计指纹:
1. 困惑度与突发性(Perplexity & Burstiness)
人类写作通常具有“突发性”:句子长短不一,用词有时精准有时随意,情感波动明显。而早期的LLM生成的文本往往过于平滑、结构刻板、词汇分布过于均匀。
- 检测逻辑:如果一段文本的困惑度过低(太完美预测),且缺乏人类特有的节奏感,系统会标记为高风险。
2. “幻觉”特征匹配
在此次事件中,许多AI审稿意见出现了典型的事实性幻觉(如捏造数据、引用不存在的公式)。检测模型经过训练,能识别出这种“看似合理但经不起推敲”的逻辑断层模式。
3. 行为元数据异常
除了文本本身,时间戳也是铁证。
- 人类审稿:阅读一篇复杂的深度学习论文通常需要数小时甚至数天。
- AI审稿:从上传论文到生成几千字的详细评论,如果仅耗时几分钟,系统直接判定为异常。
- 数据佐证:统计显示,那些被标记为“全AI生成”的审稿意见,其平均完成时间显著短于人类平均水平,且给出的分数普遍偏高(倾向于做“老好人”,避免冲突)。
4. 风格一致性分析
对比同一审稿人往年的评审风格。如果一个常年以“言辞犀利、直击要害”著称的审稿人,突然变得“温文尔雅、长篇大论但毫无重点”,算法会立即触发警报。

03 深层影响:当学术守门人“集体罢工”
这场风波不仅仅是几个审稿人偷懒的问题,它击穿了学术界的信任基石。
📉 劣币驱逐良币 如果21%的审稿是AI完成的,那么真正用心审阅的专家负担将成倍增加。更可怕的是,AI倾向于给出“中庸”的评价,这可能导致极具创新性但存在瑕疵的论文被埋没,而平庸但格式完美的“八股文”得以通过。
🤖 “闭环”陷阱 现在的局面是:作者用AI写论文 -> 审稿人用AI审论文 -> 编辑用AI做决定。 在这个闭环中,人类的角色被无限压缩。如果训练数据本身包含偏见或错误,这个闭环将不断放大这些错误,导致学术研究陷入“内卷式停滞”。
⚖️ 责任归属的真空 当AI审稿人误拒了一篇诺奖级别的论文,谁该负责?
- 是偷懒的审稿人?
- 是提供工具的会议方?
- 还是开发模型的科技公司? 目前,学术界对此尚无定论。
04 冷思考:AI能否成为合格的“审稿人”?
既然禁止很难(毕竟无法24小时监控审稿人的屏幕),我们是否应该彻底禁止AI进入审稿领域?
答案可能是否定的。堵不如疏,关键在于“定位”。
✅ AI的正确打开方式:超级助手
- 初筛与格式检查:让AI去检查参考文献格式、语言语法、是否存在明显的逻辑矛盾,效率远超人类。
- 查重升级:传统查重只能比对文字,AI可以比对思想内核,识别改写后的剽窃。
- 辅助人类:审稿人可以使用AI总结长文、提取核心公式,但最终的判断(Accept/Reject)必须由人类做出,并附上人类独有的洞察(Insight)。
❌ AI的禁区:替代思考
- 创新性评估:AI基于历史数据训练,很难理解“反直觉”的突破。真正的创新往往是对旧范式的颠覆,而这正是AI的盲区。
- 伦理与价值判断:论文的社会影响、伦理风险,需要人类的价值观来权衡。
05 结语:让人类回归人类,让机器回归机器
ICLR 2026的这场闹剧,给全学术界敲响了警钟。
技术的进步不应以牺牲严谨为代价。 如果同行评审变成了“提示词工程”的比拼,那科学的灯塔终将熄灭。
未来的审稿制度或许会迎来变革:
- 强制披露:审稿人必须声明AI的使用程度(类似论文中的Conflict of Interest)。
- 人机协作认证:会议方提供官方认证的AI辅助工具,留痕操作记录。
- 双重盲审升级:不仅隐藏作者身份,或许未来也要隐藏“审稿过程”的黑盒,引入第三方复核机制。
在这个AI无处不在的时代,人类最宝贵的能力,不再是写出完美的句子,而是提出深刻的问题,并做出负责任的判断。
愿每一篇好论文,都能被温柔以待;愿每一次评审,都闪耀着人类智慧的光芒。
📚 参考资料与延伸阅读:
- Nature News: "AI-generated reviews spark controversy at ICLR 2026"
- Pangram Labs Report: "Analysis of AI Usage in ICLR 2026 Peer Reviews"
- *Graham Neubig's Thread on X (Twitter)*: The original bounty and findings.
- ICLR 2026 Official Policy: Guidelines on AI usage for authors and reviewers.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号