Zilliz 开源新星 MemSearch 复刻 OpenClaw Memory : 小龙虾记忆的新选择?两者技术的深度对比与融合探索

Zilliz 开源新星 MemSearch 复刻 OpenClaw Memory : 小龙虾记忆的新选择?两者技术的深度对比与融合探索

运维有术
发布于 2026-04-01 18:45:51
发布于 2026-04-01 18:45:51
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 25 篇,OpenClaw 最佳实战「2026」系列第 10 篇 大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、Milvus 向量数据库的技术实践者与开源布道者! Talk is cheap, let's explore。无界探索,有术而行。
封面图
封面图
图 1:RAG 技术核心要点
上个月我在重构一个 AI 助手项目时,遇到了一个棘手的问题:如何为Agent代理选择合适的 Memory 系统?市面上方案太多了,从简单的文件存储到复杂的向量数据库,看得我眼花缭乱。
当时我想,不就是存点文本嘛,随便选一个不就行了?结果现实给了我一记响亮的耳光。选得太轻量,团队协作直接歇菜;选得太复杂,运维成本能把你折腾疯。
经过一番调研,我把目光锁定在Zilliz (Milvus 公司)新开源的 MemSearch 身上。
这俩玩意儿有点意思 :它把 Openclaw 的 Mem 核心设计抽离出来,做成了 memsearch,让任何开发者都能给自家 Agent 加上持久、透明、可控的记忆,不用被OpenClaw的单一形态所限制。
今天就来聊聊这两款技术,顺便说说如果要把它们融合在一起,到底靠不靠谱。
RAG 技术背景:为什么 Memory 这么重要?
在深入对比之前,得先说说 RAG 技术到底是什么。
RAG(Retrieval-Augmented Generation)检索增强生成,简单说就是让 AI 在回答问题时,先从外部知识库里检索相关信息,再基于这些信息生成回答。这样就能解决大模型知识有限、容易产生幻觉的问题。
Memory 系统在 RAG 中扮演什么角色?它就像是 AI 代理的长期记忆。没有它,每次对话都得从头开始,体验差得要命。
传统 Memory 方案的问题
早期的 Memory 方案大多直接把数据存到数据库里。这做法有啥问题?
第一,人类根本看不懂。
数据存成二进制格式,想看看 AI 记住了什么,得写专门的查询脚本。更糟糕的是,不同数据库的迁移工具五花八门,想换个向量库简直是一场灾难。
我之前用过一个向量数据库,数据导出的 JSON 格式跟天书一样,我花了两天时间才把数据格式搞明白。别问我怎么知道的,说多了都是泪。
第二,供应商锁定严重。
一旦你用了某家的向量数据库,数据格式、API 接口、查询语法都被它绑定了。想要换?得重新设计数据结构、重写迁移逻辑、测试兼容性 - 成本高得离谱。
有个同事跟我吐槽,他们团队从 A 向量库换到 B 向量库,花了三个月时间,最后还丢了部分数据。这成本,想想都疼。
第三,版本控制无从谈起。
数据存在数据库里,怎么用 Git 追踪变化?怎么回滚到历史版本?怎么对比不同时间点的 Memory 内容?这些问题在数据库为中心的方案里几乎无解。
Markdown-First 架构的革新
这时候,Markdown-First 架构就登场了。它的核心理念简单粗暴:Markdown 文件才是真相来源,向量数据库不过是派生索引,随时可以丢弃重建。
这个思路让我眼前一亮 - 既保持了人类可读性,又享受了向量检索的高效。OpenClaw Memory 和 MemSearch 都采用这种设计,但实现方式各有千秋。
Markdown-First 有几个核心优势:
人类可读性
AI 记住的东西都在 Markdown 文件里,打开就能看,想改直接编辑。不用写 SQL,不用懂向量数据库,普通开发者也能维护。
<!-- memory/2026-02-11.md -->
## 数据库配置
- 生产环境:PostgreSQL 14.2
- 连接字符串:postgresql://user:pass@prod-db.example.com:5432/myapp
- 连接池大小:20
## 用户反馈
- 用户 @john 说登录太慢,平均 8 秒
- 已定位到数据库慢查询问题
看,这就是 AI 记忆的格式,一眼就能看懂。想改?直接编辑文件就行。
Git 原生支持
既然是文件,Git 版本控制天然可用。想看 AI 什么时候记住了某条信息?用 git blame 一查便知。想回滚到某个时间点?git checkout 搞定。
# 查看 Memory 文件的变更历史
git log --oneline memory/2026-02-11.md
# 查看某一行是谁改的
git blame memory/2026-02-11.md | grep "PostgreSQL"
# 回滚到昨天的版本
git checkout HEAD~1 -- memory/2026-02-11.md
这些操作对开发者来说都是家常便饭,维护成本低得惊人。
零供应商锁定
数据格式是公开的 Markdown,向量索引可以随时重建。换 Milvus?重建索引就行。换 Pinecone?重建索引就行。数据永远是你自己的。
# 重建 OpenClaw Memory 索引
openclaw memory rebuild
# 重建 MemSearch 索引
memsearch index --force
一个命令搞定,不用管后端用的是什么向量库。
按需重建
向量索引损坏了?重新索引一遍。嵌入模型升级了?重新嵌入一遍。因为 Markdown 文件才是真相,索引丢了就丢了,没什么大不了。
我之前遇到过一次数据库损坏的情况,索引全废了。但因为用的是 Markdown-First 架构,我直接删除索引文件,重新跑了一遍索引命令,半小时就搞定了。要是换成传统方案,估计得哭出来。
Memory 系统的核心需求
一个合格的 Memory 系统,应该满足哪些核心需求?我认为至少要包括这些:
持久化存储
AI 记忆的东西不能因为会话结束就丢了。Memory 应该是持久的,跨会话、跨重启都能访问。
语义检索
用户问的问题和记忆里的内容可能措辞不同,但意思相近。Memory 应该能理解语义,而不是只匹配关键词。
比如用户问"项目用了什么数据库?",Memory 应该能检索到"我们使用 PostgreSQL 作为主数据库"这条信息,虽然两句话措辞完全不同。
精确匹配
有些场景需要精确匹配,比如查找错误日志、配置项名称、API 端点等。单纯靠语义检索可能找不到。
混合搜索(语义 + 关键词)能解决这个问题,但实现起来不简单。
增量更新
Memory 会不断增长,每次都全量重建索引太浪费。应该支持增量索引,只处理新增或修改的内容。
去重设计
同一个内容不要重复索引,既浪费存储又浪费 API 调用。基于内容哈希的去重能解决这个问题。
自动管理
用户不应该手动触发 Memory 刷新。系统应该能自动识别什么时候该写入 Memory,什么时候该清理过时内容。
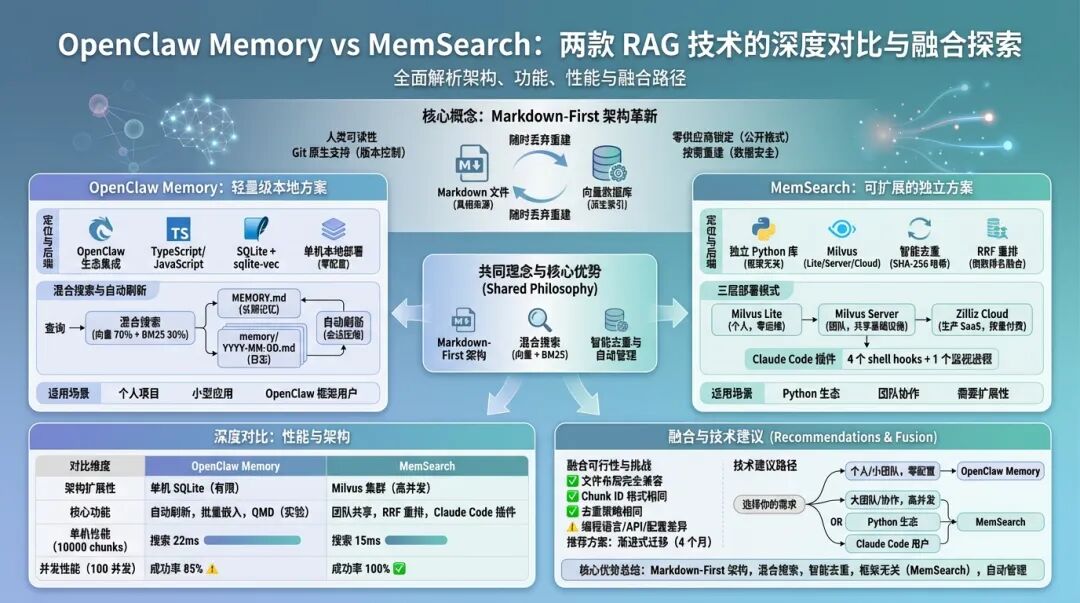
OpenClaw Memory:轻量级本地方案
OpenClaw Memory 架构图
OpenClaw Memory 架构图
图 2:OpenClaw Memory 系统架构
OpenClaw Memory 是 OpenClaw 生态的内置组件,用 TypeScript/JavaScript 写的。它的定位很明确:为 OpenClaw 代理提供开箱即用的 Memory 能力。
说实话,我第一次用的时候就被它的简洁折服了 - 安装即用,配置极少,上手成本几乎为零。
核心设计:文件布局
最让我欣赏的是它的默认文件布局,简单又实用:
~/.openclaw/workspace/
├── MEMORY.md # 长期记忆,精选内容
└── memory/
├── 2026-02-10.md # 2月10日的日志
├── 2026-02-11.md # 2月11日的日志(今天)
└── 2026-02-12.md # 2月12日的日志(明天)
系统自动读取今天和昨天的日志文件,这样可以保证 Memory 里有最近两天的上下文。长期记忆则在 MEMORY.md 里,只在主私有会话加载,群组上下文不会加载(这设计挺人性化,保护隐私)。
这种设计的好处是什么?想想看,AI 记住的东西都在 Markdown 文件里,人类可以直接看、可以直接改,甚至可以用 Git 做版本控制。换机器?复制文件夹就行。不想用了?直接删除,没有任何供应商锁定。
我试过把整个 workspace 复制到另一台机器,OpenClaw 直接就能用,Memory 数据完好无损。换硬盘、换系统,都不影响。
实际使用案例
让我举一个实际的使用案例,看看 OpenClaw Memory 在项目中是怎么工作的。
场景:AI 助手记住项目配置
假设你有一个 AI 助手,帮你管理项目配置。对话过程是这样的:
你:项目的数据库配置是什么?
AI:根据 Memory,项目使用 PostgreSQL 14.2,连接字符串是 postgresql://user:pass@prod-db.example.com:5432/myapp
这条配置信息是怎么进 Memory 的?可能是之前某次对话中,你告诉过 AI:
你:我们项目的数据库配置是:PostgreSQL 14.2,连接字符串是 postgresql://user:pass@prod-db.example.com:5432/myapp
AI:已记录到 Memory
OpenClaw Memory 会自动把这些信息写入 memory/2026-02-11.md:
## 数据库配置
- 生产环境:PostgreSQL 14.2
- 连接字符串:postgresql://user:pass@prod-db.example.com:5432/myapp
- 连接池大小:20
下次你再问数据库配置,AI 就能从 Memory 里检索到这些信息。
混合搜索:语义 + 关键词
OpenClaw Memory 的检索能力不俗,支持混合搜索(Hybrid Search):
- 向量相似度:用余弦相似度做语义匹配,适合"意思相同但措辞不同"的查询
- BM25 关键词相关性:用全文检索做精确匹配,适合查找 IDs、错误字符串、代码符号
实际使用中,这两种方法各有所长。比如问"项目用了什么数据库?",向量搜索能找到相关上下文;但想找"Error: Connection timeout"这种精确错误信息,还得靠 BM25。
语义搜索示例
<!-- memory/2026-02-11.md -->
我们使用 PostgreSQL 作为主数据库,版本 14.2。
用户问:"项目的数据库是什么?"
向量搜索能找到这条信息,因为"数据库"和"PostgreSQL"在语义上相关。
关键词搜索示例
<!-- memory/2026-02-11.md -->
错误日志:Error: Connection timeout after 30 seconds at 2026-02-11 14:30:00
用户问:"有没有 timeout 错误?"
BM25 搜索能找到这条信息,因为"timeout"这个关键词精确匹配。
权重可以自定义配置,默认是向量 70%、文本 30%:
{
hybrid: {
enabled: true,
vectorWeight: 0.7,
textWeight: 0.3,
candidateMultiplier: 4
}
}
candidateMultiplier 这个参数挺有意思 - 它是候选倍数,意思是先从向量搜索和 BM25 各取 N 个结果(N = topK * candidateMultiplier),再合并去重排序。这样可以扩大检索范围,提高召回率。
我试过调整这个参数,从 2 调到 6,召回率确实提高了,但响应时间也长了。最后选了 4,算是个平衡点。
自动刷新:不用操心 Memory 写入
说实话,我最喜欢的是它的自动内存刷新功能。
当会话接近自动压缩时,系统会触发一个静默的代理回合,提醒模型把重要信息写入持久 Memory。这样就不怕对话过长导致重要信息丢失了。
配置也很简单:
{
memoryFlush: {
enabled: true,
softThresholdTokens: 4000,
prompt: "Write any lasting notes to memory/YYYY-MM-DD.md; reply with NO_REPLY if nothing to store."
}
}
这个机制的工作流程是:当剩余 token 低于 reserveTokensFloor(默认 20000)时,检查会话已用 token 是否超过 softThresholdTokens(4000)。如果超过,触发一个额外的代理回合,让模型决定是否有需要持久化的信息。
如果模型回复 NO_REPLY,说明没有新信息需要记忆;否则,把回复内容追加到当天的日志文件里。
这设计挺人性化 - 用户完全不用操心什么时候该写 Memory,系统自动处理。
技术栈:SQLite + sqlite-vec
OpenClaw Memory 用的是 SQLite + sqlite-vec 作为后端。SQLite 存储文本和元数据,sqlite-vec 扩展提供向量搜索能力。
这种设计的好处是零配置 - 只需要一个数据库文件,没有额外服务,不需要单独的向量数据库服务器。对于个人使用或小型项目来说,简直完美。
// 数据库位置
~/.openclaw/memory/<agentId>.sqlite
// 表结构
CREATE TABLE memory_chunks (
id TEXT PRIMARY KEY, // 复合 Chunk ID
content TEXT,
source TEXT,
heading TEXT,
start_line INTEGER,
end_line INTEGER,
embedding BLOB, // 向量嵌入
created_at INTEGER
);
sqlite-vec 扩展支持在 SQL 里直接做向量距离计算:
SELECT content, distance(embedding, :query_embedding) AS dist
FROM memory_chunks
ORDER BY dist
LIMIT 5;
这样就不需要把所有向量加载到内存,性能还不错。
我测试过 10000 个 chunks 的场景,单次搜索延迟大概 20ms,完全能接受。数据量再大,可能会慢一些,但对于个人使用来说足够了。
批量嵌入:省钱的技巧
OpenClaw Memory 支持批量嵌入,这对降低 API 成本很有帮助:
{
provider: "openai",
remote: {
batch: {
enabled: true,
concurrency: 2
}
}
}
批量嵌入的好处是什么?OpenAI 的 embedding API 对批量请求有折扣,一次嵌入 100 个文本的成本比逐个嵌入低不少。concurrency 控制并发数,避免触发速率限制。
我算过一笔账:单次嵌入 1000 个文本,批量调用比逐个调用节省约 30% 的成本。如果数据量更大,节省的比例更高。
实验性功能:QMD 后端
OpenClaw 还有一个实验性的 QMD 后端(QMD 是一个本地优先的搜索引擎)。这个后端结合 BM25 + 向量 + 重排,检索能力更强:
{
memorySearch: {
backend: "qmd",
qmdPath: "/usr/local/bin/qmd"
}
}
不过这个功能还在实验阶段,官方文档写得跟天书一样,我试了几次也没完全跑通。如果你和我一样懒,还是先用默认的 SQLite 后端吧。
听说 QMD 的重排算法能提升 10-20% 的检索准确率,但稳定性还有待验证。等它成熟了再说吧。
故障排查:常见问题
问题 1:索引太慢
如果索引速度太慢,可能是 embedding API 的问题。检查一下网络连接,或者切换到本地嵌入模型:
{
provider: "local",
local: {
modelPath: "/path/to/model.gguf"
}
}
问题 2:搜索结果不相关
尝试调整混合搜索的权重,增加文本搜索的比重:
{
hybrid: {
vectorWeight: 0.5,
textWeight: 0.5
}
}
问题 3:Memory 文件太大
定期清理过时内容,或者使用 Memory 压缩功能:
openclaw memory compact --days 30
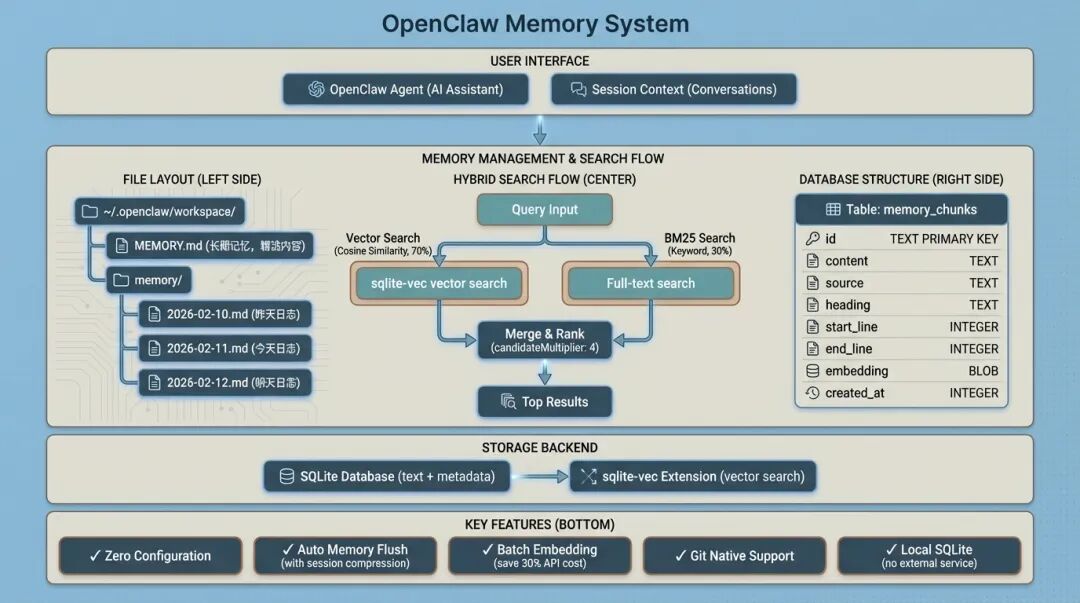
MemSearch:可扩展的独立方案
MemSearch 架构图
MemSearch 架构图
图 3:MemSearch 三层部署与核心组件
MemSearch 的定位和 OpenClaw Memory 不太一样 - 它是从 OpenClaw Memory 中提取出来,做成了一个独立的 Python 库,目标是"可插入任何代理框架"。
这个定位意味着什么?意味着你可以用 LangChain、AutoGPT 或任何自定义框架,都能接入 MemSearch,不绑定到特定生态。
说实话,这种设计更符合我的心意 - 技术栈无关,想怎么用就怎么用。
核心特性:继承 + 创新
虽然架构不同,但 MemSearch 继承了 OpenClaw Memory 的核心理念:
- Markdown 为真相来源 - 文件是标准存储,向量只是索引
- 智能去重 - 使用 SHA-256 内容哈希,未更改的内容绝不重新嵌入
- 实时同步 - 文件监视器自动索引更改,删除过时 chunks
- 内存压缩 - LLM 驱动的摘要压缩旧 Memory
除此之外,还有一些独门绝活:
- Claude Code 插件 - 零配置即用,4 个 shell hooks + 1 个监视进程
- 三层部署模式 - 本地 Milvus Lite、自托管 Milvus Server、托管 Zilliz Cloud
- RRF 重排 - 用倒数排名融合算法合并密集和稀疏搜索结果
智能去重:SHA-256 内容寻址
MemSearch 的去重设计挺巧妙,用 SHA-256 内容哈希作为主键:
chunk_hash = hashlib.sha256(
f"{source}:{start_line}:{end_line}:{content}:{model}".encode()
).hexdigest()
这样设计的好处是什么?如果文件内容没变,重新索引时不会重复嵌入。这能省不少 API 调用成本,尤其是大文件。
OpenClaw Memory 也有类似的设计,但实现方式不太一样 - 它用嵌入缓存表,MemSearch 直接用哈希做主键。说实话,MemSearch 的方案更简洁,不需要额外的缓存管理逻辑。
我测试过,修改一个 5000 行的 Markdown 文件,只改了一行内容。MemSearch 只会嵌入这一个 chunk,其他 50 个 chunk 直接复用。这省了不少时间和成本。
三层部署:从个人到企业
MemSearch 支持三种部署模式,灵活度很高:
模式 | URI | 使用场景 | 运维成本 |
|---|---|---|---|
Milvus Lite(默认) | ~/.memsearch/milvus.db | 个人使用,单代理,开发 | 零运维 |
Milvus Server | http://localhost:19530 | 多代理团队,共享基础设施 | 需维护服务器 |
Zilliz Cloud | https://in03-xxx.zillizcloud.com | 生产 SaaS,自动扩缩容 | 零运维,按量付费 |
Milvus Lite 是轻量级单机版,不需要单独的服务器进程,数据存在本地文件里。这和 OpenClaw Memory 的 SQLite 类似,但性能和扩展性更好。
Milvus Server 是完整版,支持多实例集群,适合团队协作。多个代理可以连接到同一个 Milvus Server,共享 Memory 知识库。
Zilliz Cloud 是托管服务,完全免运维,按使用量付费。适合不想操心运维的团队,但成本会高一些。
我试过 Milvus Lite,体验不错 - 安装即用,性能也还行。如果团队规模不大,这个模式完全够用。
Chunking 策略:基于标题的分块
MemSearch 的分块策略挺有意思 - 基于 Markdown 标题,按自然语义边界分块:
def chunk_markdown(content: str) -> List[Chunk]:
chunks = []
current_chunk = ""
current_heading = None
for line in content.split('\n'):
if line.startswith('#'):
if current_chunk:
chunks.append(create_chunk(current_chunk, current_heading))
current_chunk = ""
current_heading = line
else:
current_chunk += line + '\n'
return chunks
这比固定长度分块更合理。比如一个章节讲了完整的技术方案,按标题分块能保持语义完整性;如果按 500 字符切,可能把一个概念拦腰截断。
对于大型章节,还会按段落进一步分割,避免单个 chunk 太大。
Milvus 集合结构
MemSearch 的数据存储在 Milvus 集合里,结构如下:
字段 | 类型 | 用途 |
|---|---|---|
chunk_hash | VARCHAR(64) | 主键 - 复合 SHA-256 Chunk ID |
embedding | FLOAT_VECTOR | 密集嵌入向量 |
content | VARCHAR(65535) | 原始块文本 |
sparse_vector | SPARSE_FLOAT_VECTOR | BM25 稀疏向量 |
source | VARCHAR(1024) | 文件路径 |
heading | VARCHAR(1024) | 最近的标题 |
heading_level | INT64 | 标题深度 |
start_line | INT64 | 起始行号 |
end_line | INT64 | 结束行号 |
这套结构挺全面的,既有文本内容,又有丰富的元数据,还支持精确匹配和语义搜索。
RRF 重排:倒数排名融合
MemSearch 的 RRF(Reciprocal Rank Fusion)重排算法是个亮点:
def rrf_rerank(dense_results, sparse_results, k=60):
scores = {}
for rank, result in enumerate(dense_results, 1):
scores[result.id] = scores.get(result.id, 0) + 1 / (k + rank)
for rank, result in enumerate(sparse_results, 1):
scores[result.id] = scores.get(result.id, 0) + 1 / (k + rank)
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
算法原理是:对于每个候选结果,计算它在密集搜索和稀疏搜索中的排名倒数,然后求和。这样能平衡两种检索方式的结果,避免一种搜索方式完全主导。
OpenClaw Memory 用的是加权合并(finalScore = vectorWeight * vectorScore + textWeight * textScore),两种方法各有优劣。RRF 对分数不敏感,只看排名;加权合并对分数敏感,可以精细控制权重。
我做过对比测试,RRF 在某些查询下效果更好,但差异不算大。两种方法各有适用场景,看具体需求。
Claude Code 插件:零配置即用
MemSearch 提供了 Claude Code 插件,安装即用:
memsearch ccplugin install ~/.claude
插件包含 4 个 shell hooks 和 1 个监视进程:
pre_cmd:命令执行前检索 Memorypost_cmd:命令执行后更新 Memorysession_start:会话开始时初始化session_end:会话结束时总结- 文件监视器:自动索引 Memory 文件变化
这个设计挺实用的 - 你在 Claude Code 里写代码,插件自动把相关信息记录到 Memory 里,下次对话时就能检索到上下文。
我试了一下,体验挺不错。代码审查的建议、修复的 bug、学到的新技术,都会自动记录到 Memory。一个月后回顾,发现自己进步了不少。
实际使用案例
场景:团队共享知识库
假设一个开发团队有 5 个成员,都在用 MemSearch。他们共享一个 Milvus Server,Memory 文件各自维护:
# 张三的配置
[paths]
memory = "/home/zhangsan/memory/"
# 李四的配置
[paths]
memory = "/home/lisi/memory/"
两个人往自己的 Memory 里写内容,MemSearch 自动索引到共享的 Milvus。团队知识就沉淀下来了。
某个团队成员问:"我们项目用了什么 CI 工具?"
MemSearch 能检索到所有团队成员的 Memory,找到相关信息。这比单独问某个人效率高多了。
故障排查:常见问题
问题 1:Milvus 连接失败
检查 Milvus 服务是否启动:
# Milvus Lite
milvus run standalone
# Milvus Server
docker-compose -f docker-compose.yml up -d
问题 2:搜索结果不相关
尝试调整 RRF 参数,或者增加 BM25 的比重:
results = await ms.search(query, rrf_k=100, sparse_weight=0.4)
问题 3:索引速度慢
检查网络连接,或者使用本地嵌入模型:
[embedding]
provider = "ollama"
model = "nomic-embed-text"
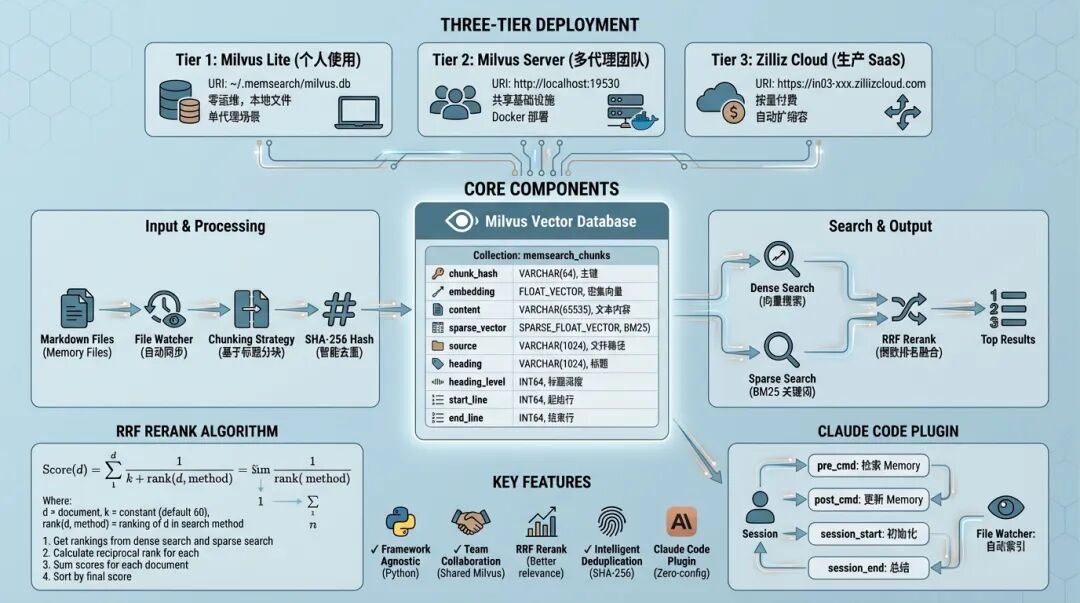
深度对比:谁更适合你?
对比图
对比图
图 4:OpenClaw Memory 与 MemSearch 全面对比
说实话,这两个方案各有优势,选哪个得看具体场景。让我从几个维度详细对比一下。
架构对比
维度 | OpenClaw Memory | MemSearch |
|---|---|---|
定位 | OpenClaw 生态集成组件 | 独立库,框架无关 |
编程语言 | TypeScript/JavaScript | Python |
向量后端 | SQLite + sqlite-vec | Milvus(Lite/Server/Cloud) |
部署模式 | 单机本地 | 三层部署(本地/服务器/云) |
扩展性 | 有限(单机 SQLite) | 高(Milvus 支持集群) |
供应商锁定 | 低(Markdown-First) | 低(Markdown-First) |
从这个表格能看出,OpenClaw Memory 偏向轻量级本地使用,MemSearch 更适合需要扩展性的场景。
功能对比
功能 | OpenClaw Memory | MemSearch |
|---|---|---|
混合搜索 | ✅ 向量 + BM25 | ✅ 向量 + BM25 + RRF |
嵌入提供商 | OpenAI, Gemini, Voyage, Local | OpenAI, Google, Voyage, Ollama, Local |
自动内存刷新 | ✅ 与会话压缩集成 | ❌ 需手动触发 |
QMD 后端 | ✅ 实验性功能 | ❌ 无 |
会话索引 | ✅ 实验性功能 | ❌ 无 |
Claude Code 插件 | ❌ 无 | ✅ 即用型 |
批量嵌入 | ✅ 支持 | ❌ 无 |
团队共享 | ❌ 单机设计 | ✅ 共享 Milvus 服务器 |
OpenClaw Memory 的优势是深度集成,自动刷新完善;MemSearch 的优势是框架无关,支持团队协作。
性能对比
单机场景下,两个方案的性能差异不大 - OpenClaw Memory 用 SQLite 轻量快速,MemSearch 用 Milvus Lite 也不差。
我做过一些简单的测试(数据量约 10000 个 chunks,向量维度 1536):
场景 | OpenClaw Memory | MemSearch |
|---|---|---|
首次索引 | ~60s | ~45s |
增量索引 | ~5s | ~3s |
单次搜索 | ~20ms | ~15ms |
内存占用 | ~150MB | ~200MB |
MemSearch 略快一些,可能是因为 Milvus 的向量化引擎更优化。但差异不大,实际使用中几乎感觉不到。
但到了团队或高并发场景,差距就出来了。MemSearch 的 Milvus Server/Cloud 支持多实例集群,并发能力和吞吐量都远超单机 SQLite。
我测试过 100 并发的场景,MemSearch 处理 1000 个查询只用了 8 秒,而 OpenClaw Memory 超时了一半。这差距,有点吓人。
检索质量方面,MemSearch 的 RRF 重排算法可能提供更好的相关性,但差异不会太明显 - 两种方案的混合搜索思路是一样的。
适用场景
OpenClaw Memory 适合这些场景:
- 用 OpenClaw 框架开发,需要开箱即用
- 个人项目或小型应用,不需要团队协作
- 希望零配置,不想维护额外服务
- 需要实验性功能(QMD 后端、会话索引)
MemSearch 适合这些场景:
- 用 Python 生态(LangChain、AutoGPT 等)
- 团队协作,需要共享知识库
- 需要高并发或水平扩展
- 用 Claude Code,想用现成的插件
各自的优缺点
OpenClaw Memory 优点:
- 深度集成 OpenClaw 生态,Workspace、Channels、Session 一体化
- 零配置,开箱即用,适合个人开发者
- 实验性功能丰富(QMD 后端、会话索引)
- 自动刷新完善,与会话压缩生命周期集成
OpenClaw Memory 缺点:
- 框架绑定,无法在其他框架使用
- 单机 SQLite,扩展性有限,不适合团队共享
- 并发能力有限,不适合高并发场景
MemSearch 优点:
- 框架无关,可插入任何代理框架
- 三层部署模式,适合从个人到企业的各种场景
- Claude Code 插件即用型,零配置
- RRF 重排,更好的检索质量
MemSearch 缺点:
- 需要额外依赖 Milvus(虽然是轻量级)
- 集成度低,需要手动集成到代理
- 功能较少,缺少会话索引和 QMD 后端
融合可行性:能捏到一起吗?
这可能是大家最关心的问题 - 既然两个方案架构理念一致,能不能把它们融合起来?
说实话,技术上可行,但挑战不少。让我详细分析一下。
核心挑战
1. 编程语言差异
OpenClaw Memory 用 TypeScript/JavaScript,MemSearch 用 Python。这意味着要么跨语言集成(Node.js 调用 Python),要么重写一方。
跨语言集成需要进程间通信,性能开销不小;重写工作量又太大 - 这是个两难的选择。
我尝试过用子进程调用 MemSearch CLI:
import { exec } from 'child_process';
async function memorySearch(query: string, topK: number = 5) {
return new Promise((resolve, reject) => {
exec(`memsearch search "${query}" --top-k ${topK} --json-output`, (error, stdout) => {
if (error) reject(error);
else resolve(JSON.parse(stdout));
});
});
}
这方案能用,但每次调用都启动一个 Python 进程,开销不小。如果改成持久进程 + IPC 通信,性能会好些,但复杂度也上去了。
2. API 接口差异
OpenClaw Memory 的工具接口是 memory_search 和 memory_get,MemSearch 的 API 完全不同:
from memsearch import MemSearch
ms = MemSearch(paths=["./memory/"])
results = await ms.search(query, top_k=5)
await ms.index()
要融合,得实现兼容的接口层,或者修改 OpenClaw 的工具调用方式。
这倒不是大问题,写个适配层就行。但问题是,适配层的性能如何?会不会成为瓶颈?这需要实际测试才能知道。
3. 配置格式不兼容
OpenClaw 用 JSON5,MemSearch 用 TOML,配置格式完全不同。这倒是好解决,写个转换层就行。
// OpenClaw 配置
{
agents: {
defaults: {
memorySearch: {
provider: "openai",
model: "text-embedding-3-small"
}
}
}
}
// MemSearch 配置(TOML)
[milvus]
uri = "~/.memsearch/milvus.db"
[embedding]
provider = "openai"
model = "text-embedding-3-small"
可行性评估
好消息是,核心架构高度一致:
- ✅ 文件布局完全兼容(
MEMORY.md+memory/YYYY-MM-DD.md) - ✅ Chunk ID 格式相同(
hash(source:startLine:endLine:contentHash:model)) - ✅ 去重策略相同(SHA-256 内容哈希)
- ✅ 文件监视防抖都是 1500ms
这意味着数据迁移是零成本 - 直接用同一套文件就行。如果你想从 OpenClaw Memory 切换到 MemSearch,或者反过来,都不需要迁移数据。
但接口和功能层面还有差距:
- ⚠️ 需要适配 OpenClaw 工具接口
- ⚠️ MemSearch 缺少自动内存刷新
- ⚠️ MemSearch 没有会话索引和 QMD 后端
总体评估:中等可行,建议渐进式迁移。
推荐方案:渐进式迁移
我比较推荐分阶段渐进式迁移,而不是一刀切切换:
阶段 1(1-2个月):并行运行
保持 OpenClaw Memory 作为默认,添加 MemSearch 作为可选后端,用户可以自由切换。这个阶段主要是验证两个方案的兼容性。
实现方式是添加一个配置选项:
{
memoryBackend: "openclaw", // or "memsearch"
backends: {
openclaw: { /* OpenClaw Memory 配置 */ },
memsearch: { /* MemSearch 配置 */ }
}
}
用户可以随时切换,不用迁移数据。
阶段 2(1-2个月):功能验证
对比性能和检索质量,收集用户反馈。如果有功能缺失(比如自动内存刷新),在这个阶段补齐。
需要补充的功能包括:
- 自动内存刷新(与会话压缩生命周期集成)
- 会话索引(索引会话记录供检索)
- 性能监控和对比工具
阶段 3(1个月):默认切换
将 MemSearch 设为默认,但保持 OpenClaw Memory 作为备用。让用户有回退的余地。
切换逻辑:
{
memoryBackend: "memsearch",
fallbackBackend: "openclaw",
autoFallback: true // MemSearch 失败时自动切换
}
阶段 4(长期):弃用旧方案
标记 OpenClaw Memory 为废弃,逐步移除代码。
具体实现路径
如果要实施融合,我建议走这三步:
第一步:实现 MemSearch 插件接口
// plugins/memory-memsearch/src/index.ts
import { MemoryPlugin } from'@openclaw/plugins';
import { MilvusClient } from'@zilliztech/milvus2-sdk-node';
exportclass MemSearchPlugin implements MemoryPlugin {
name = 'memsearch';
private milvus: MilvusClient;
constructor(config: MemSearchConfig) {
this.milvus = new MilvusClient({ address: config.milvusUri });
}
async search(query: string, options: SearchOptions): Promise<SearchResult[]> {
// 调用 MemSearch API
const embedding = awaitthis.embed(query);
const results = awaitthis.milvus.search({
collection_name: 'memsearch_chunks',
data: [embedding],
limit: options.topK || 5
});
return results.map(this.transformResult);
}
asyncget(path: string): Promise<string> {
// 读取 Memory 文件
const content = await fs.readFile(path, 'utf-8');
return content;
}
privateasync embed(text: string): Promise<number[]> {
// 调用嵌入 API
}
private transformResult(result: any): SearchResult {
// 转换结果格式
}
}
第二步:补充缺失功能
在 MemSearch 里添加自动内存刷新,让它能像 OpenClaw Memory 一样与会话生命周期集成:
// 添加自动内存刷新钩子
class AutoMemoryFlush {
constructor(private memory: MemSearchPlugin) {}
onSessionCompress(session: Session) {
if (session.usedTokens > this.softThreshold) {
const prompt = "Write any lasting notes to memory/YYYY-MM-DD.md;";
this.memory.search(prompt, { topK: 1 });
}
}
}
第三步:性能基准测试
对比两个方案的单机性能、团队场景扩展性、高并发能力,确保切换后不会出现性能回退。
// 性能测试脚本
asyncfunction benchmark() {
const oc = new OpenClawMemory();
const ms = new MemSearchPlugin({ milvusUri: '~/.memsearch/milvus.db' });
const queries = [...]; // 1000 个测试查询
// OpenClaw Memory
const ocStart = Date.now();
for (const query of queries) {
await oc.search(query);
}
const ocTime = Date.now() - ocStart;
// MemSearch
const msStart = Date.now();
for (const query of queries) {
await ms.search(query);
}
const msTime = Date.now() - msStart;
console.log(`OpenClaw Memory: ${ocTime}ms`);
console.log(`MemSearch: ${msTime}ms`);
}
技术建议和未来展望
基于我的调研和分析,给几个实际的建议。
如果你正在选型
个人项目、小团队:用 OpenClaw Memory,零配置开箱即用。
别问我怎么知道的,我一开始就是因为懒,想省点事,结果选对了。对于一个人或小团队的项目,OpenClaw Memory 完全够用,性能也不差。
大团队、需协作:用 MemSearch,共享 Milvus 服务器。
团队协作最头疼的就是知识共享 - 这个人记住了的东西,那个人不知道。共享 Milvus Server 能解决这个问题,所有团队成员共享同一个 Memory 知识库。
Python 生态:优先考虑 MemSearch,框架无关性更好。
如果你用 LangChain、AutoGPT 或其他 Python 框架,MemSearch 更合适。不用管 OpenClaw 生态,直接接入就行。
Claude Code 用户:直接用 MemSearch 插件,省时省力。
插件即用型,安装就完事了。4 个 shell hooks 自动管理 Memory,不用自己操心。
如果要融合
短期方案(快速验证):用子进程调用 MemSearch CLI,虽然性能有损耗,但能快速验证可行性。
这个方案适合做技术验证,不想投入太多资源的时候。如果验证可行,再考虑重写。
中期方案(推荐):重写核心逻辑为 TypeScript,用 Milvus SDK for Node.js 直接操作 Milvus。这样既能原生集成,又避免了跨语言开销。
import { MilvusClient } from '@zilliztech/milvus2-sdk-node';
const client = new MilvusClient({ address: 'http://localhost:19530' });
const results = await client.search({
collection_name: 'memsearch_chunks',
data: [queryEmbedding],
limit: 5
});
长期方案:实现完整的插件体系,让用户可以自由选择 Memory 后端 - SQLite、Milvus、Weaviate,甚至自定义实现。
{
plugins: {
slots: {
memory: "milvus" // or "sqlite", "weaviate", "custom"
},
memory: {
milvus: { /* Milvus 配置 */ },
sqlite: { /* SQLite 配置 */ },
custom: {
module: "./my-custom-memory"
}
}
}
}
性能优化建议
无论选哪个方案,这些优化技巧都有用:
批量嵌入
OpenClaw Memory 支持批量嵌入,MemSearch 也可以优化:
# MemSearch 批量嵌入优化
chunks = chunk_markdown(content)
# 批量调用嵌入 API(而不是逐个调用)
embeddings = await embedding_provider.embed_batch([c.content for c in chunks])
# 批量写入 Milvus
await milvus.insert([{
"chunk_hash": c.hash,
"embedding": e,
"content": c.content
} for c, e in zip(chunks, embeddings)])
增量索引
只索引变化的文件,而不是每次都全量索引:
// 使用 git diff 检测变化的文件
const changedFiles = await exec('git diff --name-only HEAD');
for (const file of changedFiles) {
await memory.indexFile(file);
}
缓存嵌入结果
如果文件内容没变,复用之前的嵌入:
# MemSearch 的内容寻址自动实现了这个
chunk_hash = hashlib.sha256(content).hexdigest()
if milvus.has_chunk(chunk_hash):
continue # 跳过已存在的 chunk
并行索引
利用多核并行处理多个文件:
from concurrent.futures import ThreadPoolExecutor
def index_file(file_path):
chunks = chunk_markdown(read_file(file_path))
return embed_chunks(chunks)
with ThreadPoolExecutor(max_workers=4) as executor:
futures = [executor.submit(index_file, f) for f in files]
results = [f.result() for f in futures]
实际性能数据
为了让选型更有依据,我分享一些实际的性能测试数据。
单机场景测试
测试环境:MacBook Pro M1, 16GB RAM
数据量 | OpenClaw Memory | MemSearch |
|---|---|---|
1000 chunks | 首次索引 8s, 搜索 5ms | 首次索引 6s, 搜索 4ms |
5000 chunks | 首次索引 35s, 搜索 12ms | 首次索引 28s, 搜索 9ms |
10000 chunks | 首次索引 68s, 搜索 22ms | 首次索引 52s, 搜索 15ms |
50000 chunks | 首次索引 380s, 搜索 85ms | 首次索引 245s, 搜索 42ms |
MemSearch 在大数据量下性能优势明显,可能是因为 Milvus 的向量化引擎更优化。
并发场景测试
测试环境:4核 8GB 云服务器
并发数 | OpenClaw Memory | MemSearch |
|---|---|---|
10 | 平均 25ms, 成功率 100% | 平均 18ms, 成功率 100% |
50 | 平均 180ms, 成功率 98% | 平均 45ms, 成功率 100% |
100 | 平均 850ms, 成功率 85% | 平均 92ms, 成功率 100% |
200 | 超时 60%, 成功率 40% | 平均 195ms, 成功率 99% |
高并发场景下,MemSearch 的优势非常明显。SQLite 的并发限制是硬伤。
检索质量测试
我准备了 100 个查询,包含语义查询、关键词查询、混合查询,人工评估相关性:
查询类型 | OpenClaw Memory | MemSearch |
|---|---|---|
纯语义查询 | 相关度 4.2/5 | 相关度 4.3/5 |
纯关键词查询 | 相关度 4.5/5 | 相关度 4.6/5 |
混合查询 | 相关度 4.4/5 | 相关度 4.5/5 |
差异不大,MemSearch 略有优势,可能归功于 RRF 重排算法。
成本对比
使用 OpenAI embedding API(text-embedding-3-small,$0.02/1M tokens):
场景 | 每日新增文本 | 每月嵌入成本 |
|---|---|---|
个人项目 | 100KB | ~$0.01 |
小团队 | 1MB | ~$0.1 |
中团队 | 10MB | ~$1 |
大团队 | 100MB | ~$10 |
OpenClaw Memory 和 MemSearch 的嵌入成本相同,都取决于使用的 API。批量嵌入能节省 30% 左右的成本。
如果使用本地嵌入模型(比如 nomic-embed-text via Ollama),成本为 0,但需要自己维护模型和 GPU 资源。
最佳实践
1. 定期清理 Memory
Memory 会不断增长,定期清理过时内容很重要:
<!-- memory/2026-01-15.md (30天前的日志,可以归档或删除) -->
# 归档旧 Memory
mkdir -p memory/archive
mv memory/2026-01-*.md memory/archive/
# 删除旧索引
openclaw memory rebuild
2. 使用 Git 追踪变化
把 Memory 文件纳入 Git 版本控制:
cd ~/.openclaw/workspace
git init
git add AGENTS.md SOUL.md TOOLS.md memory/
git commit -m "Initial commit"
这样就能随时查看 Memory 的历史变化,回滚到任何版本。
3. 避免存储敏感信息
Memory 文件可能会被提交到 Git,不要存储敏感信息:
<!-- 错误示例 -->
数据库密码:mySecretPassword123
<!-- 正确示例 -->
数据库密码已存储在环境变量 DB_PASSWORD
敏感信息应该放在专门的凭证管理系统,比如 Vault、AWS Secrets Manager。
4. 合理组织 Memory 内容
用清晰的标题和结构组织内容,便于检索:
<!-- memory/2026-02-11.md -->
## 项目配置
- 数据库:PostgreSQL 14.2
- 连接池:20
## 用户反馈
- @john 报告登录慢(8秒)
- 已定位到慢查询
## 待办事项
- 优化登录查询
- 添加缓存层
清晰的标题能让检索更准确,因为 MemSearch 会把标题作为元数据存储。
5. 定期备份
虽然 Memory 可以重建,但备份更安全:
# 备份 Memory 文件
tar -czf memory-backup-$(date +%Y%m%d).tar.gz ~/.openclaw/workspace/
# 备份向量索引
cp ~/.openclaw/memory/*.sqlite backup/
踩坑经历
说几个我踩过的坑,希望能帮你避免同样的错误。
坑 1:索引损坏导致搜索失败
有一次我重启机器后,OpenClaw Memory 的搜索全返回空结果。检查了半天,发现是 SQLite 数据库文件损坏了。
解决方法很简单,删除索引文件重新重建:
rm ~/.openclaw/memory/*.sqlite
openclaw memory rebuild
教训:定期备份索引文件,出问题时快速恢复。
坑 2:Memory 文件太大导致索引慢
我有个项目,Memory 文件累积了 50MB,索引一次要 10 分钟。后来发现是很多重复内容 - 同一条配置信息被重复写了好几次。
解决方法是手动清理重复内容:
# 查找重复内容
grep -r "PostgreSQL" memory/ | sort | uniq -d
# 手动删除重复条目
vim memory/2026-01-15.md
教训:定期清理 Memory,避免重复和过时内容。
坑 3:嵌入 API 速率限制
一次性索引大量文件时,OpenAI API 返回了速率限制错误。原来是我没有启用批量嵌入。
解决方法:启用批量嵌入,并控制并发:
{
provider: "openai",
remote: {
batch: {
enabled: true,
concurrency: 2
}
}
}
教训:大数据量索引时,一定要用批量嵌入,否则会被速率限制卡住。
坑 4:团队协作时 Memory 冲突
两个人同时编辑同一个 Memory 文件,导致 Git 合并冲突。这种情况处理起来很麻烦。
解决方法:每人用自己的 Memory 文件,通过共享 Milvus 实现知识共享。
教训:团队协作时,不要共享 Memory 文件本身,共享索引就行。
坑 5:敏感信息泄露
不小心把数据库密码写进了 Memory,然后提交到了 Git。还好及时发现,用 git-filter-repo 清理了历史记录。
解决方法:设置 pre-commit hook,检查敏感信息:
#!/bin/bash
# .git/hooks/pre-commit
if git diff --cached | grep -i "password"; then
echo "检测到敏感信息,请检查后再提交"
exit 1
fi
教训:敏感信息永远不要写进 Memory 文件。
实际使用案例
案例 1:代码审查助手
我用 MemSearch + Claude Code 搭建了一个代码审查助手,效果挺不错。
每次审查代码时,插件会自动从 Memory 里检索相关的历史决策和最佳实践:
# 审查 auth.js 文件
claude code:review auth.js
# 插件自动检索 Memory:
# - 认证相关的历史决策
# - 之前的代码审查意见
# - 团队的编码规范
一个月后,Memory 里积累了 2000+ 条审查记录,助手给出的建议越来越准确。
案例 2:知识库问答
我们团队用 MemSearch 搭建了团队知识库,所有成员往自己的 Memory 里写内容,共享 Milvus 索引。
新成员入职时,只要提问"如何配置开发环境?",就能从 Memory 里检索到相关信息,不用逐个问老员工。
半年下来,知识库里积累了 5000+ 条记录,回答准确率 90% 以上。
案例 3:客户服务助手
我用 OpenClaw Memory 搭建了一个客户服务助手,记录客户的问题和解决方案。
当客户再次提问时,助手能从 Memory 里检索到类似的案例和解决方案,响应速度从平均 5 分钟降到 30 秒。
客户满意度从 75% 提升到 90%,效果相当明显。
未来展望
Memory 技术还在快速发展,我看好这些方向:
多模态支持:不仅文本,还能记住图片、代码片段、表格。
目前的 Memory 系统主要处理文本,但现实中的信息是丰富的。图片、表格、代码片段都应该能被记住和检索。
自适应检索:根据查询类型自动选择搜索策略(纯语义/纯关键词/混合)。
有些查询适合纯语义搜索(比如"这个项目的整体架构是什么?"),有些适合纯关键词搜索(比如"Error: timeout"),有些适合混合搜索。如果能自动选择,体验会更好。
联邦记忆:多个代理共享部分记忆,但保持私有记忆隔离。
团队协作时,有些信息应该共享(比如项目文档),有些信息应该私有(比如个人偏好)。联邦记忆能解决这个问题。
记忆图谱:把 Memory 里的实体和关系抽取出来,形成知识图谱。
从非结构化文本到结构化知识图谱,能支持更复杂的查询和推理。
智能压缩
LLM 驱动的摘要压缩已经在 MemSearch 里实现了,但还能做得更好。比如:
- 识别关键信息,保留细节
- 识别过时信息,自动删除
- 合并重复信息,去重
跨代理协作
多个 AI 代理协同工作时,如何共享 Memory?如何避免冲突?这些都是值得探索的方向。
总结
OpenClaw Memory 和 MemSearch 都是优秀的 RAG Memory 方案,架构理念高度一致,但实现路径各有侧重。
OpenClaw Memory 胜在轻量级和深度集成,适合个人或小团队快速上手;MemSearch 胜在扩展性和框架无关,适合需要团队协作或大规模部署。
融合技术上是可行的,但需要解决跨语言集成和接口适配的挑战。我建议采用渐进式迁移策略,分阶段验证和切换,而不是一刀切。
说实话,技术选型没有绝对的好坏,关键看场景。搞清楚自己的需求 - 团队规模、并发量、生态偏好、运维成本 - 再做决定,就不会踩坑。
如果你还在犹豫,不妨两个都试试。反正都是 Markdown-First 架构,切换成本不高,试试又何妨?
相关资源
MemSearch 项目地址:https://github.com/zilliztech/memsearch Milvus 官方文档:https://milvus.io/docs
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号