Milvus 实测:43K Star 的向量数据库,到底强在哪?


🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 39 篇,Milvus最佳实战「2026」系列第 2 篇 大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。 我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、Milvus 向量数据库的技术实践者与开源布道者! Talk is cheap, let's explore。无界探索,有术而行。
全文信息图
一个数据:全球 80-90% 的数据是非结构化的。文本、图像、音频、视频,这些数据塞进 MySQL 里查不了,塞进 Elasticsearch 里效果也一般。
向量数据库就是为了解决这个问题而生的。
但向量数据库这个赛道,2026 年已经挤满了玩家。Milvus、Qdrant、Pinecone、Weaviate、Chroma、pgvector,光叫得上名字的就有十几个。选哪个?我花了几天时间把调研报告、社区讨论、GitHub Issues 翻了个遍,今天先聊 Milvus。
Milvus 到底是什么
一句话:Milvus 是 Zilliz 开发的开源向量数据库,专门为 GenAI 应用设计,目前已捐赠给 Linux 基金会旗下的 LF AI & Data Foundation,采用 Apache 2.0 许可证。
名字来源挺有意思。Milvus 是鹰科鸢属的拉丁学名,取的是鹰的速度和视觉敏锐度。
Milvus 提供三种部署模式,这一点对选型很关键:
Milvus Lite - 一个 Python 库,pip install 就能用。适合在 Jupyter Notebook 里做原型验证,几行代码跑通流程。
Milvus Standalone - 单机 Docker 部署。中小规模生产环境够用,不需要折腾 Kubernetes。
Milvus Distributed - Kubernetes 集群部署。大规模企业级场景,支持从百万到百亿级向量的弹性扩展。
三种模式的 API 完全兼容,代码从 Lite 迁移到 Distributed 不用改。这个设计思路确实省心。
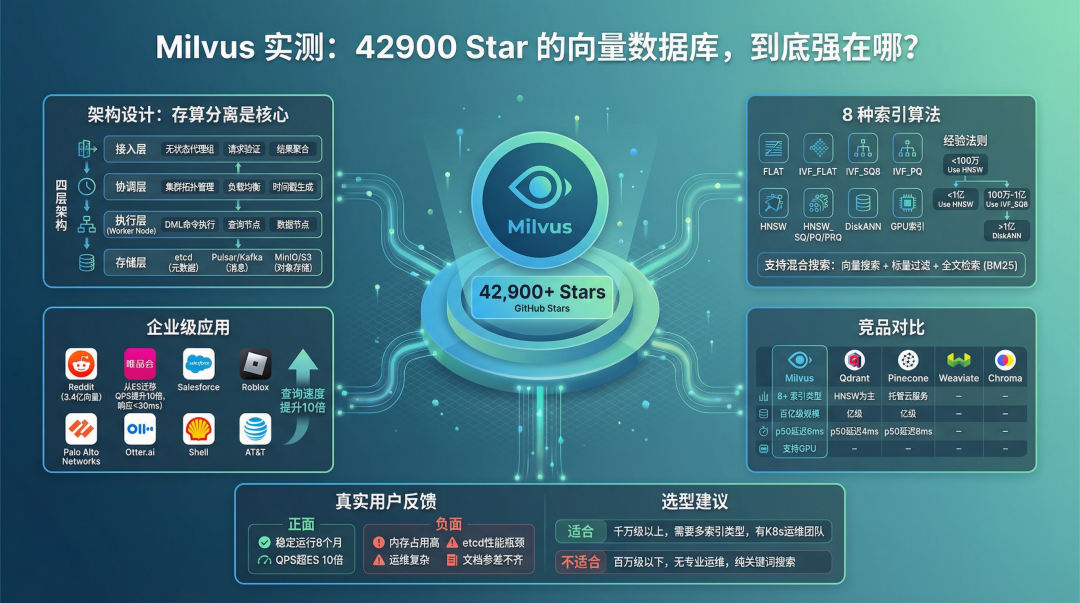
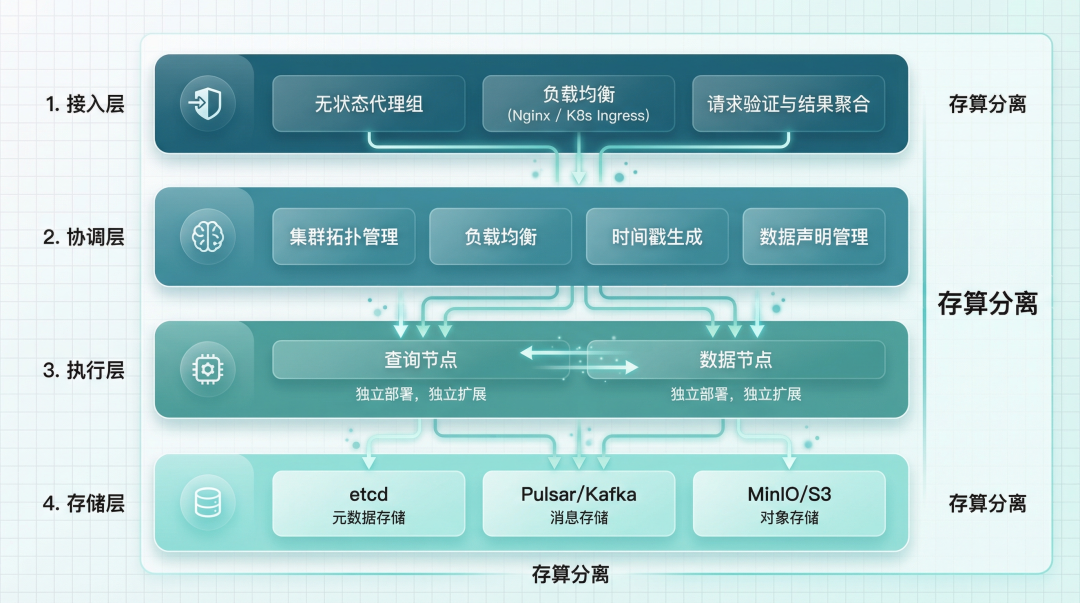
架构设计:存算分离是核心
翻了一遍 Milvus 的架构文档,核心设计理念就三条:存储与计算分离、控制平面与数据平面分离、云原生弹性扩展。
具体来说是四层架构:
接入层(Access Layer):无状态代理组,负责请求验证和结果聚合。前面挂 Nginx 或 K8s Ingress 做负载均衡。无状态意味着可以随便水平扩展,流量大了加节点就行。
协调层(Coordinator Layer):系统的大脑。负责集群拓扑管理、负载均衡、时间戳生成、数据声明管理。这一层决定了集群的调度效率。
执行层(Worker Node):干活的。执行协调层下发的指令和 DML 命令。查询节点和数据节点分开部署,互不干扰。
存储层(Storage):这一层拆成了三块:
- 元数据存储用 etcd,存 schema、节点状态、checkpoint
- 消息存储用 Pulsar 或 Kafka(2.6 版本新增了 Woodpecker 日志系统可以替代)
- 对象存储用 MinIO、S3 或 Azure Blob
存算分离的好处很直接:计算资源和存储资源可以独立扩缩容。查询压力大了加查询节点,数据量大了扩存储,互不影响。但代价也很明显 - 组件多了,运维复杂度直线上升。这个后面会细说。
四层架构图
8 种索引算法,覆盖全场景
Milvus 在索引类型上的丰富程度,是它和竞品拉开差距的地方。整理了一张表:
索引类型 | 原理 | 适用场景 | 关键特点 |
|---|---|---|---|
FLAT | 暴力搜索 | 小数据集精确搜索 | 100% 召回率,速度慢 |
IVF_FLAT | 倒排文件 + 暴力搜索 | 中等数据集 | 平衡速度和精度 |
IVF_SQ8 | 倒排文件 + 标量量化 | 大数据集,内存受限 | 节省 70-75% 内存 |
IVF_PQ | 倒排文件 + 乘积量化 | 超大数据集 | 压缩比高,精度有损 |
HNSW | 层次化可导航小世界图 | 高性能搜索 | 速度快,内存占用高 |
HNSW_SQ/PQ/PRQ | HNSW + 量化 | 大规模 + 高性能 | 平衡内存和速度 |
DiskANN | 基于 SSD 的图索引 | 十亿级向量 | 内存占用极低 |
GPU 索引 | GPU 加速 | 超高吞吐场景 | 需要 GPU 硬件 |
这里面有个数据值得关注:DiskANN 可以在 SSD 上索引十亿级向量,95% 搜索精度下延迟仅 5ms,内存占用只有 HNSW 的一小部分。对于数据量大但预算有限的团队,这个索引类型很实用。
选索引的经验法则:数据量小于 100 万用 HNSW,100 万到 1 亿用 IVF_SQ8,超过 1 亿考虑 DiskANN。当然具体还要看维度、QPS 要求和硬件条件。
除了向量搜索,Milvus 还支持混合搜索:向量搜索 + 标量过滤 + 全文检索(BM25)组合。2.6 版本还升级了多语言全文搜索。这意味着你可以在一次查询里同时做语义匹配和关键词过滤,不用在应用层拼接多个查询结果。
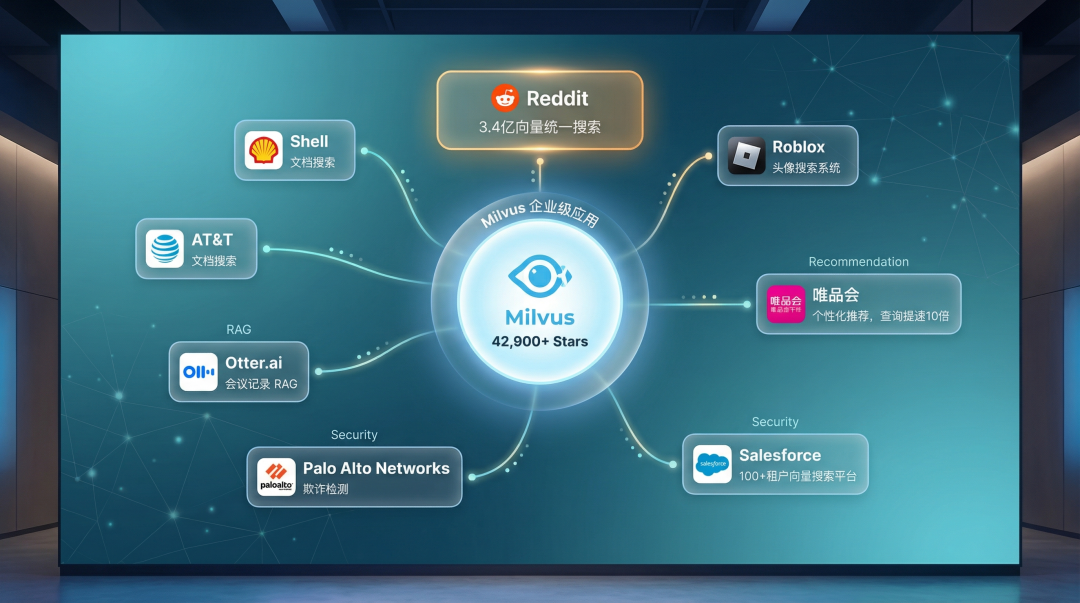
谁在用 Milvus?
说再多技术细节,不如看谁在生产环境跑。
企业应用生态图
Reddit 的选型故事最有说服力。 Reddit 之前各团队用的向量搜索方案五花八门:FAISS、Solr ANN、Vertex AI、Redis、pgvector,碎片化严重。他们花了大量时间做公司级统一选型,评估了 Qdrant、Milvus、Vespa、Weaviate 四个候选,在 Kubernetes 环境中对 3.4 亿向量做了负载测试。
结果选了 Milvus。但有意思的是,Reddit 的工程师明确说了:不是因为 Milvus 跑分最高。原话是这样的:
After testing Qdrant, Milvus, Vespa, and Weaviate, our final choice was Milvus — not because it 'won' every benchmark, but because it fit Reddit's engineering culture, scaled cleanly with replication, and was easier to operate at our scale.
翻译一下:没有一个数据库在所有维度都赢,选 Milvus 是因为工程文化契合度、复制扩展能力和运维便利性。这个选型逻辑比单纯看跑分靠谱多了。
唯品会的案例也值得看。 他们基于 Milvus 搭建个性化推荐系统,从 Elasticsearch 迁移过来后,查询速度提升了 10 倍,百万级向量搜索响应时间压到了 30 毫秒以内。
其他在用 Milvus 的公司还包括:Salesforce(100+ 租户的内部向量搜索平台)、Roblox(头像搜索系统)、Palo Alto Networks(欺诈检测)、Otter.ai(会议记录 RAG)、Shell(文档搜索)、AT&T(文档搜索)。
你在项目中用过向量数据库吗?欢迎在评论区聊聊你的选型经历。
和竞品比,Milvus 赢在哪、输在哪
直接上对比表:
维度 | Milvus | Qdrant | Pinecone | Weaviate | Chroma |
|---|---|---|---|---|---|
类型 | 开源分布式 | 开源 | 托管云服务 | 开源 | 开源轻量 |
开发语言 | Go + C++ | Rust | 闭源 | Go | Python |
索引类型 | 8+ 种 | HNSW 为主 | 专有索引 | HNSW | HNSW |
规模上限 | 百亿级 | 亿级 | 亿级 | 亿级 | 百万级 |
p50 延迟 | 6ms | 4ms | 8ms | 12ms | 15ms |
GPU 支持 | 有 | 无 | 无 | 无 | 无 |

竞品多维对比图
几个关键结论:
延迟不是 Milvus 的强项。 Qdrant 的 p50 延迟是 4ms,Milvus 是 6ms。如果你的场景对延迟极度敏感且数据量不大,Qdrant 可能更合适。
索引丰富度是 Milvus 的护城河。 8 种以上的索引算法,从内存到磁盘、从 CPU 到 GPU 全覆盖。其他竞品基本只有 HNSW 一种选择。
规模上限差距明显。 百亿级向量只有 Milvus 能扛。如果你的数据量在千万级以下,这个优势体现不出来。
还有一个争议点值得提:你可能根本不需要专用向量数据库。 对于百万级以下的向量,PostgreSQL 的 pgvector 扩展可能就够了。引入 Milvus 意味着多了一套基础设施要维护,这个成本不能忽视。有人在博客里算过一笔账:Pinecone 托管服务月费 ,用于本应200 就能搞定的工作负载,最终被迫迁移到自托管方案。
真实用户怎么说
正面的声音不少。Toolstac 上有个用了 8 个月的用户评价很直白:
It's a vector database that doesn't randomly shit the bed when you scale past your laptop. I've been running it for 8 months and it hasn't woken me up with production alerts.
PeerSpot 上的评价也偏正面:准确性和性能不错,容器化做得好,扩展速度快。
CSDN 上有人做了性能测试:在 100 万向量串行执行场景下,Milvus 延迟低于 3ms,QPS 超过 Elasticsearch 10 倍以上。这个数据和唯品会的案例互相印证。
但负面反馈也不少,而且集中在几个点:
内存占用是老大难问题。 GitHub 上有多个 Issue 报告内存异常。Issue #32695 反映 v2.4.0 的 datanode 内存使用过高;Issue #40270 报告 2 亿向量场景下内存和 MinIO CPU 占用异常。HNSW 索引本身就吃内存,mmap 启用后行为不直观,OOM 是社区里的高频话题。
etcd 是隐藏的性能瓶颈。 有用户在 Milvus 2.4.17 standalone 环境中遇到 etcd 操作延迟超过 7 秒导致服务不稳定。根本原因是磁盘利用率 95% 以上,etcd 对磁盘 I/O 要求极高,机械硬盘或低性能 SSD 扛不住。
运维复杂度被低估了。 分布式部署需要 etcd + MinIO/S3 + Pulsar/Kafka + 多种 Node,组件数量远超 Qdrant 这类单进程方案。多位用户反映低估了运维成本。
文档质量参差不齐。 PeerSpot 用户反映文档不够完善,尤其是高级配置和性能调优方面。说实话,翻文档的时候我也有同感,基础功能的文档写得不错,但一旦涉及到生产环境的调优,能找到的参考就少了很多。
常见踩坑
整理社区反馈的时候,发现大家踩的坑出奇一致:
坑 1:索引配置不当导致检索慢。 用 FLAT 索引 + 高维 embedding(1024+)+ 无分区,百万级 chunk 检索极慢。解决方案:根据数据规模选合适的索引,合理设置分区和 shard。
坑 2:etcd 磁盘性能不足导致服务崩溃。 etcd 对磁盘 IOPS 要求高,99 分位延迟要低于 10ms。建议用高性能 SSD,为 etcd 分配专用存储设备。
坑 3:shard 数目不合理。 官方建议单表不超过 8 个 shard,消息队列 topic 默认 256 个,副本数建议不超过 10 个。这些参数配错了,性能会断崖式下降。
选型建议
说到底,选不选 Milvus 取决于你的场景和团队能力。
适合用 Milvus 的场景:
- 数据量在千万级以上,需要分布式扩展
- 需要多种索引类型灵活切换(内存索引、磁盘索引、GPU 索引)
- 有专业的 K8s 运维团队
- 需要混合搜索(向量 + 标量 + 全文检索)
不太适合的场景:
- 数据量在百万级以下,Chroma 或 pgvector 更简单
- 没有专业运维团队,建议用 Milvus Lite 或 Standalone,别碰分布式
- 纯关键词搜索,Elasticsearch 更成熟
- 需要强事务一致性,Milvus 不是关系型数据库
向量数据库市场正在快速增长。据 Fundamental Business Insights 的报告,全球向量数据库市场规模 2024 年为 22 亿美元,预计 2035 年达到 188.6 亿美元,年复合增长率 23%。Milvus 作为这个赛道里功能覆盖面最广的开源方案,大概率会继续吃到市场红利。
相关资源
官方文档:https://milvus.io/docs
GitHub 仓库:https://github.com/milvus-io/milvus
官方容量规划工具:https://milvus.io/tools/sizing
开源基准测试工具 VectorDBBench:https://github.com/zilliztech/VectorDBBench
Zilliz Cloud(托管服务):https://zilliz.com
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号