AI 编码总返工?OpenSpec 最佳实战:3 步工作流 × 3 种场景,新老项目通用

AI 编码总返工?OpenSpec 最佳实战:3 步工作流 × 3 种场景,新老项目通用

运维有术
发布于 2026-04-01 20:09:47
发布于 2026-04-01 20:09:47
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 67 篇,OpenSpec 实战「2026」系列第 10 篇 大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。 我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者! Talk is cheap, let's explore。无界探索,有术而行。
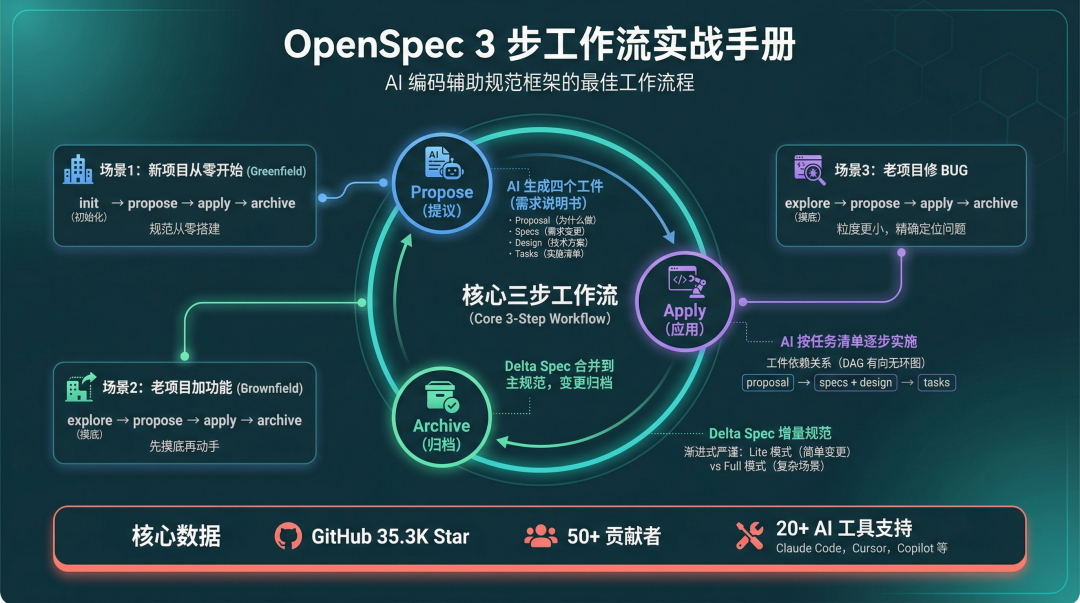
AI 编码总返工?OpenSpec 实战 - 信息图封面
图 1:OpenSpec 3 步工作流 × 3 种场景概览
你用 AI 编码助手写功能,有没有遇到过这种情况:需求描述了一通,AI 理解成了另一个意思,写出来的代码完全不是你要的。来回改了三四遍,花的时间比自己写还多。
更头疼的场景:一个跑了两年的老项目,你想加个暗黑模式,跟 AI 说在现有样式基础上加,结果它把 CSS 改得面目全非,还顺带影响了别的页面。
返工的根源通常是同一个问题:你和 AI 对要做什么没有达成共识。
OpenSpec 就是专门解决这个问题的。它是一个规范驱动开发框架(GitHub 35.3K Star,50+ 贡献者),核心理念就一句话:先花几分钟和 AI 对齐需求,再动手写代码。
说得更直白一点:OpenSpec 帮你在编码前生成一份结构化的需求说明书,你和 AI 都对着这份说明书干活。它不只适用于某个 AI 工具 - Claude Code、Cursor、GitHub Copilot、Windsurf 等 20 多种 AI 编码助手都能用,生成的那套规范文件跟着代码仓库走,换工具也不用重来。
这篇文章用三个真实场景:新项目从零开始、老项目加功能、老项目修 BUG 。完整演示 OpenSpec 的工作流程,每个场景都附带可以直接参考的 spec 文件示例。
1. OpenSpec 是什么
OpenSpec 的核心设计可以用两组目录说清楚:
specs/— 规范真相源,记录系统当前的行为,按领域组织。比如specs/auth/spec.md描述认证模块,specs/payments/spec.md描述支付模块changes/— 变更提案,每次改动一个独立文件夹,完成之后归档
每个变更文件夹包含四个工件:
工件 | 文件 | 作用 |
|---|---|---|
Proposal | proposal.md | 为什么做、做什么 |
Specs | specs/ | 需求变更(Delta Spec) |
Design | design.md | 技术方案 |
Tasks | tasks.md | 实施清单(带复选框) |
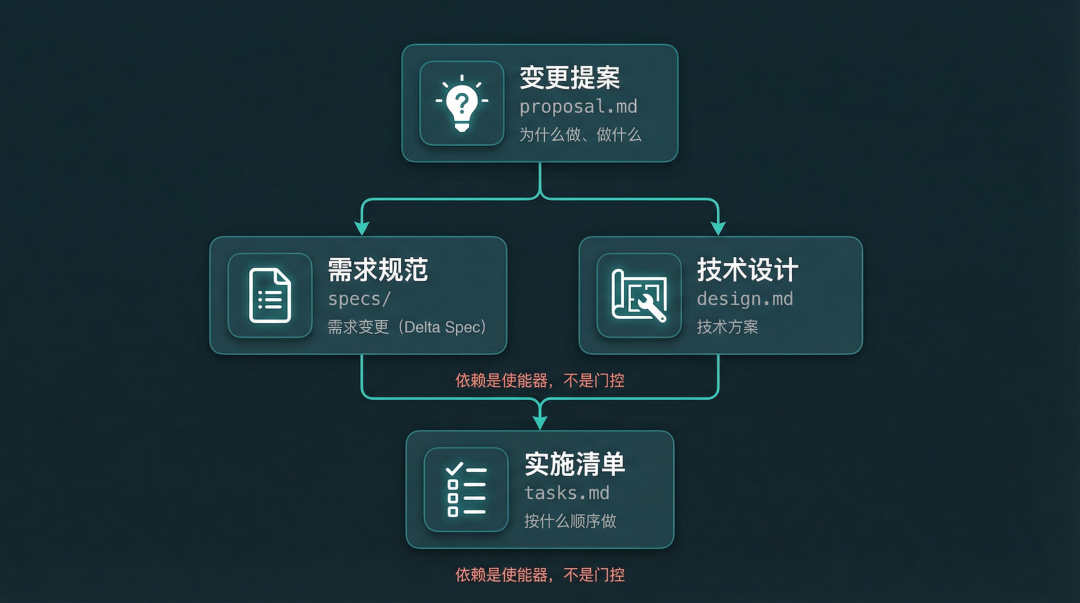
工件依赖关系 DAG 图
图 2:四个工件的 DAG 依赖关系
这四个工件之间有依赖关系,形成一个 DAG(有向无环图)。proposal 是根节点,specs 和 design 都依赖它,tasks 依赖前两者。但这个依赖是使能器而非门控 - 你可以跳过 design,也可以先写 specs 再写 design,顺序完全自由。官方的说法是:依赖告诉你可以先做什么,而不是必须先做什么。
这里还有一个核心概念需要理解:Delta Spec(增量规范)。传统规范工具要求你维护一整份系统文档,每次改动都要重写。Delta Spec 只描述改变了什么,用四种操作标记:
- ADDED — 新增需求,归档时追加到主规范
- MODIFIED — 修改需求,归档时替换已有版本
- REMOVED — 删除需求,归档时从主规范移除
- RENAMED — 重命名需求,归档时更改标题
这个设计对老项目特别友好。你不需要先把整个系统文档化,每次变更只描述增量部分,逐步积累规范。打个比方:传统方式是维护一整本系统手册,每次改版要通读全文;Delta Spec 只是在手册旁边贴一张便签,写清楚这一页改了什么。归档的时候,便签的内容自动合并到手册里。
OpenSpec 还有一个重要设计理念:渐进式严谨。简单变更用 Lite 模式就行,几行需求加几个场景就够;涉及跨团队、跨仓库、API 契约变更的复杂场景,才需要用 Full 模式写更详细的规范。大多数日常变更用 Lite 模式就够了,不用把流程搞得很重。
2. 安装与初始化
OpenSpec 基于 Node.js,需要 20.19.0 或更高版本。安装过程很简单:
# 全局安装
npm install -g @fission-ai/openspec@latest
# 进入你的项目目录
cd your-project
# 初始化(交互式,会问你用哪个 AI 工具)
openspec init
# 升级后刷新指令文件
openspec update
初始化完成后,项目根目录会生成 openspec/ 文件夹。文件夹结构如下:
openspec/
├── specs/ # 规范真相源
└── changes/ # 变更提案
└── archive/ # 已归档的变更
OpenSpec 支持 20 多种 AI 编码工具的原生集成,包括 Claude Code、Cursor、GitHub Copilot、Windsurf、Gemini CLI、Cline、RooCode 等。初始化时选你用的工具,它会自动在对应目录生成 Skills 和 Commands 文件。比如选了 Claude Code,就会在 .claude/skills/ 和 .claude/commands/ 下生成相关文件。
如果你同时用多个工具(比如 Cursor 写前端、Claude Code 做重构),初始化时可以一次选多个:
openspec init --tools claude,cursor
整个核心工作流只有三个命令,形成闭环:
/opsx:propose → /opsx:apply → /opsx:archive
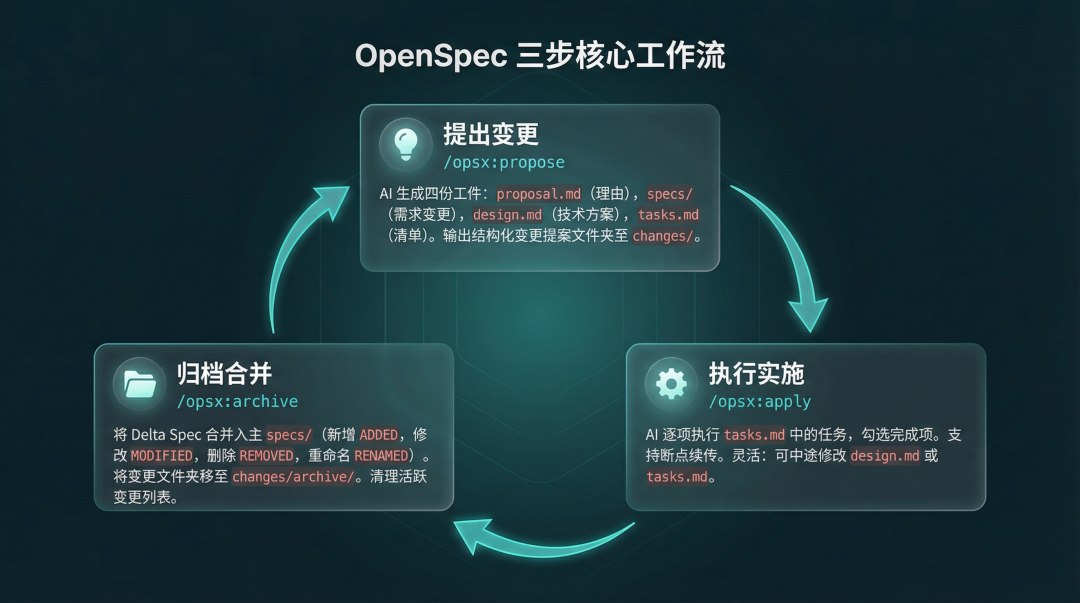
核心三步工作流闭环
图 3:propose → apply → archive 核心三步工作流
下面用三个场景分别演示。每个场景的侧重点不同,但底层的三步流程是一样的。
3. 场景一:新项目从零开始

新项目 Greenfield 工作流程图
图 4:新项目从零开始的完整工作流
新项目的特点是:没有历史包袱,规范从零搭建,每次功能迭代都会让系统规范更加完整。
假设你要启动一个新的待办事项应用。
3.1 初始化项目
mkdir todo-app && cd todo-app
git init
openspec init
初始化时选择你用的 AI 工具(比如 Claude Code)。然后编辑 openspec/config.yaml,写上项目的技术栈:
schema: spec-driven
context: |
Tech stack: React 18, TypeScript, Vite
Backend: Node.js + Express
Database: SQLite (development)
Testing: Vitest
Style: Tailwind CSS
这个 context 字段会被注入到所有工件的生成指令中。写得越具体,AI 给出的方案越贴合你的项目。上限 50KB,足够写非常详细的技术栈说明了。
3.2 创建变更
在 Claude Code 中执行:
/opsx:propose add-todo-crud
AI 会一次性生成四个工件:proposal.md 说清楚为什么要做这个功能、specs/ 定义需求变更、design.md 给出技术方案、tasks.md 列出实施步骤。
来看生成的 specs/todo/spec.md(主规范):
# Todo Specification
## Purpose
Manage todo items with CRUD operations.
## Requirements
### Requirement: Create Todo
The system SHALL allow users to create new todo items
with a title and optional description.
#### Scenario: Valid todo creation
- **GIVEN** the user is on the todo list page
- **WHEN** the user submits a new todo with a title
- **THEN** the todo is added to the list
- **AND** the input field is cleared
#### Scenario: Empty title rejection
- **GIVEN** the user is on the todo list page
- **WHEN** the user submits a todo with an empty title
- **THEN** an error message is displayed
### Requirement: Toggle Todo Completion
The system SHALL allow users to mark todos as
complete or incomplete.
#### Scenario: Mark as complete
- **GIVEN** a todo item with status "incomplete"
- **WHEN** the user clicks the toggle button
- **THEN** the todo status changes to "complete"
这里有个新手常踩的坑:#### Scenario: 必须用四个 #。写成三个 # 或者 bullet 列表,OpenSpec 解析时会静默失败 - 不会报错,但归档时 Delta Spec 合并不进去。这个问题在官方 GitHub issue 里出现频率很高。
另外注意规范里用到的 RFC 2119 关键词:SHALL 表示绝对要求,MUST 表示强制要求,SHOULD 表示推荐做法,MAY 表示可选。这些关键词让需求强度有了明确的区分。
再看看 tasks.md(实施清单):
## Tasks
### 1. Data Layer
- [ ] 1.1 Define Todo type interface
- [ ] 1.2 Create SQLite schema for todos table
- [ ] 1.3 Implement CRUD repository functions
### 2. API Layer
- [ ] 2.1 Create Express router for /api/todos
- [ ] 2.2 Implement POST /api/todos endpoint
- [ ] 2.3 Implement GET /api/todos endpoint
- [ ] 2.4 Implement PATCH /api/todos/:id endpoint
- [ ] 2.5 Implement DELETE /api/todos/:id endpoint
### 3. UI Layer
- [ ] 3.1 Create TodoInput component
- [ ] 3.2 Create TodoList component
- [ ] 3.3 Create TodoItem component with toggle
- [ ] 3.4 Wire up API calls in custom hook
任务清单的好处是,你和 AI 都能清楚地看到进度。而且任务被拆成了不超过 2 小时的小块,方便逐步交付。
3.3 实施和归档
/opsx:apply
AI 按 tasks.md 的顺序逐个完成任务,完成一个就把 - [ ] 改成 - [x]。中途被打断没关系,下次运行 /opsx:apply 会从上次停下的地方继续。
实施过程中如果发现设计有问题,可以直接修改 design.md 或 tasks.md,不需要重新走流程。这也是 OpenSpec 灵活而非僵化的设计思路。
/opsx:archive
归档做了三件事:把 Delta Spec 合并到主规范 specs/,把变更文件夹移到 changes/archive/2026-03-29-add-todo-crud/,清理活跃变更列表。
到这里,项目里就有了一份可用的系统规范。下一个功能(比如加用户认证、加搜索功能)会基于这份规范继续生长。每做一次功能,specs/ 就更完整一点,新加入的开发者也可以直接翻阅规范来理解系统。
如果你用的是 Expanded Profile(通过 openspec config profile 启用),还可以在 apply 之后跑一遍 /opsx:verify。它从三个维度验证实现质量:Completeness(所有任务完成了吗?所有需求覆盖了吗?)、Correctness(实现匹配规范意图吗?边界情况处理了吗?)、Coherence(设计决策是否反映在代码中?模式是否一致?)。这个验证步骤对团队项目很有用,个人小项目可以省略。
4. 场景二:老项目加新功能
老项目和新建项目不一样 - 代码已经存在,你未必了解每个细节,而且不能随意改动现有逻辑。OpenSpec 专门为这种情况设计了 Brownfield 工作流。

老项目 Brownfield 加功能工作流
图 5:老项目加新功能的 Brownfield 工作流
核心区别在于:新项目可以直接 propose,老项目建议先 explore。
4.1 先探索再动手
假设你接手了一个 React 项目,老板要求加暗黑模式。别急着 propose,先用 explore 摸个底:
/opsx:explore
AI 会问你:想探索什么?
你回复:我想加暗黑模式,但不确定当前项目的样式结构。
AI 分析代码库后告诉你:当前用的是 CSS Modules 和 Tailwind 混合方案;主题色硬编码在十几个组件里;有个 useTheme hook 但只有字体大小切换功能。
这个探索过程不创建任何文件,纯粹是帮你理清现状。探索完你心里就有数了:主题色散落各处需要收敛,useTheme hook 可以扩展复用。
4.2 创建变更
/opsx:propose add-dark-mode
因为是老项目加功能,AI 生成的 Delta Spec 会用 ADDED 和 MODIFIED 标记:
# Delta for UI
## ADDED Requirements
### Requirement: Dark Mode Theme
The system SHALL support a dark color scheme
that applies globally across all components.
#### Scenario: Toggle dark mode
- **GIVEN** the user is in light mode
- **WHEN** the user clicks the theme toggle
- **THEN** all UI components switch to dark color scheme
- **AND** the preference is saved to localStorage
#### Scenario: Persist theme preference
- **GIVEN** a user with dark mode preference saved
- **WHEN** the user opens the application
- **THEN** the application loads in dark mode
## MODIFIED Requirements
### Requirement: Theme Management
The system SHALL manage theme state through a ThemeContext
with light, dark, and system preferences.
(Previously: only font size management)
这里能看到 Delta Spec 的实用之处 - 不需要重写整个 UI 规范,只说清楚新增了什么、修改了什么。ADDED 表示这是全新加入的功能,MODIFIED 表示已有的 Theme Management 需要扩展,括号里注明了修改前的内容。
对于老项目,你不用预先把整个系统文档化。每次变更都会让 specs/ 越来越完整,这是一个渐进式的过程。用几次之后,你的项目规范就自然成型了。
你在老项目中用过类似的方案吗?是倾向于先全面文档化,还是边做边补?欢迎在评论区聊聊。
4.3 实施和归档
和新项目一样:/opsx:apply 实施,/opsx:archive 归档。归档时 Delta Spec 自动合并到主规范 - ADDED 的内容追加到主规范,MODIFIED 的内容替换已有版本。下次再改 UI 相关功能,就有更完整的规范做基础了。
如果你好奇归档合并的细节:源码中定义了严格的顺序 - 先执行 RENAMED(重命名),再执行 REMOVED(删除),然后 MODIFIED(替换),末尾 ADDED(追加)。这个顺序确保每一步操作都基于干净的状态,避免冲突。
5. 场景三:老项目修 BUG
修 BUG 和加功能的工作流有个关键区别:粒度更小,重点在于精确定位问题行为。
修 BUG 时,Delta Spec 通常只用 MODIFIED - 你不是在新增功能,而是在修正已有行为的 bug。规范里要写清楚修改前后的行为差异,这让代码审查非常直观。
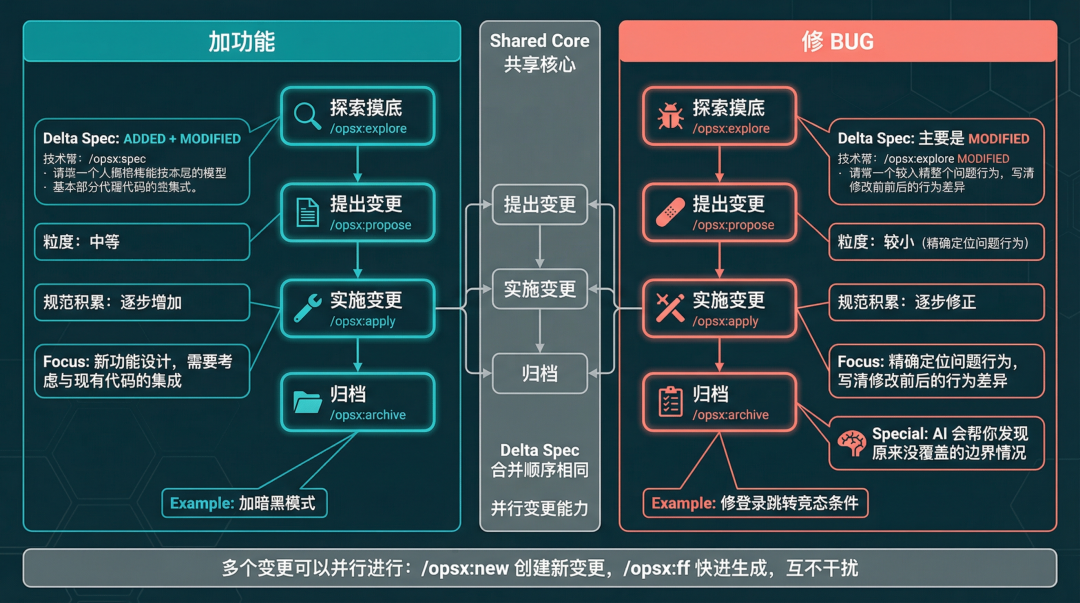
老项目修 BUG 工作流对比
图 6:老项目加功能 vs 修 BUG 工作流对比
5.1 定位问题
还是先 explore:
/opsx:explore
用户反馈登录后偶尔跳转到错误页面。你让 AI 分析代码,它告诉你:login 成功后的 redirect 逻辑里有个竞态条件 - auth token 还没写入 localStorage,路由就已经跳转了。
5.2 创建修复变更
/opsx:propose fix-login-redirect
Delta Spec 这次主要是 MODIFIED:
# Delta for Auth
## MODIFIED Requirements
### Requirement: Post-Login Redirect
The system SHALL redirect to the intended page only after
the auth token is confirmed written to storage.
(Previously: redirect immediately after API response)
#### Scenario: Successful login redirect
- **GIVEN** a user submits valid credentials
- **WHEN** the auth API returns success
- **THEN** the system writes the token to localStorage
- **AND** waits for storage write confirmation
- **AND** redirects to the originally intended page
#### Scenario: Storage write failure
- **GIVEN** a user submits valid credentials
- **WHEN** the auth API returns success
- **AND** localStorage write fails
- **THEN** an error message is displayed
- **AND** the user remains on the login page
注意规范里 (Previously: redirect immediately after API response) 这行 - 它明确标注了修改前的行为。代码审查的时候,审查者不需要翻代码就能理解这个 BUG 修了什么、为什么这样修。
另外注意新增的 Storage write failure 场景 - 修 BUG 的过程中,AI 会帮你想到原来没覆盖的边界情况。这也是 spec-driven 开发的一个附带好处:逼着你想清楚异常场景。
5.3 并行变更
OpenSpec 有个实用的功能:多个变更可以并行进行。
比如你正在做 add-dark-mode,突然要修这个登录 BUG。不用放弃暗黑模式的进度:
/opsx:new fix-login-redirect
创建新变更,快进生成所有工件:
/opsx:ff
完成修复和归档后,回到暗黑模式继续:
/opsx:apply add-dark-mode
AI 会告诉你:Resuming add-dark-mode... Picking up at task 2.3。从上次停下的地方继续,两个变更互不影响,各自有独立的工件和 Delta Spec。
这个并行能力在团队场景下尤其有用 - 两个人同时做不同的变更,各自 propose、apply、archive,互不干扰。
6. 实战技巧与常见坑
6.1 格式陷阱:Scenario 必须用 ####
这是新用户踩得很多的一个坑。OpenSpec 的 spec 文件里,Scenario 必须用四级标题(四个 #):
✅ 正确:
#### Scenario: Valid login
- **WHEN** user submits credentials
- **THEN** token is returned
❌ 错误(三级标题,解析会静默失败):
### Scenario: Valid login
❌ 错误(bullet 列表,同样解析失败):
- Scenario: Valid login
用错了不会报错,但归档时 Delta Spec 会被静默忽略。官方 GitHub issue 里有不少人提到这个问题。说实话,这个设计有点反直觉 - 毕竟 Scenario 看起来和 Requirement 是同级的概念,但它偏偏要求用四级标题。记住了就好。
6.2 MODIFIED 要写完整内容
MODIFIED 不是 diff,必须包含整个 requirement 的完整内容(从 ### Requirement: 到所有 scenarios)。如果你只写变化的部分,归档时会丢失未提及的细节。
✅ 正确(完整内容):
## MODIFIED Requirements
### Requirement: Session Timeout
The system SHALL expire sessions after 30 minutes
of inactivity.
(Previously: 60 minutes)
#### Scenario: Idle timeout
- **GIVEN** an authenticated session
- **WHEN** 30 minutes pass without activity
- **THEN** the session is invalidated
❌ 错误(只写了变化的部分):
## MODIFIED Requirements
### Requirement: Session Timeout
Changed from 60 to 30 minutes.
一个简单的判断方法:如果只是增加新的关注点而不改变现有行为,用 ADDED;如果要改的是已有的 requirement,用 MODIFIED 并提供完整内容。
6.3 Spec 写什么、不写什么
OpenSpec 的 spec 文件有明确的边界,这个边界想清楚了,写出来的 spec 质量会高很多:
应该写:可观察的行为(输入什么、输出什么、错误条件)、外部约束、可验证的场景。简单来说就是站在系统外部能看到的东西
不应该写:内部类/函数名、框架选型、逐步实现细节 - 这些属于 design.md 和 tasks.md
换句话说,spec 描述系统做什么,design 描述怎么做,tasks 描述按什么顺序做。把这三层的职责分清,不要在 spec 里写实现细节,也不要在 design 里重复描述需求。
6.4 变更粒度:一个逻辑单元 = 一个变更
好的命名:
add-dark-mode ✅ 语义清晰
fix-login-redirect ✅ 描述具体
optimize-product-query ✅ 动作 + 目标
避免的命名:
feature-1 ❌ 无意义
update ❌ 太模糊
wip ❌ 不描述内容
一个经验法则:如果你要用和来描述一个变更(加功能 X 和重构 Y),那就应该拆成两个变更。好处是审查更清晰、归档历史更完整、可以独立交付和回滚。
6.5 何时更新 vs 何时新建
情况 | 操作 |
|---|---|
意图相同,执行微调 | 更新当前变更 |
发现代码库和预期不同 | 更新当前变更 |
范围收窄(先 MVP 后续再加) | 更新当前变更 |
意图根本改变 | 新建变更 |
范围膨胀超过 50% | 归档当前后新建 |
原变更可以独立完成 | 归档后新建 |
6.6 用好 config.yaml 的 context 字段
这个字段会注入到所有工件的生成指令中。写得越具体,AI 生成的方案越贴合实际。下面是一个比较完善的 context 示例:
context: |
Tech stack: TypeScript, React 18, Node.js, PostgreSQL
API style: RESTful, JSON responses
Testing: Vitest for unit tests, Playwright for e2e
Important: All public APIs must maintain backwards compatibility
你还可以给不同的工件加专属规则,通过 rules 字段:
rules:
proposal:
-Includerollbackplan
-Identifyaffectedteams
specs:
-UseGiven/When/Thenformat
-Referenceexistingpatternsbeforeinventingnewones
design:
-Includesequencediagramsforcomplexflows
tasks:
-Breakinto2-hourmaximumchunks
这样 AI 在生成 proposal 的时候会自动考虑回滚方案,在生成 tasks 的时候会把任务拆成小块。
6.7 模型选择
官方文档建议使用推理能力强的模型,比如 Claude Opus 4.6 和 GPT 5.4。实际测试下来,推理能力更强的模型生成的 spec 质量确实更好,特别是在处理复杂场景(跨模块变更、API 契约修改)的时候。
本文中的三个场景实战测试用的是 MiniMax M2.7,生成 spec 和 Delta Spec 的表现都不错,日常场景足够用。
如果只是小功能的 spec,普通模型也能胜任。
7. 三种场景对比
维度 | 新项目 | 老项目加功能 | 老项目修 BUG |
|---|---|---|---|
起点 | 空目录 | 已有代码 | 已有代码 + BUG 报告 |
推荐命令 | propose | explore → propose | explore → propose |
Delta Spec | 主要是 ADDED | ADDED + MODIFIED | 主要是 MODIFIED |
规范积累 | 从零搭建 | 逐步增加 | 逐步修正 |
变更粒度 | 中等 | 中等 | 较小 |
并行需求 | 较少 | 可能并行 | 经常并行 |
不管哪种场景,底层的 propose → apply → archive 三步是一样的。区别在于:进入 propose 之前要不要先 explore,Delta Spec 用哪些操作类型,以及变更的粒度大小。
总结
OpenSpec 的三步工作流,本质上做了一件事:让你和 AI 在写代码前花几分钟对齐需求,省去后面几小时的返工。
三个要点:
- 新项目:
init+propose就能起步,不用把整个系统设计完再动手,边做边积累规范 - 老项目加功能:
explore先摸底,用 Delta Spec 只描述变更,不用预先文档化整个系统 - 老项目修 BUG:规范里写清修改前后的行为差异,代码审查更有据可依
如果你的团队也在用 AI 编码助手,建议先在一个小功能上跑一轮完整的 propose → apply → archive 流程,感受一下规范驱动开发的节奏。不用一开始就追求完美的 spec 格式:先跑通流程,再慢慢打磨规范的质量。如果觉得有用,转发给你的同事看看。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号