Claude Code 源码泄露:5 个 Agent 设计模式拆解,全网首发!

Claude Code 源码泄露:5 个 Agent 设计模式拆解,全网首发!

术哥
发布于 2026-04-01 20:17:48
发布于 2026-04-01 20:17:48
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 69 篇,AI 星探「2026」系列第 8 篇 大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。 我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者! Talk is cheap, let's explore。无界探索,有术而行。
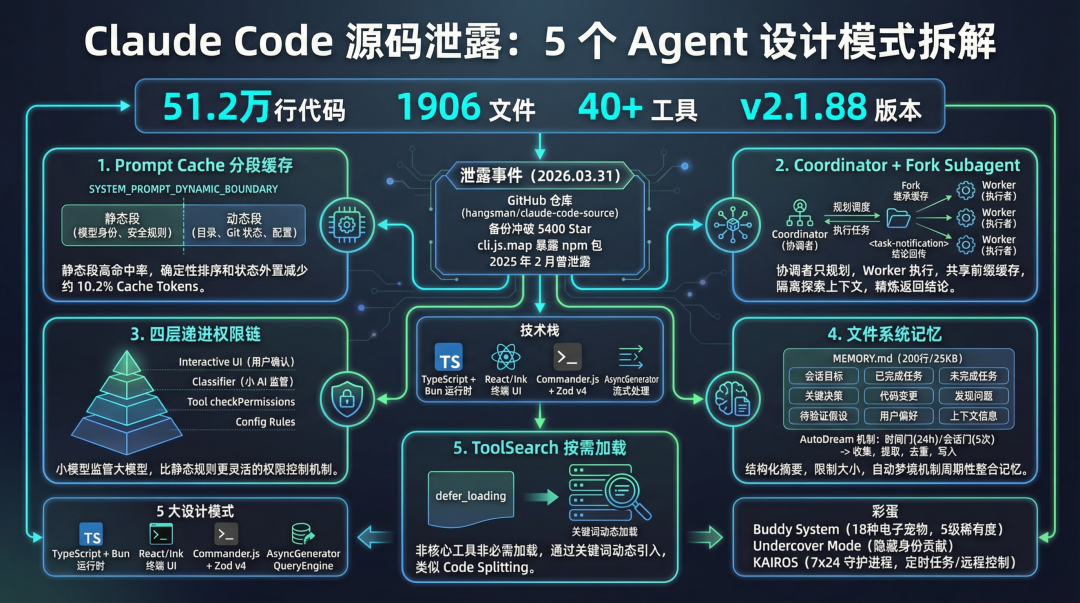
封面图 - Claude Code 源码泄露事件概览
图 1:Claude Code 源码泄露事件全景概览
2026 年 3 月 31 日,GitHub 上出现了一个仓库 hangsman/claude-code-source。几小时后,备份仓库 instructkr/claude-code 冲破 5400 Star、8800 Fork。Reddit 开发者原地狂欢,Hacker News 热帖炸裂。
Anthropic Claude Code 的完整源代码被开源了:不是故意的。
版本 v2.1.88,1906 个 TypeScript 源文件,51.2 万行代码,全通过一个 60MB 的 cli.js.map 暴露在 npm 包里。而且这不是第一次,2025 年 2 月就泄露过一次,同一个坑,同一份 Source Map。
但比起事件本身的戏剧性,这份代码里的架构设计更值得聊。翻完源码和相关技术分析后,我整理出了 5 个所有 AI Agent 开发者都能借鉴的设计模式。
1. 泄露始末:60MB 的 JSON 文件
Source Map 是 JavaScript 生态里的调试工具,作用是将压缩混淆后的代码映射回原始源码。正常发布 npm 包时,你得在 .npmignore 里排除它,或者在 package.json 的 files 字段里过滤它。
Anthropic 两件事都没做。
于是 @anthropic-ai/claude-code 这个 npm 包里,就躺着一个 59.8MB 的 cli.js.map。这本质上是个 JSON 文件,里面 sources 数组存文件路径,sourcesContent 数组存源码内容,一一对应。任何人 npm install 之后,就能还原出完整项目结构。
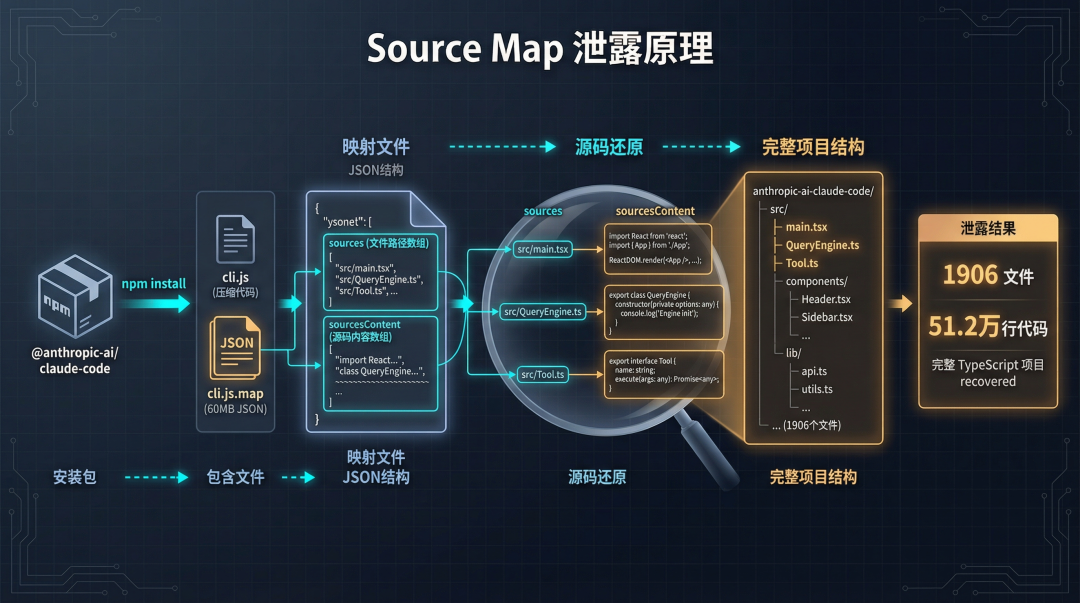
Source Map 泄露机制示意图
图 2:Source Map 文件泄露机制——npm 包中的 cli.js.map 如何暴露完整源码
2025 年第一次泄露后,Anthropic 的应对是从 NPM Registry 上下架所有旧版本。开发者 Dave Schumaker 在博客里记录了他的抢救过程:本地 npm cache 被清空,他正要认命关电脑,发现 Sublime Text 还开着那个文件,按了一下 ⌘+Z——撤销大法让 Source Map 回来了。
一年后,同样的 Source Map,同样的 npm 包,同样的泄露方式。
坦白讲,对于一家把 AI Safety 当核心招牌的公司来说,连续两次在同一个工程细节上翻车,确实有点说不过去。但这也侧面说明一个问题:他们把精力都花在了模型和架构上,打包发布这种小事反而没顾上。
2. 技术栈:用 React 画终端界面
先看整体技术选型。
组件 | 选型 | 说明 |
|---|---|---|
语言 | TypeScript | 全栈类型安全 |
运行时 | Bun | 比 Node 更快的启动和执行 |
终端 UI | React + Ink | 用 React 组件画终端 |
CLI 框架 | Commander.js | 成熟的命令行解析 |
Schema 校验 | Zod v4 | 运行时类型校验 |
用 React 画终端这个选择,初看有点意外。但 Ink 框架支持 Flexbox 布局、组件化开发、Hooks 状态管理——本质上就是把 Web 前端那套搬到了终端里。对于需要实时渲染流式输出、工具调用状态、进度条的复杂 CLI 来说,比手写 ncurses 高效得多。
入口文件 main.tsx 有 975 行,做了几件很工程化的事:在任何 import 语句之前,先用副作用触发 MDM 配置读取和 macOS 钥匙串预取;利用后续模块加载的约 135ms 窗口做并行预热,实测节省 65ms 启动时间。还内置了反调试保护和 Feature Flag 系统(KAIROS、PROACTIVE、TORCH 等未公开功能的开关)。
系统核心引擎 QueryEngine.ts(1295 行)用 AsyncGenerator 模式实现流式处理。submitMessage() 是一个 AsyncGenerator<SDKMessage>,每次 yield 一个消息片段,上层通过 for await...of 消费。这种设计让流式响应、工具调用、中断恢复都变得很自然。
整个代码库:30+ 服务模块(analytics、api、autoDream、compact、lsp、mcp、voice 等),40+ 内置工具,50+ 斜杠命令。这不是什么周末项目,是一个认真打磨的生产级系统。
3. Prompt Cache:字节级的精打细算
这是整份源码里技术含量相当高的部分,也是拉开 Claude Code 和普通套壳应用体验差距的核心所在。
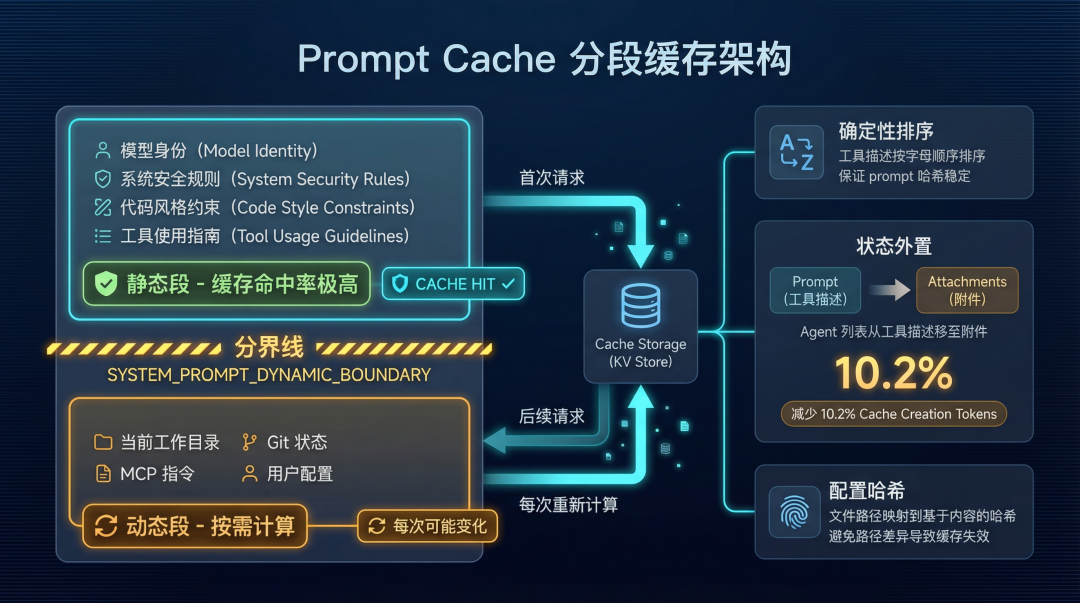
Prompt Cache 分段缓存架构图
图 3:Prompt Cache 分段缓存架构——静态段/动态段分离 + 三大优化策略
分段缓存
Anthropic 的 API 支持 Prompt Cache:如果两次请求的 prompt 前缀相同,后端可以复用缓存的 KV 状态,跳过重复计算。Claude Code 把这个能力发挥得相当充分。
提示词被分成两段:
- 静态段:模型身份(
You are Claude Code...)、系统安全规则、代码风格限制、工具使用基础指南。整个会话周期内几乎不变,缓存命中率极高。 - 动态段:当前工作目录、Git 状态、MCP 指令、用户配置。每次可能变化,不缓存或低命中率。
两段之间有一个硬编码标记:SYSTEM_PROMPT_DYNAMIC_BOUNDARY。静态段稳定缓存,动态段按需计算。System Prompt 还有一条优先级链:Override > Coordinator > Agent > Custom > Default,不同模式下注入不同层级的指令。
核心 API 调用逻辑在 services/api/claude.ts 里,一个 3419 行的文件。
确定性排序
一个容易被忽略的细节:传给模型的工具描述严格按照字母表排序(内置工具前缀 + MCP 工具后缀)。工具描述是 prompt 的一部分,顺序每次不同,整个 prompt 哈希就变了,缓存直接失效。
配置文件路径也使用基于内容的哈希值映射,避免每次注入的路径字符串不同导致缓存击穿。
状态外置
这个做法更巧妙。当前可用的 Agent 列表原本写在工具描述里,每次 Agent 列表变化,整个 prompt 缓存都得重建。源码里把这个列表剥离出来,转移到消息附件(Attachments)中。
仅此一项,减少了约 10.2% 的 Cache Creation Tokens 消耗。
10.2% 听起来不多,但放在 Anthropic 的成本结构里就不一样了:Claude Code 年化收入占 Anthropic 总收入的 18%(2026 年初数据),每天海量请求。10% 的缓存优化,省下的 token 费用是相当可观的数字。
说到底,现阶段做得好的 AI 应用层开发,本质上就是在精细地压榨 API 缓存系统的每一分价值。
你在做 AI Agent 开发时做过类似的 prompt cache 优化吗?欢迎在评论区聊聊。
4. 工具系统:40+ 工具与四层权限
Claude Code 内置了超过 40 种工具,覆盖文件操作、Bash 执行、搜索、Git、MCP 协议等,还有 50+ 斜杠命令(/commit、/review、/compact、/memory、/buddy、/doctor 等)。
Tool 抽象层
Tool.ts(792 行)定义了完整的工具接口,包含 20+ 个方法:
// Tool 类型核心定义(简化)
type Tool = {
name: string; // 工具名称
call: (input) => Promise<ToolResult>; // 执行函数
inputSchema: ZodSchema; // 输入参数校验
checkPermissions: () => PermissionCheck; // 权限检查
isReadOnly: boolean; // 是否只读
isConcurrencySafe: boolean; // 是否可并发执行
maxResultSizeChars: number; // 结果大小上限
// ...还有十几个生命周期方法
};
buildTool 工厂函数负责组装具体实例,统一生命周期管理。还有一个 StreamingToolExecutor,协调器会将工具调用请求分区为并发批次和串行批次,isConcurrencySafe() 决定一个工具能否并行跑。
ToolSearch 按需加载
40+ 工具的描述全塞进 prompt,token 消耗会很夸张。解法是 ToolSearch:非核心工具标记 defer_loading: true,模型看不到具体定义,只知道有 ToolSearch 可用。需要时传入关键词,动态加载对应工具定义放入后续 prompt。
还有一个简化模式 CLAUDE_CODE_SIMPLE,只保留 3 个基础工具。assembleToolPool() 函数负责合并内置工具 + MCP 工具,并按 prompt cache 友好的顺序排列。
这跟 Web 开发里的 Code Splitting 是一个思路——按需加载,控制首次 prompt 体积。
四层递进权限
工具执行权限不是简单的是/否,而是四层递进:
层级 | 检查内容 | 示例 |
|---|---|---|
Config Rules | 用户自定义规则 | .claude/settings.json 中的 allow/deny |
Tool checkPermissions | 工具自身逻辑 | BashTool 检查命令是否在白名单 |
Classifier | 侧查询小模型 | 小 LLM 判断 Bash 命令安全性 |
Interactive UI | 用户手动确认 | 弹出 Allow/Deny 提示 |
Classifier 这层特别有意思。用户开启 Auto Mode 后,系统在后台静默调用一个更小、更便宜的 LLM,把当前对话精简转录和即将执行的 Bash 命令抛给它,让侧边模型输出 Allow 或 Deny。配合 Denial Tracking,自动工具被频繁拒绝时会优雅降级。
用小 AI 监管大 AI——比静态规则拦截灵活得多。
5. Coordinator 模式:上下文污染的解药
长对话中,AI Agent 的上下文会被各种探索性操作污染。探索方案 A 产生的大量中间输出会挤占上下文窗口,影响后续判断。这是所有长任务 Agent 的共同痛点。
Claude Code 的解法是 Coordinator + Fork Subagent。
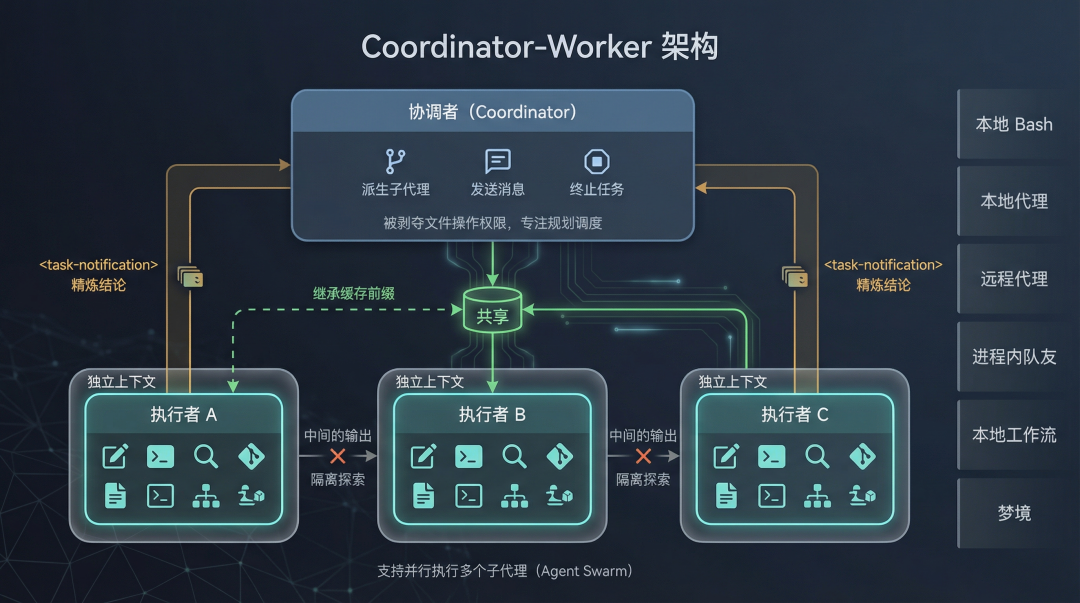
Coordinator-Worker 架构图
图 4:Coordinator-Worker 两层架构——缓存继承、隔离探索、结论回传三大机制
架构设计
开启 Coordinator 模式后,系统变成两层:
- Coordinator(协调者):被剥夺了直接操作文件的权限,只保留
Agent(派生子代理)、SendMessage和TaskStop三个工具。它的活儿就是规划和调度。 - Worker(执行者):携带具体工具描述被派生出来,执行实际任务。
三个关键机制
Fork 继承缓存:子 Agent 继承父对话的 Prompt Cache,不是复制新上下文,而是共享缓存前缀。创建子 Agent 的额外 token 成本很低。
隔离探索:子 Agent 在独立上下文窗口运行。探索方案 A 产生的所有中间输出、工具调用、错误信息,都限制在子 Agent 上下文里,不会污染主对话。
结论回传:子 Agent 完成后不是把整个对话历史丢回来,而是通过 XML 格式 <task-notification> 将提炼后的关键结论传回 Coordinator。
用完即毁,只留结论——这大概是处理多 Agent 长文本协同的好办法之一。
Agent Swarm 与任务类型
系统支持 6 种任务类型:local_bash、local_agent、remote_agent、in_process_teammate、local_workflow、dream。其中 in_process_teammate 允许主进程平行唤醒多个 Agent 同时执行不同任务。
源码里还集成了 iTerm2 和 Terminal.app 的 AppleScript 控制指令,派生新 Teammate 时自动在终端中切分窗格。所有 Teammate 子进程将权限请求通过内部通道(permissionSync.ts)桥接给主进程的 Leader Agent 处理。
从单体思考到集群并发协作——这可能就是 AI Agent 演进的方向。
6. 记忆系统:从流水账到结构化知识
AI 的记忆问题,说到底就是记住什么和怎么记住。
Compact/Summary:9 段式摘要
长对话超过上下文窗口限制时,Claude Code 触发 Compact 操作,把之前的对话压缩成一段结构化摘要。这段摘要遵循严格的 9 段式结构:
- 会话目标
- 已完成的任务
- 未完成的任务
- 关键决策和理由
- 代码变更摘要
- 发现的问题
- 待验证的假设
- 用户偏好
- 上下文关键信息
每一段都有明确格式要求。这样压缩后的摘要不仅节省 token,还能让模型快速恢复上下文状态。
文件系统即记忆库
记忆系统完全基于本地文件系统,没有用向量数据库。核心是 MEMORY.md 文件,限制在 200 行 / 25KB 以内。记忆划分为 User、Feedback、Project、Reference 四大类,以 Frontmatter 格式存储。
AutoDream 整合
源码里有一个 AutoDream 机制,设计得相当精巧:
- 时间门:距上次整合超过 24 小时才触发
- 会话门:累计 5 次会话后触发
- 文件锁:防止多进程同时修改记忆文件
整合流程分 4 阶段:收集原始日志 → 提取关键信息 → 去重合并 → 写入结构化文件。
这种基于文件系统 + 结构化摘要的方案,在工程复杂度和效果之间找到了不错的平衡。不用搭向量数据库,不用搞 embedding,纯靠 Markdown 文件和 LLM 的总结能力就能实现基本的长期记忆。
另外还有一个 Speculation(投机执行)机制:用户输入时系统预生成响应,如果用户确实发送了该内容,直接返回已生成的结果,减少等待时间。这跟 CPU 的分支预测是同一类优化思路。
7. 彩蛋:电子宠物、卧底模式与 KAIROS
翻源码的额外乐趣,是发现工程师藏在代码里的彩蛋。
Buddy System:18 种电子宠物
源码中有一个完整的电子宠物系统。18 种物种(duck、goose、blob、cat、dragon、octopus、owl、penguin、turtle、snail、ghost、axolotl、capybara、cactus、robot、rabbit、mushroom、chonk),5 级稀有度:
稀有度 | 权重 | 概率约 |
|---|---|---|
Common | 60 | 60% |
Uncommon | 25 | 25% |
Rare | 10 | 10% |
Epic | 4 | 4% |
Legendary | 1 | 1% |
每个宠物有 5 维属性(DEBUGGING、PATIENCE、CHAOS、WISDOM、SNARK),6 种眼睛(·、✦、×、◉、@、°),8 种帽子(crown、tophat、propeller、halo、wizard、beanie、tinyduck + none),1% 概率出现闪光变体。宠物用 Mulberry32 PRNG 基于用户 ID 确定性生成——你的宠物是固定的。ASCII 精灵 5 行 12 列,3 帧动画。
有个有趣的细节:其中一个物种名恰好与 Anthropic 内部模型代号重名(疑似 Claude Mythos 代号卡皮巴拉),工程师用 String.fromCharCode() 动态拼装这个单词,绕过合规代码扫描。
Undercover Mode
Anthropic 员工在开源或公共仓库贡献代码时,系统默认开启卧底模式:Prompt 中要求模型不要暴露身份,强制剥离所有 AI 生成的免责声明和代号痕迹。而且没有强制关闭开关。这说明 Anthropic 对模型输出的角色控制和内容干预能力相当强。
KAIROS:尚未发布的守护进程
源码注释里写着 KAIROS (assistant mode),配置描述是 Start Claude in assistant mode (custom system prompt, brief view, scheduled check-in skills)。
- 7×24 小时在线守护进程
- 支持 cron 定时任务、webhook 触发、远程控制
- 可通过社交软件指挥(连接 MCP channel notifications)
- 有
KAIROS_GITHUB_WEBHOOKS开关,能订阅 GitHub 等外部信号 - 后台 Dream 机制对白天日志做总结和蒸馏
如果 KAIROS 正式发布,Claude Code 就不只是一个编程助手了。源码里还有个内部代号 Capybara(水豚),指向 Opus 之上的新一代模型——这跟 2026 年 3 月 26 日 Anthropic 因 CMS 配置错误泄露的 Claude Mythos 模型信息吻合。
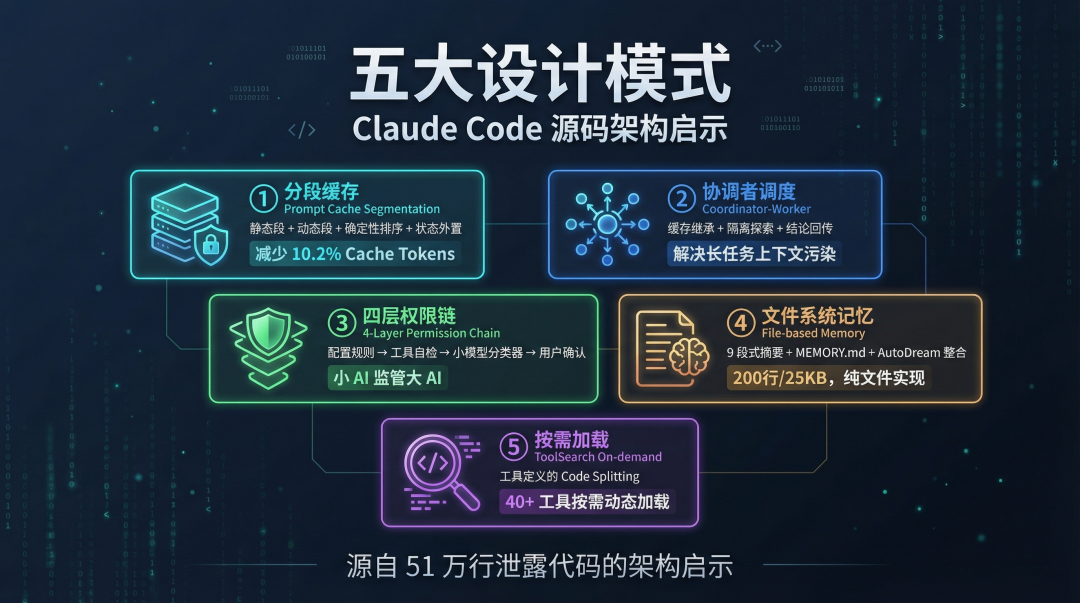
五大设计模式总结图
图 5:Claude Code 泄露源码中的 5 个核心 Agent 设计模式总结
总结
51 万行代码,1906 个文件,从 Source Map 泄露到全世界。对 Anthropic 是严重的工程事故,对 AI Agent 开发社区则是一份免费的前沿架构教材。
从这份源码里,5 个值得记住的设计模式:
- Prompt Cache 分段缓存:静态/动态分段 + 确定性排序 + 状态外置,把 API 缓存压榨到底
- Coordinator + Fork Subagent:缓存继承 + 隔离探索 + 结论回传,解决长任务上下文污染
- 四层递进权限链:配置规则 → 工具自检 → 小模型分类器 → 用户确认,兼顾安全和效率
- 文件系统记忆:9 段式结构化摘要 + AutoDream 整合,简单但有效
- ToolSearch 按需加载:工具定义的 Code Splitting,控制 prompt 体积
这些设计的背后,是 Anthropic 在成本控制、上下文管理、多 Agent 协作上的工程实践。对 Cursor、Windsurf、GitHub Copilot 等竞品来说,参考价值不言而喻。
但代码可以抄,模型能力抄不了。Claude Code 的体验优势很大程度上来自 Claude 模型本身的理解力和推理能力。工程架构是骨架,模型才是灵魂。
你觉得这 5 个设计模式里,哪个对你的项目有启发?评论区聊聊。
相关资源
泄露仓库:https://github.com/instructkr/claude-code
Dave Schumaker 2025 年泄露记录:https://daveschumaker.net/digging-into-the-claude-code-source-saved-by-sublime-text/
Hacker News 2026 年讨论:https://news.ycombinator.com/item?id=47584540
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号