AI论文速读 | MobilityBench:用于评估真实出行场景中路线规划智能体的基准测试

AI论文速读 | MobilityBench:用于评估真实出行场景中路线规划智能体的基准测试

时空探索之旅
发布于 2026-04-02 12:28:07
发布于 2026-04-02 12:28:07
论文标题:MobilityBench: A Benchmark for Evaluating Route-Planning Agents in Real-World Mobility Scenarios
作者: Zhiheng Song, Jingshuai Zhang, Chuan Qin, Chao Wang, Chao Chen, Longfei Xu, Kaikui Liu, Xiangxiang Chu(初祥祥), Hengshu Zhu(祝恒书)
机构:高德地图,中科院计算机网络信息中心
论文链接:https://arxiv.org/abs/2602.22638
Code:https://github.com/AMAP-ML/MobilityBench
TL;DR:高德联合中科院提出MobilityBench,针对LLM路线规划智能体缺乏系统真实评估的问题,基于高德真实匿名查询构建基准,设计确定性 API 重放沙箱保障可复现,提出多维度评估协议,评估发现模型难处理偏好约束规划,且已开源相关资源
关键词:智能体、路线规划、Benchmark、API重放沙盒

摘要
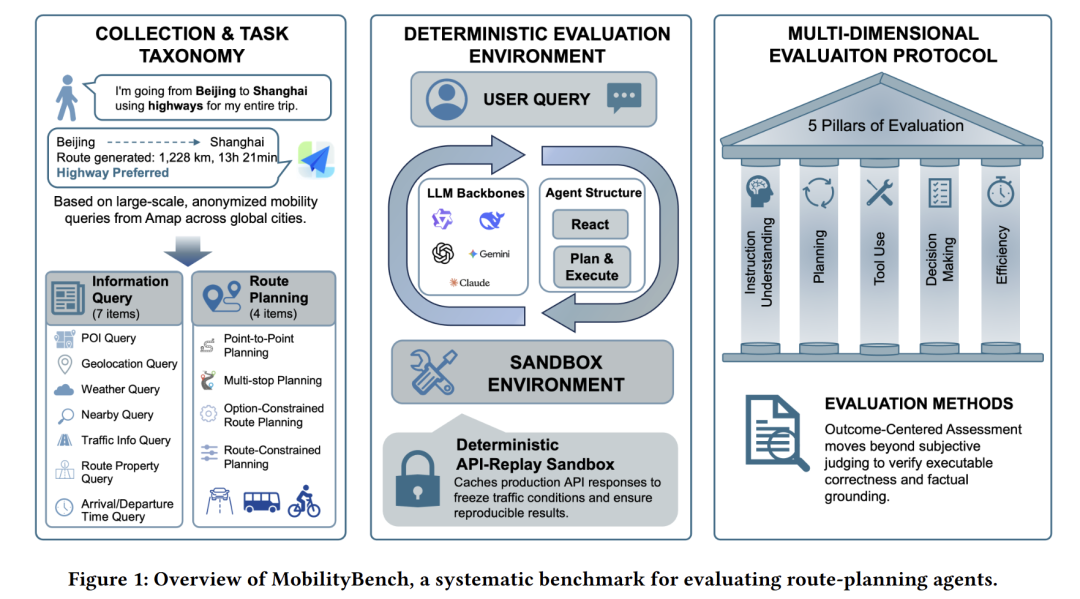
基于大语言模型(LLMs)的路线规划智能体已成为一种极具前景的范式,能够通过自然语言交互与工具辅助决策,为人们的日常出行提供支持。然而,多样化的路线规划需求、非确定性地图服务以及有限的复现性,阻碍了在真实出行场景下开展系统性评估。本研究提出MobilityBench,这是一个可扩展的基准测试平台,用于评估真实出行场景中基于大语言模型的路线规划智能体。 MobilityBench基于从高德地图采集的大规模匿名真实用户查询构建,覆盖全球多个城市的各类路线规划意图。为实现可复现的端到端评估,设计了确定性的API回放沙箱,消除实时服务带来的环境差异。进一步提出以结果有效性为核心的多维度评估方案,同时评估指令理解、规划能力、工具使用与执行效率。 借助MobilityBench,在多样的真实出行场景中对多款基于大语言模型的路线规划智能体展开评估,并深入分析其行为与性能表现。研究结果表明,现有模型在基础信息检索与路线规划任务中表现良好,但在偏好约束型路线规划任务中仍存在显著困难,这说明个性化出行应用领域仍有较大提升空间。已公开发布该基准数据集、评估工具包。
Q: 这篇论文试图解决什么问题?
A:这篇论文试图解决在真实世界移动场景中系统评估基于大语言模型(LLM)的路线规划智能体(route-planning agents)所面临的核心挑战。具体而言,论文针对以下四个关键问题提出了系统性解决方案:
1. 多样化且复杂的移动需求覆盖不足
现有基准(如TravelBench、TravelPlanner)主要关注高层级的多日程规划或抽象约束推理,无法捕捉日常移动场景中细粒度的路线规划复杂性。真实世界的移动请求远超简单的点对点导航,常涉及交织的多重约束(如避高速、最少换乘、有序途经点、时间敏感要求等),需要智能体在大型地图环境中进行精确的空间推理和工具协调。
2. 实时地图服务的非确定性(Non-determinism)
传统评估依赖实时API(如交通状况、天气服务),其响应随时间动态变化(交通流、服务可用性、后端更新),导致:
- 不可复现性:相同查询在不同时间产生不同结果,无法公平比较不同模型
- 环境噪声:评估结果反映的是外部系统波动而非智能体本身的推理能力
3. 缺乏全面可靠的评估维度
现有评估多依赖端到端成功率或LLM主观判断,将智能体行为视为"黑箱",无法诊断决策链中的中间失败。有效评估需要整合多维度客观标准,验证API调用有效性、约束满足度、事实依据和工具使用正确性。
4. 评估基础设施的可扩展性与可复现性
随着LLM骨干模型和智能体框架的快速演进,需要一个轻量级、模块化的工具包,支持:
- 跨不同模型和框架的一致评估
- 轻松部署和持续数据扩展(新地区、新场景、新意图类型)
核心解决方案:MobilityBench
为应对上述挑战,论文提出了MobilityBench基准,其核心创新包括:
- 基于真实用户查询的数据构建:从Amap(高德地图)收集的大规模匿名真实语音查询,覆盖350+城市、11种任务场景(从基础信息检索到偏好约束路线规划)
- 确定性API重放沙盒(Deterministic API-replay Sandbox):通过缓存和重放API响应冻结交通状况,确保所有智能体在完全相同的"静态"环境中评估,消除环境方差
- 多维评估协议
:将智能体行为分解为四个核心能力维度进行细粒度诊断:
- 指令理解(意图检测、信息抽取)
- 规划(任务分解)
- 工具使用(工具选择、模式合规、参数填充)
- 决策质量(交付率、最终通过率)
- 效率(输入/输出token成本)
通过这些设计,论文旨在建立一个鲁棒、可扩展、可复现的评估基础,推动真实世界移动场景下路线规划智能体的研究。
Q: 有哪些相关研究?
A: 该论文的相关研究主要围绕城市计算中的路线规划与工具增强型智能体基准测试两个维度展开,具体梳理如下:
1. 城市计算中的路线规划(Route Planning in Urban Computing)
早期算法基础
- 经典最短路线算法:早期研究主要在图论框架下优化物理成本(如距离或行驶时间),广泛采用Dijkstra算法与A*算法及其变种,在保证最优性的同时提升大规模道路网络中的计算可扩展性。
- 局限性:此类方法通常假设同质化的优化目标和明确定义的成本函数,难以适应多样化的用户偏好。
偏好感知与推荐融合
- 个性化路线规划:后续研究转向多目标优化,整合用户兴趣与上下文因素(如INTSR等推荐模型),通过结构化特征或预定义偏好空间实现路由与推荐的结合。
- 局限性:依赖结构化输入,难以处理自然语言表达的模糊、长尾或弱规范需求。
大语言模型时代的路线规划
- LLM直接推理:近期研究探索利用LLM理解复杂语义指令,但已有研究表明,纯LLM在地理空间推理和约束优化方面可靠性不足。
- 混合架构
:为弥补上述缺陷,研究者提出耦合LLM与传统规划器的混合框架:
- LLM用于高层决策指导或意图/约束提取
- 传统算法负责底层路线计算
- 高级优化策略:包括分层规划架构(Hierarchical Planning)和基于强化学习的优化方法,以提升多目标多约束下的鲁棒性。
工具增强型智能体
- 范式转变:工具增强型语言智能体展现出与真实世界系统交互、协调外部工具进行结构化决策的强大能力,成为真实移动场景下路线规划的有前景范式。
- 现有缺陷:当前旅行规划智能体主要聚焦高层级行程生成与抽象约束推理,缺乏语义意图理解与真实道路网络细粒度路线优化的紧密集成,无法捕捉日常人类移动的复杂性。
2. 工具增强型智能体基准测试(Tool-augmented Agent Benchmark)
通用工具使用评估
- ToolBench:构建覆盖16,000+真实API的大规模基准,要求智能体执行序列搜索与规划以完成复杂指令。
- τ-bench:强调交互式评估,通过模拟用户-智能体交互,衡量跨多次试验的行为一致性。
城市计算领域的专用基准
- TravelPlanner:针对多日行程构建的基准,集成航班、餐厅搜索等域特定工具,评估智能体在行程级别环境约束、常识约束和硬约束下的表现。
- TravelBench:将任务扩展至多轮对话场景,评估智能体推断和细化用户隐含偏好的能力。
现有基准的局限性 上述基准主要关注高层级行程生成与抽象约束满足,未系统评估智能体在移动特定约束下的细粒度路线规划能力,例如:
- 偏好感知路由(如避高速、最少换乘)
- 有序途经点约束
- 模态依赖条件(多交通方式整合)
- 时间敏感约束
与本文工作的关系
相较于现有研究,MobilityBench填补了以下空白:
- 针对真实世界日常移动场景中细粒度、多约束的路线规划需求,提供基于大规模真实用户查询的评估数据
- 通过确定性API重放沙盒解决实时地图服务的非确定性问题,确保评估的可复现性
- 建立覆盖指令理解、规划、工具使用、决策质量与效率的多维评估协议,超越端到端成功率的粗粒度评估
Q: 论文如何解决这个问题?
A: 论文针对大语言模型路线规划智能体的评估难题,从数据构建、环境控制、真值标注、评估体系、开源基建五个核心层面构建 MobilityBench 基准测试体系,形成系统性解决方案,具体如下:
1. 基于真实世界数据的可扩展场景覆盖
大规模匿名化真实查询采集
- 从 Amap(高德地图)过去六个月的大规模匿名化真实用户语音查询中构建数据集,这些查询直接反映了真实移动场景中的意图表达,涵盖目的地目标、情境信息需求和显式偏好约束。
- 经过严格过滤(去除 malformed、underspecified 或 ambiguous 请求)和去重后,形成包含 100,000 个episode 的基准集,覆盖 22 个国家、350 余个城市。
分层任务分类体系(Task Taxonomy) 通过开放集标注协议(open-set labeling)和专家裁决迭代,构建四层意图家族(Intent Family):
- Basic Information Retrieval(基础信息检索):POI 查询、地理定位、周边搜索、天气查询、交通信息查询
- Route-Dependent Information Retrieval(路线依赖信息检索):路线属性查询、到达/出发时间查询
- Basic Route Planning(基础路线规划):点对点规划、多经停点规划
- Preference-Constrained Route Planning(偏好约束路线规划):选项约束规划(避高速、少换乘等)、路线约束规划(指定途经点/避开特定道路)
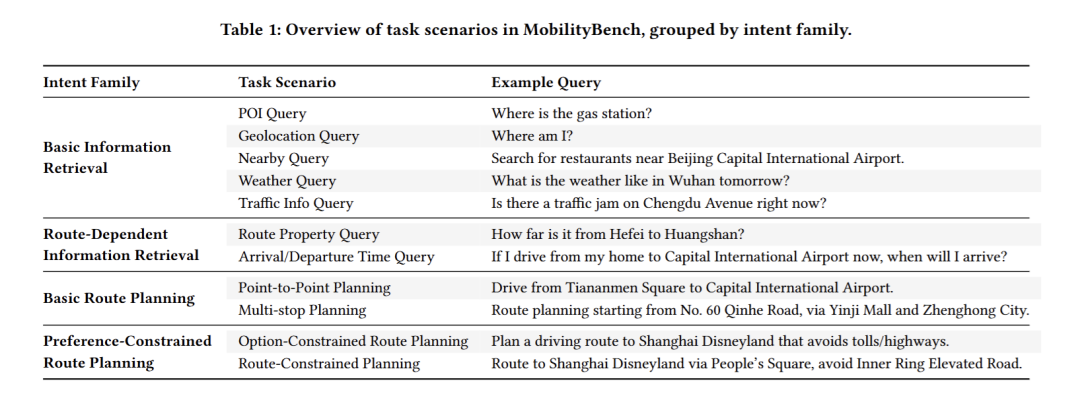
MobilityBench 中的任务场景概述,按意图类别分组
MobilityBench 中的任务场景概述,按意图类别分组
2. 确定性 API-Replay 沙盒(Deterministic Sandbox)
冻结环境状态以消除非确定性
- 在真值构建阶段,通过标准化接口捕获并缓存路由 API 和兴趣点 API 的响应,有效"冻结"了采集时刻的交通状况和服务状态。
- 评估阶段,智能体被禁止访问实时 API,所有工具调用被拦截并重定向到缓存响应存储(cached response store)。
- 通过规范化参数(如标准化坐标、标准时间格式)作为缓存键,确保相同输入始终产生相同输出,实现可复现的端到端评估。
容错与验证机制
- 当精确缓存未命中时,沙盒应用任务相关的回退策略(fuzzy matching for entity-based queries, nearest-neighbor spatial matching for coordinate-based queries),并设置最大距离阈值。
- 所有工具调用均经过严格的模式验证(schema validation),包括必填字段检查、类型和范围约束,未通过验证的调用被显式标记为工具使用失败。
3. 结构化真值构建(Ground-Truth Construction)
先搭建以评估单元为核心的结构化真值体系,将单个episode形式化为四元组,其中为匿名自然语言查询,为用户位置、城市等上下文信息,为沙盒可重放API响应快照,为仅用于评估的结构化真值标注。
4. 多维评估协议(Multi-dimensional Evaluation Protocol)
依托专家制定的场景化标准操作流程(SOP),通过槽位提取规范化、地理编码、工具调用验证三步生成标准工具执行轨迹,敲定权威真值参考。 突破单一成功率评估局限,拆解四大核心能力维度并配套量化公式:
指令理解(Instruction Understanding):
意图检测(ID):衡量智能体正确识别任务场景类别的能力
信息抽取(IE):评估从查询中提取显式和隐式约束(空间属性、时间参数、偏好信号)的准确性
规划(Planning)
任务分解(DEC):评估将高层目标分解为连贯原子动作序列的能力,使用精确率和召回率衡量步骤覆盖率和正确性
精确率:
召回率:
工具使用(Tool Use)
工具选择(TS):评估正确识别所需工具的能力,从覆盖度(Coverage)和冗余度(Redundancy)两个互补角度衡量:
工具选择精确率:
冗余度修正召回率:
模式合规(SC):评估工具调用是否符合预定义 API 规范(必填参数、有效格式和范围):
决策质量(Decision Making):交付率DR、最终通过率FPR,搭配输入Token(IT)、输出Token(OT)衡量推理资源消耗,实现全流程精细化能力诊断。
5. 开源评估工具包
论文公开释放了基准数据、评估工具包和文档( https://github.com/AMAP-ML/MobilityBench ),支持:
- 轻量级部署:模块化设计便于快速部署和集成新智能体框架
- 可扩展性:易于扩展到新地区、新场景和新意图类型
- 一致比较:提供标准化评估接口,确保跨模型和跨设置比较的公平性
Q: 论文做了哪些实验?
A: 论文在正文第4节Experiments部分,围绕大语言模型路线规划智能体的实际能力,开展了三大维度的系统性对照实验,所有实验基于基准数据集分层抽样后的子集完成,统一控制实验变量保障结果可比,核心实验设计与对应结论均通过图表量化呈现,具体内容如下:
1. 基础实验设置
数据采样 采用分层随机采样策略,在11个核心任务场景与城市维度上进行联合分层,确保场景分布均衡且地理覆盖无偏,最终形成7,098个评估episode。
LLM骨干模型 评估覆盖三类模型架构:
- 密集模型(Dense):Qwen3-4B、Qwen3-32B、GPT-4.1、GPT-5.2、Claude-Opus-4.5、Claude-Sonnet-4.5、Gemini-3-Pro-Preview、Gemini-3-Flash-Preview
- 混合专家模型(MoE):Qwen3-30B-A3B(激活3B参数)、Qwen3-235B-A22B(激活22B参数)、DeepSeek-V3.2-Exp
- 推理专用模型(Reasoning):DeepSeek-R1,以及各Qwen模型在Thinking模式下的变体
智能体框架 基于两种代表性范式构建路线规划智能体:
- ReAct:采用"思考-行动-观察"闭环推理,支持动态策略调整
- Plan-and-Execute:静态预规划后执行,适合结构化任务
统一配置 所有实验设置温度参数 =0.1,最大输出长度限制为8,192 tokens,最大推理步数限制为10步,以确保可比性。
2. 整体性能评估(Overall Performance)
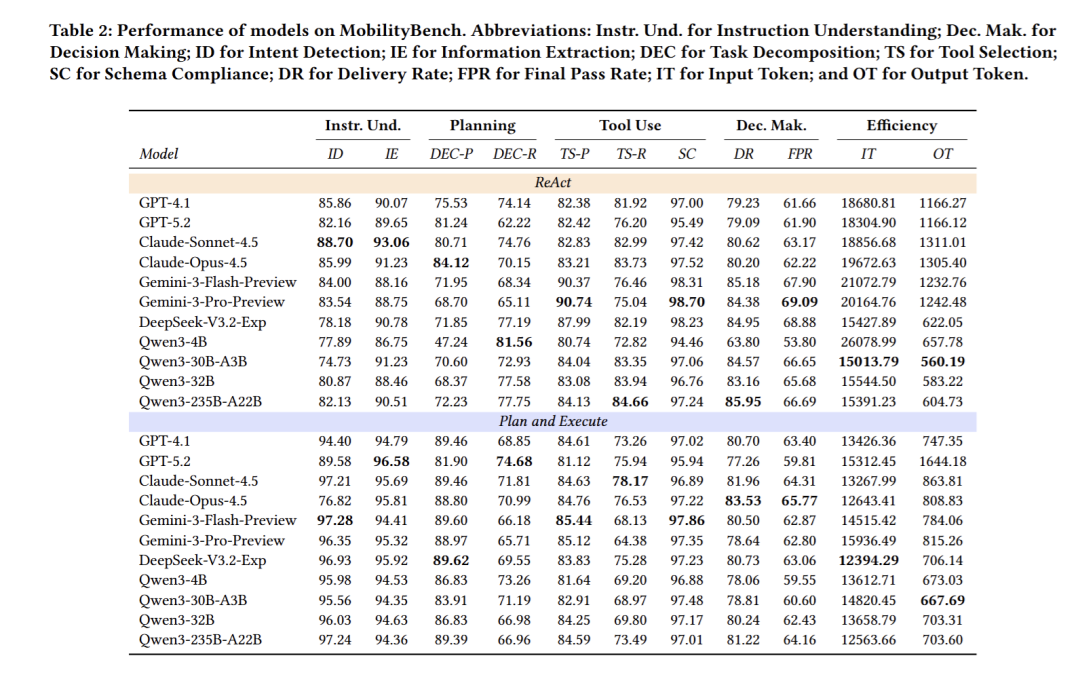
核心测试不同开源、闭源模型在两种智能体框架下的综合任务完成能力,对比闭源与开源模型的性能差距,分析两类推理框架的优劣势与核心权衡关系。该部分实验结果对应论文表2,直观呈现各模型与框架的核心能力得分差异。
3. 场景研究(Scenario Study)
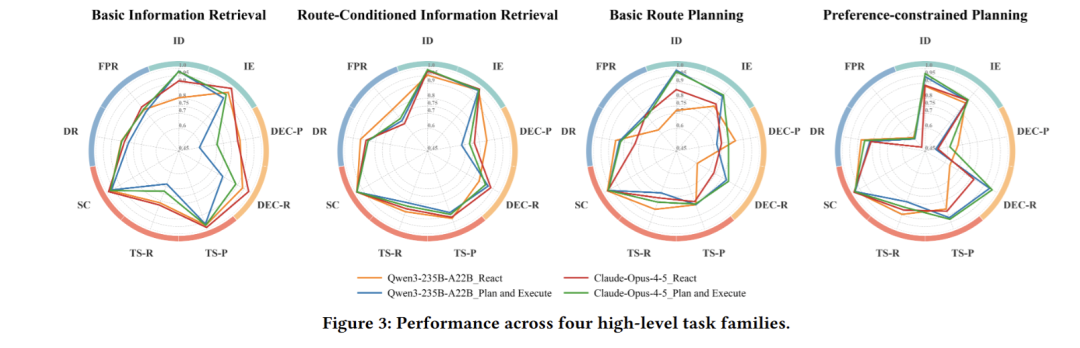
针对四大核心任务场景做细粒度拆解测试,分析不同任务难度梯度下模型的表现差异,探究两类智能体框架对不同场景的适配性,重点聚焦高复杂度约束类规划任务的模型短板。该部分实验结果对应论文图3的多维度雷达图,清晰展示各场景下的模型能力分布。
4. 模型特性研究(Model Study)
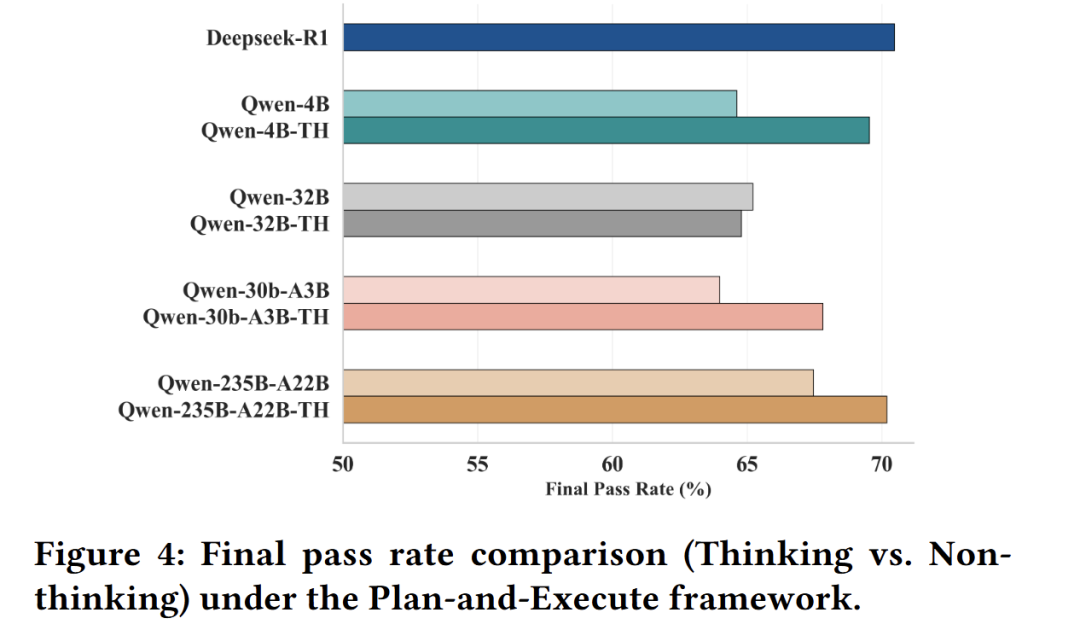
模型内在特性深度研究 开展两项专项分析,一是探究模型参数规模与性能的缩放效应,验证模型扩容对路线规划任务的增益逻辑(表2);二是对比模型开启专项推理模式与常规模式的性能差异,分析性能提升与资源消耗的关联。同时统计不同框架下的模型推理效率开销。
整体实验围绕基准测试、场景适配、模型特性三大核心,完整验证了MobilityBench的评估价值,同时明确了现有路线规划智能体的能力边界与优化方向。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号