TensorRT10.8 C++部署YOLO11全系模型

TensorRT10.8 C++部署YOLO11全系模型

OpenCV学堂
发布于 2026-04-02 19:47:14
发布于 2026-04-02 19:47:14
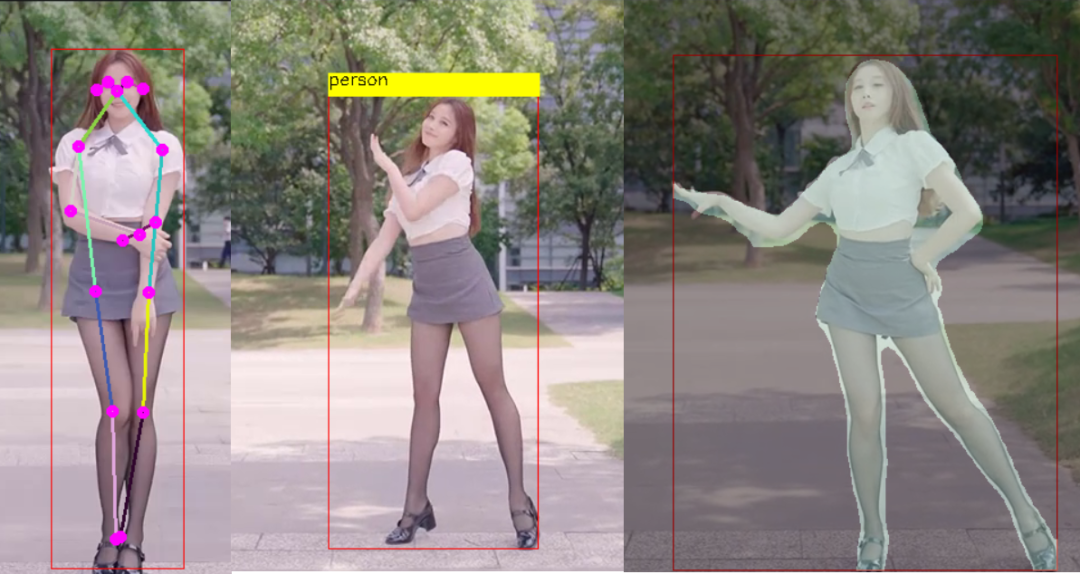
下载YOLO11对象检测预训练模型,直接从下面链接下载即可:
https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n.pt下载YOLO11实例分割预训练模型,直接从下面链接下载即可:
https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n-seg.pt下载YOLO11实例分割预训练模型,直接从下面链接下载即可:
https://github.com/ultralytics/assets/releases/download/v8.3.0/yolo11n-pose.pt先通过下面的命令行转为ONNX格式模型
yolo export model=yolo11.pt format=onnx然后再通过TensorRT的命令行转换为engine文件:
trtexec.exe --onnx=yolo11n.onnx --saveEngine=yolo11n.engine通过Netron可以查看YOLO11模型的输入与输出格式,截图如是:
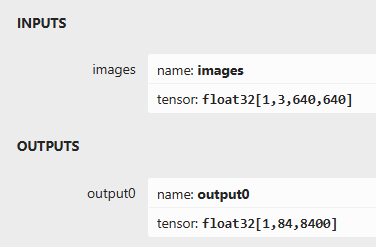
可见跟YOLOv8系列模型的输入与输出格式保持一致,没有改动!
TensorRT推理
直接使用我们之前的YOLOv8对象检测代码测试,加载YOLO11n对象检测模型,推理运行如下:
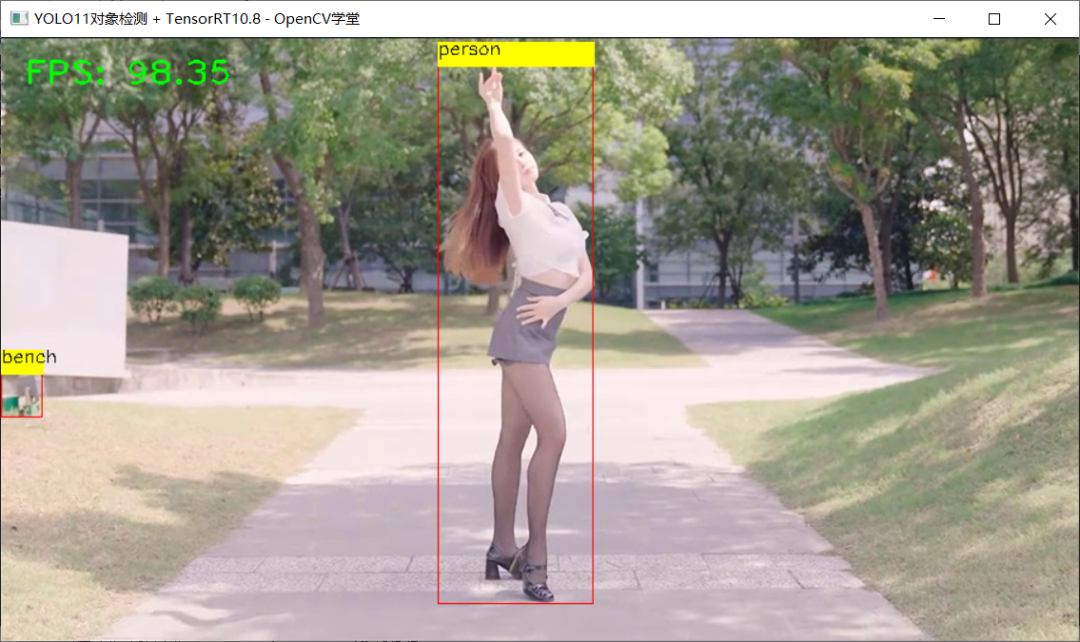
图片
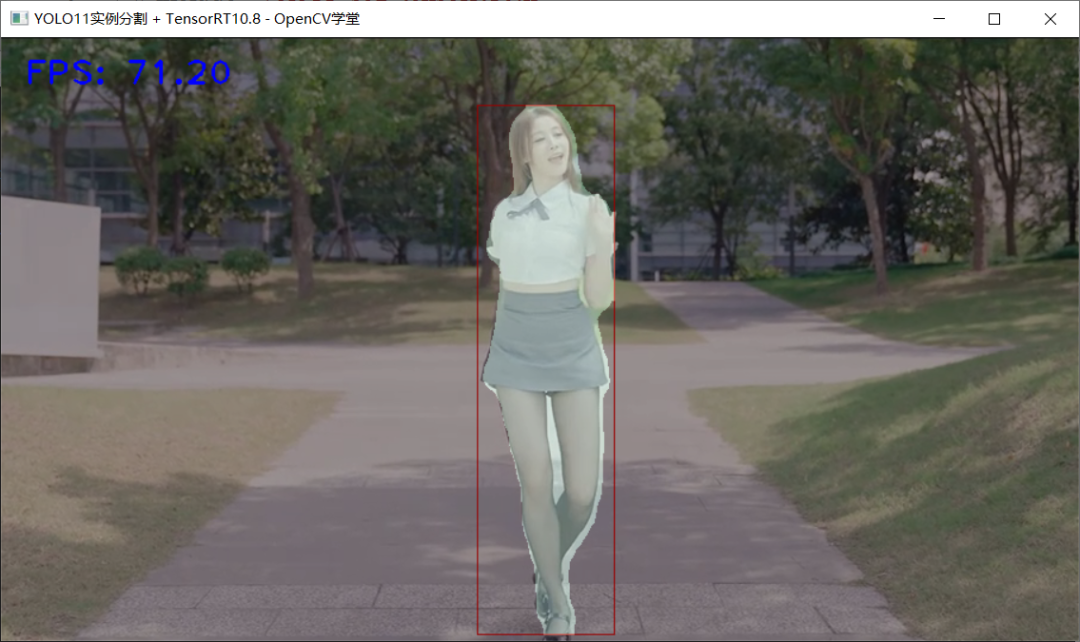
加载YOLO11n实例分割模型,推理运行如下:
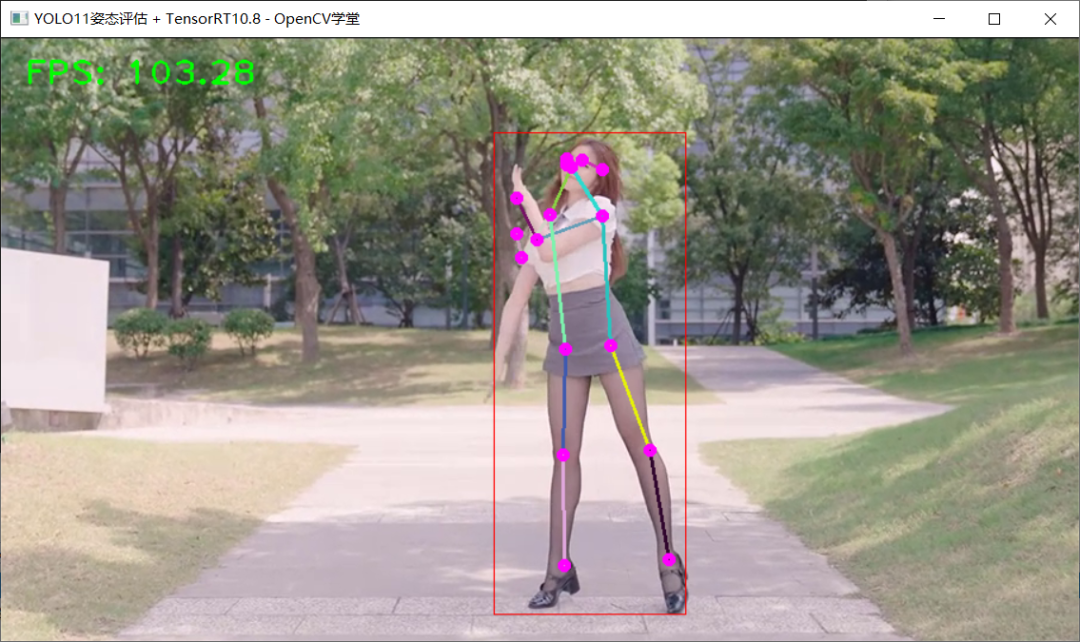
加载YOLO11n姿态评估模型,推理运行如下:
测试代码如下(已经封装为一个C++的类,只需三行代码即可调用,支持YOLOv8~YOLO13对象检测模型部署推理):
std::shared_ptr<YOLOv81112TRTDetector> detector(new YOLOv81112TRTDetector());
detector->initConfig("D:/python/yolov5-7.0/yolo11n.engine", 0.4, 0.25f);
cv::VideoCapture capture("D:/images/video/dance.mp4");
cv::Mat frame;
std::vector<DetectResult> results;
while (true) {
bool ret = capture.read(frame);
if (frame.empty()) {
break;
}
detector->detect(frame, results);
for (DetectResult dr : results) {
cv::Rect box = dr.box;
cv::putText(frame, classNames[dr.classId], cv::Point(box.tl().x, box.tl().y - 10), cv::FONT_HERSHEY_SIMPLEX, .5, cv::Scalar(0, 0, 0));
}
cv::imshow("YOLO11对象检测 + TensorRT10.8 - OpenCV学堂", frame);
char c = cv::waitKey(1);
if (c == 27) { // ESC 退出
break;
}
// reset for next frame
results.clear();
}本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号