DINOv3视觉基础大模型正式发布!

DINOv3视觉基础大模型正式发布!

OpenCV学堂
发布于 2026-04-02 20:21:45
发布于 2026-04-02 20:21:45
Meta 宣布发布 DINOv3,这是一个前沿的自监督视觉基础模型,在广泛的计算机视觉任务中实现了前所未有的性能。该模型通过放弃依赖于内存密集型带标签数据集的策略,提高了多样性和准确性,在新颖的高度上推动了特征提取能力。
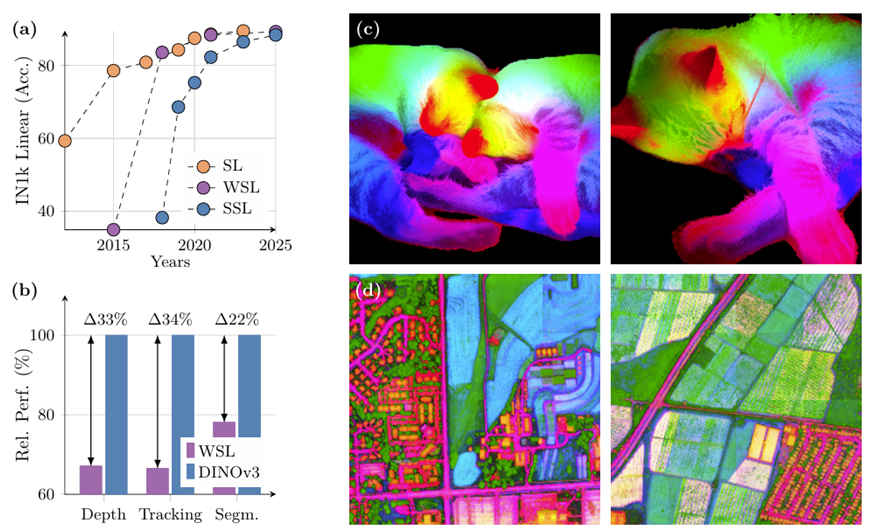
随着 DINOv3 的发布,我们在密集任务上显著超过了弱监督模型,通过最佳类别的 WSL 模型的相对性能来展示(b)。我们还使用在自然图像(c)和航拍图像(d)上训练的 DINOv3 生成了特征的 PCA 图。
DINOv3 通过采用全面的模型套件来扩展自监督学习的应用范围,以满足不同的用例需求。这包括一系列不同大小的 Vision Transformer (ViT) 和为在资源受限环境中部署而优化的高效 ConvNeXt 架构。

该模型在大规模数据集上进行训练,共使用了 17 亿张图片,与前身相比,模型大小增加了七倍,训练数据量增加了十二倍。DINOv3 集成了架构创新,特别采用了 Gram anchoring 来解决密集特征图退化问题,以及轴向 RoPE 结合抖动的方法来提高在不同图像分辨率和宽高比下的鲁棒性。
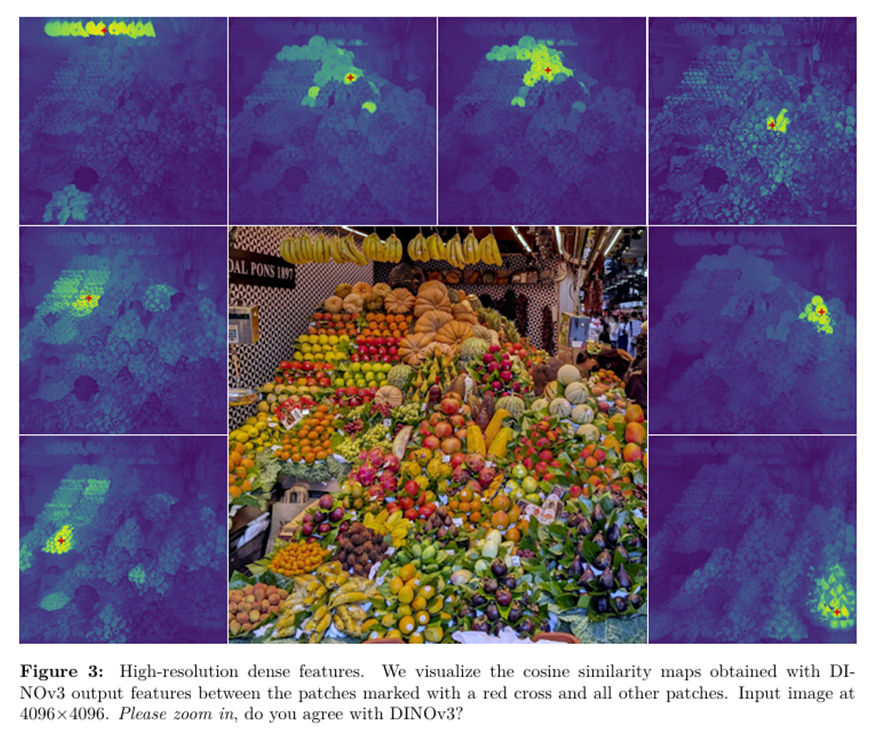
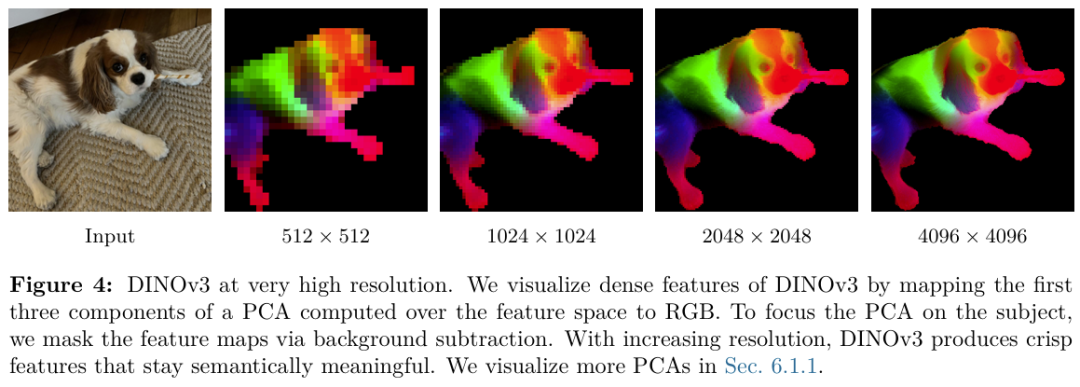
DINOv3 能够生成高分辨率、密集的特征图,从而推动图像分类、语义分割和目标检测方面的卓越性能。即使在未经微调的情况下,它也能始终如一地超越专用模型,在广泛的视觉任务中展现出最先进的结果。
DINOv3模型家族
通过 DINOv3,我们显著改善了密集特征图的退化问题,这要归功于 Gram anchoring。随着 SSL 导致的训练模型规模扩大,结果是显着的性能提升。在这项工作中,我们成功地训练了一个包含 70 亿参数的 DINO 模型。由于如此大的模型需要大量的资源来运行,我们应用蒸馏技术将其知识压缩成更小的变体。因此,我们提出了 DINOv3 视觉模型家族,这是一套全面的设计,旨在解决广泛的计算机视觉挑战。
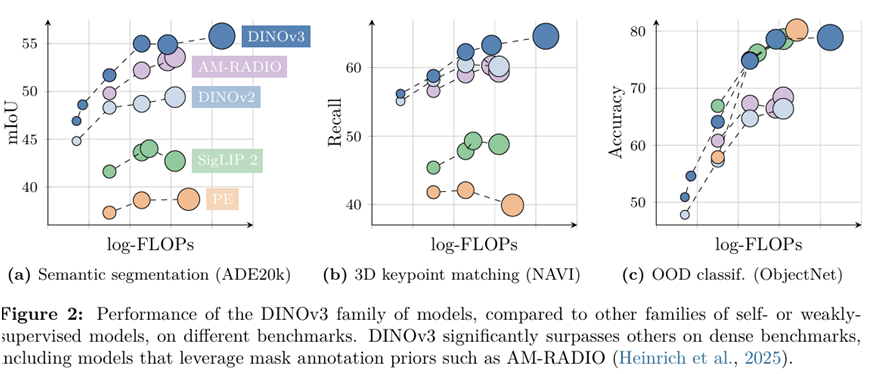
该模型家族旨在通过提供可扩展的解决方案来推进最先进的技术,这些解决方案适应不同的资源限制和部署场景。蒸馏过程生成了多个规模的模型变体,包括 Vision Transformer(ViT)Small、Base 和 Large,以及基于 ConvNeXt 的架构。值得注意的是,高效且广泛采用的 ViT-L 模型在各种任务中的表现接近原始的 70 亿教师模型的水平。总体而言,DINOv3 家族在一个广泛的基准测试中表现出强大的性能,在全局任务上与竞争模型匹配或超越其准确性,同时在密集预测任务中显著超过它们。
学习OpenVINO2025
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号