大语言与多模态模型架构关键组件-混合专家(MOE)详解

大语言与多模态模型架构关键组件-混合专家(MOE)详解

OpenCV学堂
发布于 2026-04-02 21:36:03
发布于 2026-04-02 21:36:03
在查看最新发布的大型语言模型(LLM)时,你经常会在标题中看到“MoE”。这个“MoE”代表什么?为什么这么多大型语言模型在使用它?

专家混合(MoE)是一种基于Transformers构建的高级架构。其主要理念是通过激活少数称为专家的专业网络,使模型更高效。
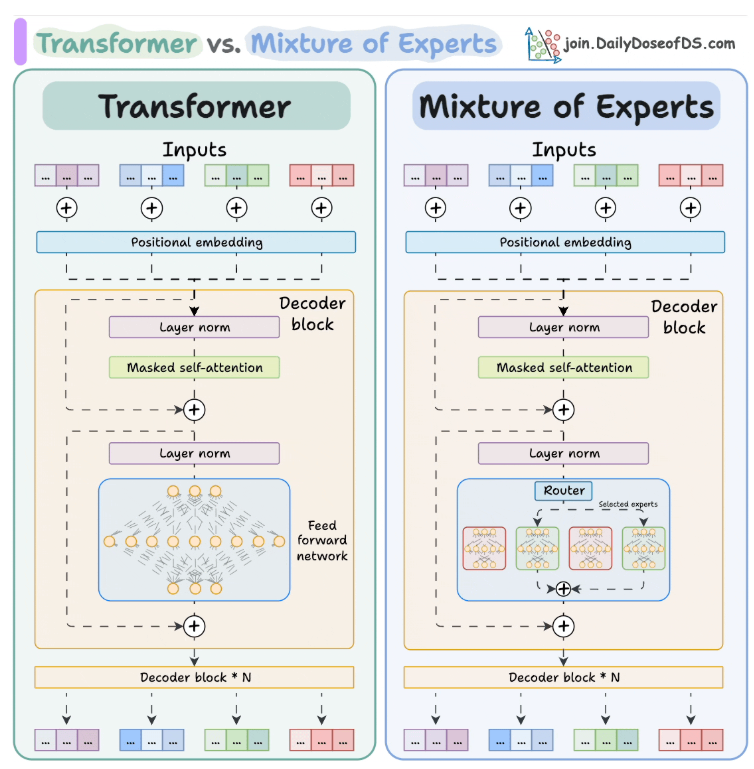
每个专家都是一个轻量级前馈神经网络,每次只根据输入选择少数专家。该选择由路由器处理,在推理过程中动态选择每个标记最相关的专家。
通过每个输入只使用少数专家,MoE模型可以:
大幅降低计算成本,
提升整体模型容量,
并允许不同专家专注于不同类型的数据或任务。这种模块化方法使模型能够扩展到数千亿参数,同时保持推理的快速高效。MoE的两个主要组成部分,即专家和路由器,这些内容在典型的基于LLM架构中应用。
MOE解释
专家混合(MoE)是一种利用多个不同子模型(或称“专家”)来提升大型语言模型质量的技术。定义 MoE 的两个主要组成部分:
专家——每个FFNN层现在都有一组“专家”,其中可选择一个子集。这些“专家”通常是FFNN本人。
路由器或网关网络——决定哪些令牌发送给哪些专家。在具有MoE的LLM的每一层中,我们都能找到(较为专业化的)专家:
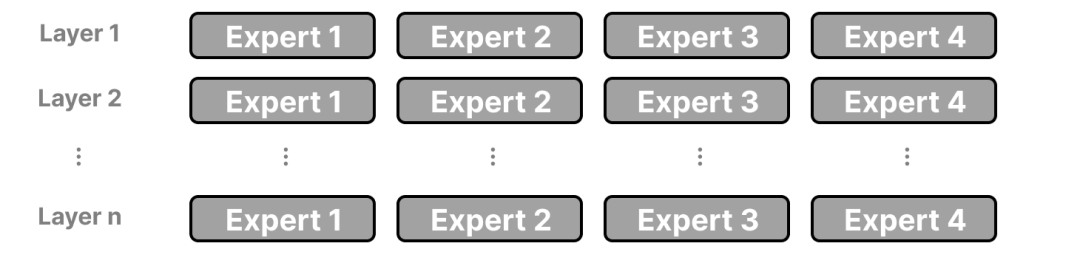
更具体地说,他们的专长是在特定情境下处理特定token。
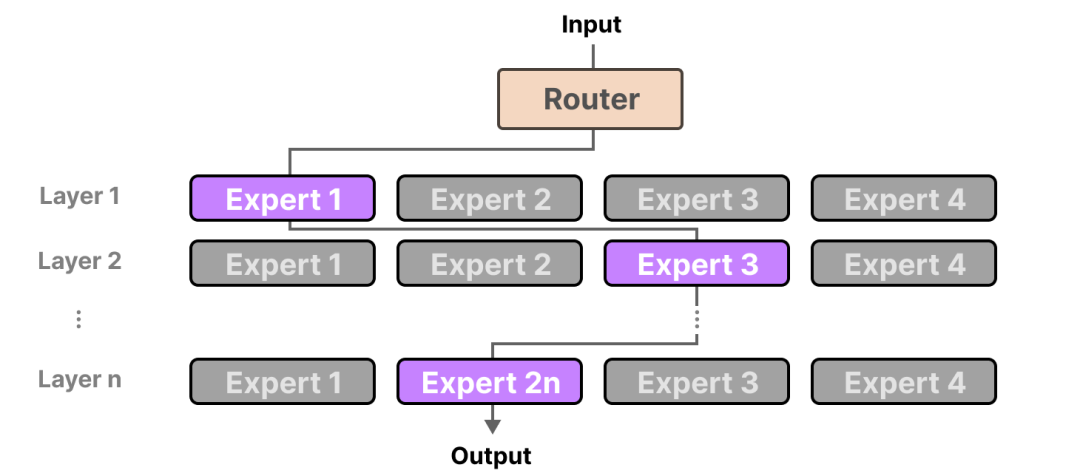
路由器(门网络)会选择最适合特定输入的专家:
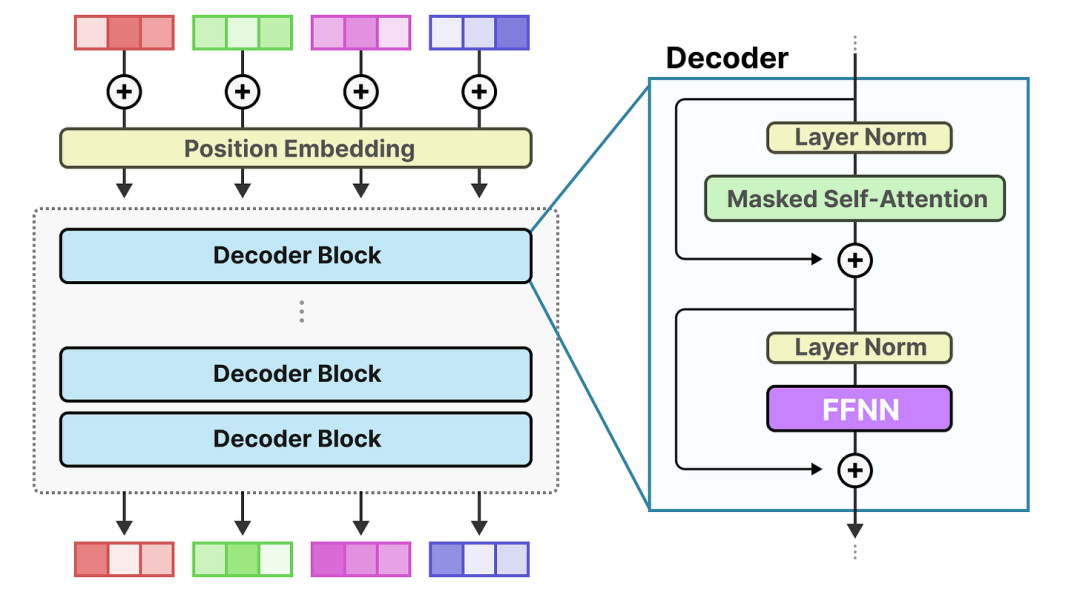
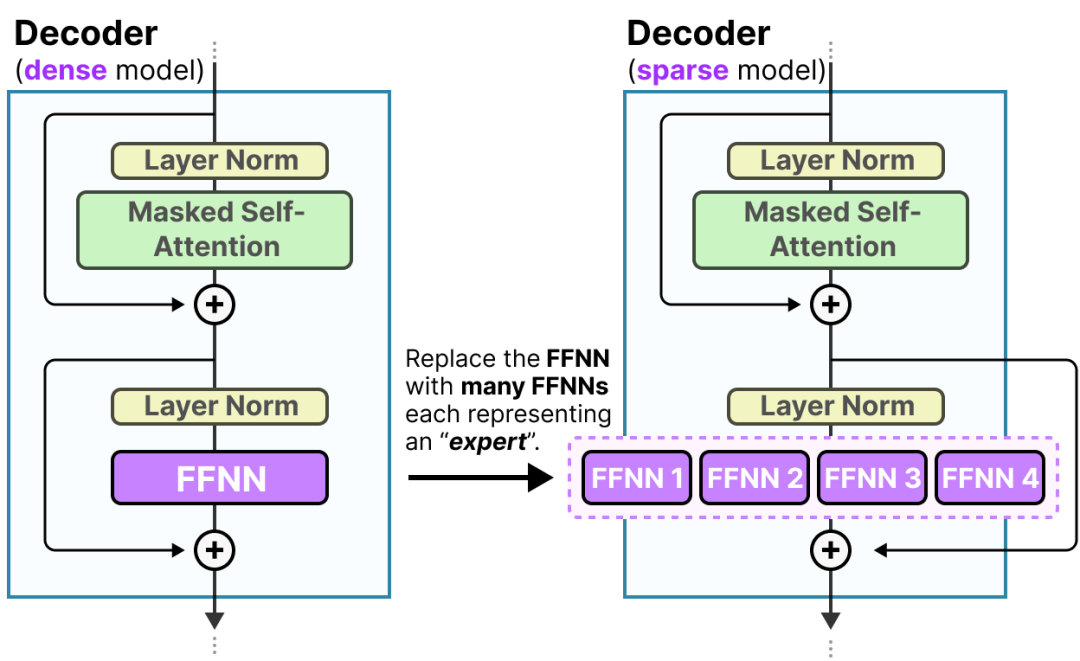
专家混合(MoE)都起源于大型语言模型(LLM)相对基础的功能,即前馈神经网络(FFNN)。
请记住,标准的纯解码器变换器架构在层规范化后应用FFNN:
基于MOE之后的解码器块的可视化,它现在会包含更多的FFNN(每个专家一个)
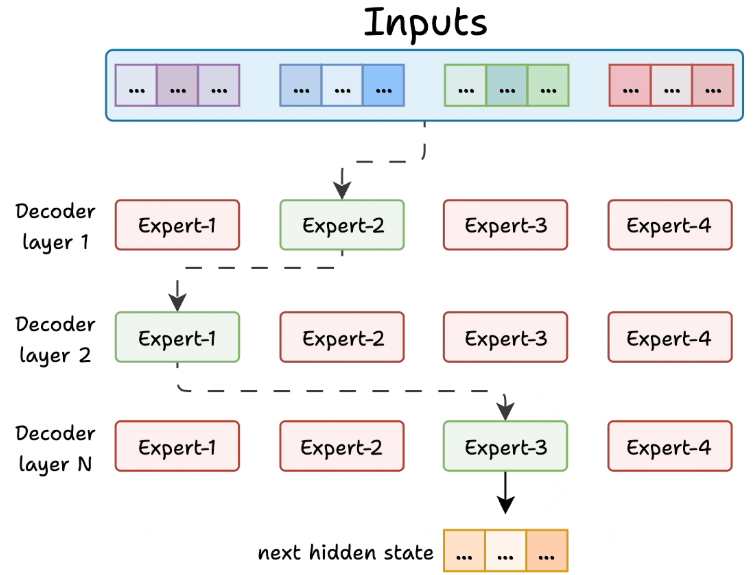
专家选择使用路由器完成,路由器类似于多类分类器。具体流程如下:
路由器接收令牌嵌入作为输入。
它计算了可用专家的软最大分布。
它根据这些分数选出顶尖的K专家(通常是1或2名)。
只有被选中的专家处理该令牌。路由器与模型其他部分共同训练,学习根据输入选择最合适的专家。
混合专家的优势
MoE架构代表了LLM模型设计上的重大进步。以下是它们重要的原因:
由于专家激活稀疏,推断速度更快
更高容量,更低的计算需求
改进专业化与任务适应性
可扩展到庞大参数大小
尽管MoE在训练过程中带来了复杂性,但路由器的精心设计、专家级平衡和容量控制使其成为下一代AI系统的强大工具。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号