FAISS|可扩展、高维人工智能特征搜索库

FAISS|可扩展、高维人工智能特征搜索库

OpenCV学堂
发布于 2026-04-02 21:49:45
发布于 2026-04-02 21:49:45
FAISS(Facebook AI 相似性搜索)是 Meta 开发的开源库,用于以令人印象深刻的效率处理大规模、高维数据查询。它将原始数据(如图像、文本片段或交易记录)转换为特征嵌入,从而实现快速检索,而无需暴力破解每次比较。
图片
许多人工智能驱动的系统在数据超过几百万条目时陷入困境,导致查询缓慢和高昂的硬件成本。FAISS 通过将每个查询仅集中在数据集最相关的部分来解决这一瓶颈,从而大大减少计算时间。在 Facebook Engineering 的官方博客中,该团队强调了 GPU 加速和量化如何使 FAISS 能够支持实时推荐、欺诈检测等。
FAISS 如何在幕后工作
现代人工智能通常将信息(无论是产品图像、文本段落还是用户行为)编码为高维向量。处理数十亿个这样的向量在计算上会变得爆炸性,除非搜索空间缩小到可能匹配的匹配项。
FAISS 通过对向量进行聚类或分组来解决这个问题,以便查询只需要扫描整个数据集的一小部分。最终效果:大幅减少查询时间和硬件开销。
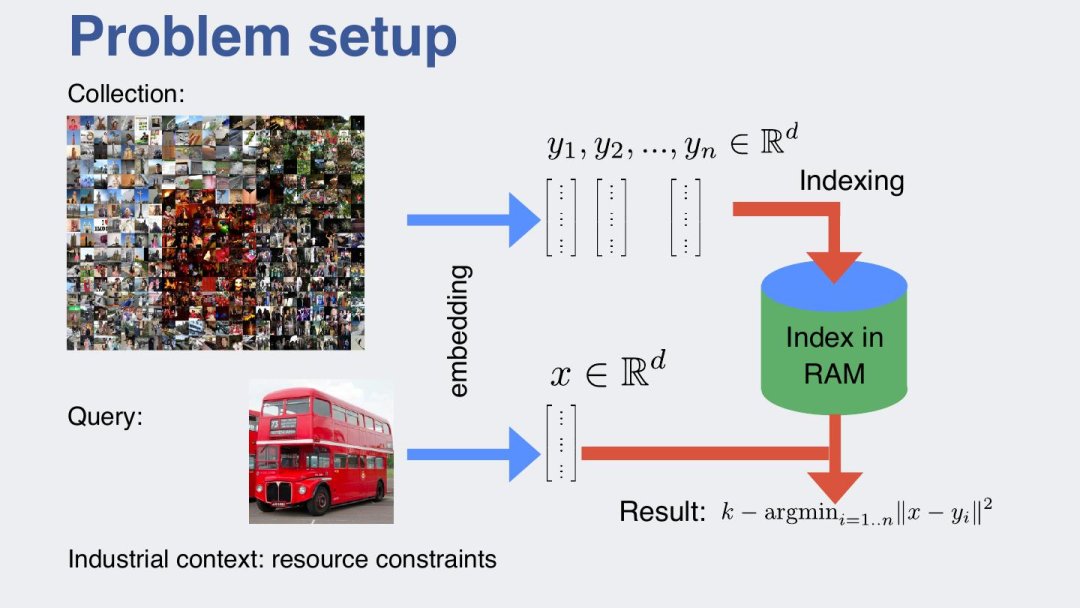
图片
高级索引:IVF、HNSW 等
FAISS 提供了多种索引方法,每种方法都以不同的方式平衡精度、速度和内存:
IVF-Flat:将数据拆分为粗略的“细胞”,然后在这些细胞内进行精确搜索。
IVF-PQ:将 IVF 与产品量化合并以压缩向量,实现更快的大规模近似搜索。
HNSW:使用分层可导航小世界图来启用快速近似最近邻查询。
OPQ:建立在乘积量化的基础上,优化了向量的拆分方式以进行压缩。精确与近似如果您需要完美的精度(例如,某些医疗诊断),FAISS 支持精确搜索 (IndexFlat)。然而,IVF-PQ 或 HNSW 等近似最近邻 (ANN) 方法通常会带来巨大的速度提升,而准确率的下降可以忽略不计——这在十亿尺度大关上至关重要。
GPU加速
FAISS 利用图形处理单元进行并行作。GPU 可以在几毫秒内处理数百万次相似性检查,使实时 AI 搜索不仅成为可能,而且变得实用。缺乏本地 GPU 集群的团队通常利用 AWS 或 GCP 按需扩展或缩减资源。
import faiss
import numpy as np
num_vectors, dim = 10_000_000, 512
data = np.random.random((num_vectors, dim)).astype('float32')
# Example: IVF-Flat index
nlist = 256
quantizer = faiss.IndexFlatL2(dim)
index = faiss.IndexIVFFlat(quantizer, dim, nlist, faiss.METRIC_L2)
index.train(data)
index.add(data)
query = np.random.random((1, dim)).astype('float32')
distances, ids = index.search(query, 10)
# Retrieve the 10 nearest neighbors量化
大型数据集可能会使内存不堪重负。量化压缩矢量(通常对准确性的影响最小),因此您可以使用商用硬件管理数十亿个数据点。在最初的 FAISS 论文(2017 年)中,Meta 的研究人员详细介绍了 PQ(产品量化)和 OPQ(优化产品量化)等方法,强调了高级压缩如何大幅降低存储需求,从而在数据增长时保持高性能。
总结
FAISS 不仅仅是为了加速数据查询;它是人工智能应用程序的战略支柱,这些应用程序在大规模、高维搜索中蓬勃发展。通过将原始数据转换为矢量嵌入,FAISS 使近乎即时的检索成为现实,无论您是在视觉搜索引擎中匹配图像还是隔离金融中的细微欺诈模式。
https://github.com/facebookresearch/faiss本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号