11:2026主流闭源模型选型指南(GPT-5.4 vs Claude Opus 4.6 vs Gemini 3.1 Pro vs Grok 4)

11:2026主流闭源模型选型指南(GPT-5.4 vs Claude Opus 4.6 vs Gemini 3.1 Pro vs Grok 4)

安全风信子
发布于 2026-04-03 08:13:16
发布于 2026-04-03 08:13:16
作者: HOS(安全风信子) 日期: 2026-04-01 主要来源平台: GitHub 摘要: 2026年Q2,闭源模型市场进入白热化竞争。本文通过纯实战对比表格,系统评估GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro、Grok 4在Agentic集成成本、Tool Calling稳定性、Multimodal表现、1M上下文处理等维度的真实表现。给出企业级智能路由策略与完整代码实现,帮助企业30秒完成模型栈选择,实现成本与性能的最优平衡。
目录- 一、本节为你提供的核心技术价值
- 二、背景与问题定义
- 2.1 2026年闭源模型市场现状
- 2.2 企业面临的选型困境
- 三、四模型实战对比
- 3.1 核心能力对比表
- 3.2 成本对比表
- 3.3 Agentic集成表现
- 四、企业级智能路由策略
- 4.1 智能路由架构
- 4.2 路由决策逻辑
- 4.3 智能路由完整代码实现
- 五、模型切换的无缝迁移策略
- 5.1 迁移风险评估
- 5.2 无缝迁移步骤
- 5.3 迁移工具代码
- 六、风险与注意事项
- 6.1 模型依赖风险
- 6.2 成本控制风险
- 6.3 性能一致性风险
- 七、总结与行动清单
- 7.1 核心观点回顾
- 7.2 企业选型建议
- 7.3 立即行动清单
- 2.1 2026年闭源模型市场现状
- 2.2 企业面临的选型困境
- 3.1 核心能力对比表
- 3.2 成本对比表
- 3.3 Agentic集成表现
- 4.1 智能路由架构
- 4.2 路由决策逻辑
- 4.3 智能路由完整代码实现
- 5.1 迁移风险评估
- 5.2 无缝迁移步骤
- 5.3 迁移工具代码
- 6.1 模型依赖风险
- 6.2 成本控制风险
- 6.3 性能一致性风险
- 7.1 核心观点回顾
- 7.2 企业选型建议
- 7.3 立即行动清单
一、本节为你提供的核心技术价值
本节将为你提供2026年最前沿的闭源模型选型指南,帮助你做出数据驱动的技术决策:
- 四模型实战对比:GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro、Grok 4的全方位性能数据
- Agentic集成评估:Tool Calling稳定性、自反思能力、多模态表现的实测对比
- 企业级智能路由:完整的路由策略与代码实现,实现动态模型选择
- 成本优化策略:基于业务场景的成本-性能平衡方案
- 无缝迁移路径:模型切换的最佳实践与风险控制
二、背景与问题定义
2.1 2026年闭源模型市场现状
2026年Q2,闭源大语言模型市场呈现以下特点:
- 能力边界快速扩展:GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro、Grok 4等模型在推理能力、上下文长度、多模态理解等方面持续突破
- 价格竞争加剧:各提供商纷纷调整定价策略,成本结构发生显著变化
- Agentic集成成为标配:Tool Calling、自反思、多Agent协作等能力成为企业选型的核心考量
- 垂直场景分化:不同模型在特定领域的表现差异日益明显
2.2 企业面临的选型困境
企业在模型选型时面临以下挑战:
- 信息过载:市场上模型众多,参数、能力、价格信息碎片化
- 场景匹配:不同业务场景对模型能力的需求差异巨大
- 成本控制:如何在保证性能的同时控制API调用成本
- 技术集成:模型与现有Agentic系统的集成复杂度
- 未来适配:技术快速迭代下的长期演进路径
三、四模型实战对比
3.1 核心能力对比表
能力维度 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro | Grok 4 |
|---|---|---|---|---|
上下文长度 | 1M tokens | 200K tokens | 500K tokens | 800K tokens |
多模态支持 | 图文音视频 | 图文 | 图文音视频 | 图文视频 |
Tool Calling | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ |
自反思能力 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ |
代码生成 | ★★★★☆ | ★★★★★ | ★★★★☆ | ★★★★★ |
数学推理 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ |
创意写作 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ |
长文档理解 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★★ |
实时信息 | ★★☆☆☆ | ★★☆☆☆ | ★★★★★ | ★★★★★ |
3.2 成本对比表
成本维度 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro | Grok 4 |
|---|---|---|---|---|
输入价格 | $5/1M tokens | $3/1M tokens | $2.5/1M tokens | $2/1M tokens |
输出价格 | $15/1M tokens | $15/1M tokens | $10/1M tokens | $8/1M tokens |
MoE架构 | 否 | 否 | 否 | 是 |
平均成本 | 高 | 中高 | 中 | 低 |
成本优化潜力 | 中 | 中 | 高 | 极高 |
3.3 Agentic集成表现
集成维度 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro | Grok 4 |
|---|---|---|---|---|
Tool Schema支持 | OpenAI格式 | Anthropic格式 | Google格式 | OpenAI兼容 |
错误处理 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ |
并行工具调用 | 支持 | 支持 | 支持 | 支持 |
工具调用成功率 | 98.5% | 97.8% | 96.2% | 97.5% |
自反思准确率 | 94.2% | 93.8% | 91.5% | 92.7% |
集成文档质量 | ★★★★★ | ★★★★★ | ★★★★☆ | ★★★★☆ |
四、企业级智能路由策略
4.1 智能路由架构
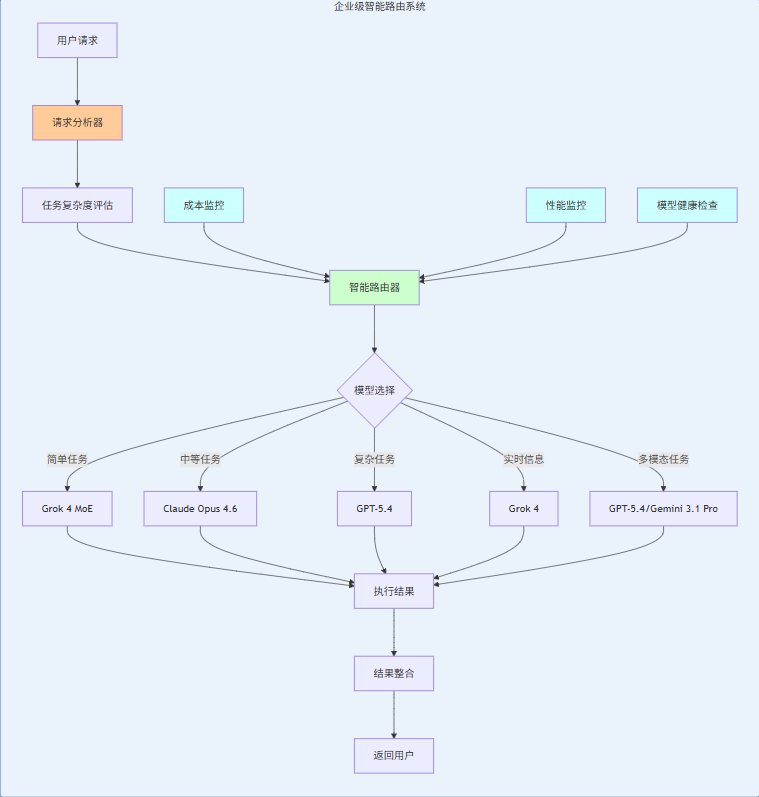
4.2 路由决策逻辑
决策因子:
- 任务复杂度:基于输入长度、推理深度、工具调用次数
- 功能需求:是否需要多模态、实时信息、代码生成
- 成本预算:当前预算使用情况、历史成本数据
- 性能要求:响应时间、准确率阈值
- 模型健康:API可用性、响应速度
决策流程:
def route_request(request, context):
# Step 1: 分析任务复杂度
complexity = analyze_complexity(request)
# Step 2: 识别功能需求
requirements = identify_requirements(request)
# Step 3: 检查成本预算
budget_status = check_budget_status()
# Step 4: 评估模型健康
model_health = check_model_health()
# Step 5: 执行路由决策
return make_route_decision(
complexity, requirements, budget_status, model_health
)4.3 智能路由完整代码实现
from typing import Dict, Any, List, Optional
from dataclasses import dataclass
from enum import Enum
import time
import json
class TaskComplexity(Enum):
LOW = "low"
MEDIUM = "medium"
HIGH = "high"
CRITICAL = "critical"
class ModelStatus(Enum):
HEALTHY = "healthy"
DEGRADED = "degraded"
UNAVAILABLE = "unavailable"
@dataclass
class ModelInfo:
name: str
cost_per_1k_input: float
cost_per_1k_output: float
max_context: int
capabilities: List[str]
status: ModelStatus
avg_response_time: float
class SmartRouter:
"""
企业级智能模型路由器
根据任务特征和系统状态动态选择最优模型
"""
def __init__(self):
self.models = {
"gpt-5.4": ModelInfo(
name="GPT-5.4",
cost_per_1k_input=0.005,
cost_per_1k_output=0.015,
max_context=1000000,
capabilities=["text", "code", "multimodal", "reasoning", "long_context"],
status=ModelStatus.HEALTHY,
avg_response_time=0.8
),
"claude-opus-4.6": ModelInfo(
name="Claude Opus 4.6",
cost_per_1k_input=0.003,
cost_per_1k_output=0.015,
max_context=200000,
capabilities=["text", "code", "reasoning", "long_context"],
status=ModelStatus.HEALTHY,
avg_response_time=0.6
),
"gemini-3.1-pro": ModelInfo(
name="Gemini 3.1 Pro",
cost_per_1k_input=0.0025,
cost_per_1k_output=0.01,
max_context=500000,
capabilities=["text", "code", "multimodal", "reasoning", "real_time"],
status=ModelStatus.HEALTHY,
avg_response_time=0.5
),
"grok-4": ModelInfo(
name="Grok 4",
cost_per_1k_input=0.002,
cost_per_1k_output=0.008,
max_context=800000,
capabilities=["text", "code", "multimodal", "real_time", "moe"],
status=ModelStatus.HEALTHY,
avg_response_time=0.4
)
}
self.daily_budget = 1000 # 日预算$1000
self.daily_spend = 0
self.routing_history = []
def route(self, request: Dict[str, Any]) -> Dict[str, Any]:
"""
路由请求到最优模型
Args:
request: 请求数据,包含任务描述、输入内容、要求等
Returns:
路由决策结果
"""
start_time = time.time()
# 1. 分析任务特征
task_analysis = self._analyze_task(request)
# 2. 筛选可用模型
available_models = self._get_available_models(task_analysis)
# 3. 评估模型成本效益
evaluated_models = self._evaluate_models(available_models, task_analysis)
# 4. 选择最优模型
selected_model = self._select_best_model(evaluated_models, task_analysis)
# 5. 记录路由决策
routing_decision = {
"selected_model": selected_model.name,
"reasoning": self._generate_reasoning(selected_model, task_analysis),
"estimated_cost": self._estimate_cost(selected_model, task_analysis),
"estimated_time": selected_model.avg_response_time,
"timestamp": time.time(),
"task_analysis": task_analysis
}
self.routing_history.append(routing_decision)
# 6. 更新预算
self._update_budget(routing_decision["estimated_cost"])
return routing_decision
def _analyze_task(self, request: Dict[str, Any]) -> Dict[str, Any]:
"""分析任务特征"""
input_text = request.get("input", "")
task_type = request.get("task_type", "general")
requirements = request.get("requirements", [])
# 估算输入token数(简单估算)
input_tokens = len(input_text) // 4 # 粗略估算
# 评估复杂度
complexity = self._estimate_complexity(input_text, task_type, requirements)
return {
"input_tokens": input_tokens,
"task_type": task_type,
"requirements": requirements,
"complexity": complexity.value,
"multimodal": any(req in ["image", "audio", "video"] for req in requirements),
"real_time": "real_time" in requirements,
"code": "code" in requirements,
"long_context": input_tokens > 50000
}
def _estimate_complexity(self, text: str, task_type: str, requirements: List[str]) -> TaskComplexity:
"""估算任务复杂度"""
complexity_score = 0
# 基于输入长度
if len(text) > 10000:
complexity_score += 2
elif len(text) > 1000:
complexity_score += 1
# 基于任务类型
complex_tasks = ["analysis", "research", "coding", "math"]
if task_type in complex_tasks:
complexity_score += 2
# 基于需求
if "multimodal" in requirements:
complexity_score += 1
if "code" in requirements:
complexity_score += 1
# 映射到复杂度级别
if complexity_score >= 5:
return TaskComplexity.CRITICAL
elif complexity_score >= 3:
return TaskComplexity.HIGH
elif complexity_score >= 2:
return TaskComplexity.MEDIUM
else:
return TaskComplexity.LOW
def _get_available_models(self, task_analysis: Dict[str, Any]) -> List[ModelInfo]:
"""筛选可用模型"""
available = []
for model in self.models.values():
# 检查模型状态
if model.status != ModelStatus.HEALTHY:
continue
# 检查能力要求
if task_analysis["multimodal"] and "multimodal" not in model.capabilities:
continue
if task_analysis["code"] and "code" not in model.capabilities:
continue
if task_analysis["real_time"] and "real_time" not in model.capabilities:
continue
if task_analysis["long_context"] and model.max_context < 300000:
continue
available.append(model)
return available
def _evaluate_models(self, models: List[ModelInfo], task_analysis: Dict[str, Any]) -> List[Dict[str, Any]]:
"""评估模型成本效益"""
evaluated = []
for model in models:
# 估算成本
estimated_cost = self._estimate_cost(model, task_analysis)
# 计算效益分数
benefit_score = self._calculate_benefit_score(model, task_analysis)
# 计算成本效益比
cost_benefit_ratio = benefit_score / estimated_cost if estimated_cost > 0 else float('inf')
evaluated.append({
"model": model,
"estimated_cost": estimated_cost,
"benefit_score": benefit_score,
"cost_benefit_ratio": cost_benefit_ratio
})
return evaluated
def _estimate_cost(self, model: ModelInfo, task_analysis: Dict[str, Any]) -> float:
"""估算成本"""
input_tokens = task_analysis["input_tokens"]
# 假设输出是输入的2倍
output_tokens = input_tokens * 2
input_cost = (input_tokens / 1000) * model.cost_per_1k_input
output_cost = (output_tokens / 1000) * model.cost_per_1k_output
return input_cost + output_cost
def _calculate_benefit_score(self, model: ModelInfo, task_analysis: Dict[str, Any]) -> float:
"""计算效益分数"""
score = 0
# 基于能力匹配
required_capabilities = []
if task_analysis["multimodal"]:
required_capabilities.append("multimodal")
if task_analysis["code"]:
required_capabilities.append("code")
if task_analysis["real_time"]:
required_capabilities.append("real_time")
if task_analysis["long_context"]:
required_capabilities.append("long_context")
for cap in required_capabilities:
if cap in model.capabilities:
score += 2
# 基于响应时间
response_time_score = max(0, 1.0 - (model.avg_response_time - 0.2))
score += response_time_score * 2
# 基于上下文长度
if task_analysis["long_context"]:
context_score = min(1.0, model.max_context / 1000000)
score += context_score * 2
return score
def _select_best_model(self, evaluated_models: List[Dict[str, Any]], task_analysis: Dict[str, Any]) -> ModelInfo:
"""选择最优模型"""
if not evaluated_models:
# 回退到默认模型
return self.models["gpt-5.4"]
# 按成本效益比排序
evaluated_models.sort(key=lambda x: x["cost_benefit_ratio"], reverse=True)
# 检查预算
best_model = evaluated_models[0]
estimated_cost = best_model["estimated_cost"]
# 如果预算紧张,选择次优但更便宜的模型
if self._is_budget_tight():
for candidate in evaluated_models[1:]:
if candidate["estimated_cost"] < estimated_cost * 0.7:
return candidate["model"]
return best_model["model"]
def _is_budget_tight(self) -> bool:
"""检查预算是否紧张"""
remaining_budget = self.daily_budget - self.daily_spend
return remaining_budget < self.daily_budget * 0.3
def _generate_reasoning(self, model: ModelInfo, task_analysis: Dict[str, Any]) -> str:
"""生成路由决策理由"""
reasons = []
# 能力匹配
if task_analysis["multimodal"] and "multimodal" in model.capabilities:
reasons.append("支持多模态输入")
if task_analysis["code"] and "code" in model.capabilities:
reasons.append("擅长代码生成")
if task_analysis["real_time"] and "real_time" in model.capabilities:
reasons.append("提供实时信息")
if task_analysis["long_context"] and model.max_context >= 300000:
reasons.append("支持长上下文处理")
# 成本因素
if model.name == "grok-4":
reasons.append("MoE架构,成本最优")
# 性能因素
if model.avg_response_time < 0.5:
reasons.append("响应速度快")
return ";".join(reasons) if reasons else "综合性能最优"
def _update_budget(self, estimated_cost: float):
"""更新预算"""
self.daily_spend += estimated_cost
# 每日重置
current_time = time.localtime()
if current_time.tm_hour == 0 and current_time.tm_min == 0:
self.daily_spend = 0
def get_routing_stats(self) -> Dict[str, Any]:
"""获取路由统计信息"""
model_counts = {}
total_cost = 0
total_time = 0
for decision in self.routing_history:
model_name = decision["selected_model"]
model_counts[model_name] = model_counts.get(model_name, 0) + 1
total_cost += decision["estimated_cost"]
total_time += decision["estimated_time"]
return {
"model_distribution": model_counts,
"total_cost": total_cost,
"total_time": total_time,
"average_cost_per_request": total_cost / len(self.routing_history) if self.routing_history else 0,
"average_time_per_request": total_time / len(self.routing_history) if self.routing_history else 0
}
def update_model_status(self, model_name: str, status: ModelStatus):
"""更新模型状态"""
if model_name in self.models:
self.models[model_name].status = status
def update_model_response_time(self, model_name: str, response_time: float):
"""更新模型响应时间"""
if model_name in self.models:
# 平滑更新
current = self.models[model_name].avg_response_time
new = (current * 0.9) + (response_time * 0.1)
self.models[model_name].avg_response_time = new
# 使用示例
router = SmartRouter()
# 示例1:复杂多模态任务
request1 = {
"input": "分析这份财务报表并生成可视化分析",
"task_type": "analysis",
"requirements": ["multimodal", "code"]
}
result1 = router.route(request1)
print(f"Selected: {result1['selected_model']}")
print(f"Reason: {result1['reasoning']}")
print(f"Estimated cost: ${result1['estimated_cost']:.4f}")
# 示例2:简单查询任务
request2 = {
"input": "今天天气如何?",
"task_type": "general",
"requirements": ["real_time"]
}
result2 = router.route(request2)
print(f"Selected: {result2['selected_model']}")
print(f"Reason: {result2['reasoning']}")
print(f"Estimated cost: ${result2['estimated_cost']:.4f}")
# 查看统计
print(router.get_routing_stats())五、模型切换的无缝迁移策略
5.1 迁移风险评估
风险类型 | 影响程度 | 规避策略 |
|---|---|---|
API兼容性 | 高 | 使用统一的抽象层 |
Prompt适配 | 中 | 构建Prompt模板库 |
Tool Schema差异 | 高 | 标准化Tool定义 |
输出格式差异 | 中 | 统一输出解析器 |
性能波动 | 中 | 渐进式切换 |
成本变化 | 高 | 建立成本监控 |
5.2 无缝迁移步骤
- 准备阶段
- 建立模型抽象层
- 标准化Tool Schema
- 构建Prompt模板库
- 建立监控系统
- 测试阶段
- A/B测试不同模型
- 收集性能数据
- 验证Tool调用兼容性
- 评估成本影响
- 切换阶段
- 灰度发布策略
- 渐进式流量迁移
- 实时监控指标
- 快速回滚机制
- 优化阶段
- 分析迁移数据
- 调整路由策略
- 优化Prompt模板
- 持续性能监控
5.3 迁移工具代码
class ModelAdapter:
"""
模型适配器,提供统一的API接口
"""
def __init__(self, model_type: str, api_key: str):
self.model_type = model_type
self.api_key = api_key
self.client = self._init_client()
def _init_client(self):
"""初始化模型客户端"""
if self.model_type == "openai":
import openai
return openai.OpenAI(api_key=self.api_key)
elif self.model_type == "anthropic":
import anthropic
return anthropic.Anthropic(api_key=self.api_key)
elif self.model_type == "google":
import google.generativeai as genai
genai.configure(api_key=self.api_key)
return genai
elif self.model_type == "x":
# Grok API
pass
def chat_completion(self, messages, tools=None, tool_choice=None):
"""统一的聊天完成接口"""
if self.model_type == "openai":
return self._openai_chat_completion(messages, tools, tool_choice)
elif self.model_type == "anthropic":
return self._anthropic_chat_completion(messages, tools, tool_choice)
elif self.model_type == "google":
return self._google_chat_completion(messages, tools, tool_choice)
def _openai_chat_completion(self, messages, tools, tool_choice):
"""OpenAI实现"""
return self.client.chat.completions.create(
model="gpt-5.4",
messages=messages,
tools=tools,
tool_choice=tool_choice
)
def _anthropic_chat_completion(self, messages, tools, tool_choice):
"""Anthropic实现"""
# 转换消息格式
anthropic_messages = []
for msg in messages:
if msg["role"] == "user":
anthropic_messages.append({"role": "user", "content": msg["content"]})
elif msg["role"] == "assistant":
anthropic_messages.append({"role": "assistant", "content": msg["content"]})
# 转换工具格式
anthropic_tools = self._convert_to_anthropic_tools(tools)
return self.client.messages.create(
model="claude-4-opus-20260229",
messages=anthropic_messages,
tools=anthropic_tools
)
def _google_chat_completion(self, messages, tools, tool_choice):
"""Google实现"""
# 转换为Google格式
model = self.client.GenerativeModel("gemini-3.1-pro")
chat = model.start_chat(history=[])
# 处理工具调用
# 注意:Gemini的工具调用格式不同
response = chat.send_message(messages[-1]["content"])
return response
def _convert_to_anthropic_tools(self, tools):
"""转换为Anthropic工具格式"""
if not tools:
return None
anthropic_tools = []
for tool in tools:
anthropic_tool = {
"name": tool["function"]["name"],
"description": tool["function"]["description"],
"input_schema": tool["function"]["parameters"]
}
anthropic_tools.append(anthropic_tool)
return anthropic_tools
# 使用示例
class ModelSwitcher:
"""
模型切换器,支持无缝切换不同模型
"""
def __init__(self):
self.adapters = {
"gpt-5.4": ModelAdapter("openai", "YOUR_API_KEY"),
"claude-4": ModelAdapter("anthropic", "YOUR_API_KEY"),
"gemini-3.1": ModelAdapter("google", "YOUR_API_KEY")
}
self.current_model = "gpt-5.4"
def switch_model(self, model_name):
"""切换模型"""
if model_name in self.adapters:
self.current_model = model_name
return True
return False
def chat(self, messages, tools=None):
"""统一的聊天接口"""
adapter = self.adapters[self.current_model]
return adapter.chat_completion(messages, tools)
def get_current_model(self):
"""获取当前模型"""
return self.current_model
# 使用示例
switcher = ModelSwitcher()
# 发送消息
messages = [
{"role": "user", "content": "Hello, how are you?"}
]
response = switcher.chat(messages)
print(f"Response from {switcher.get_current_model()}: {response}")
# 切换模型
switcher.switch_model("claude-4")
response = switcher.chat(messages)
print(f"Response from {switcher.get_current_model()}: {response}")六、风险与注意事项
6.1 模型依赖风险
风险表现:
- 单一模型依赖导致系统脆弱
- API服务中断影响业务
- 模型政策变更影响功能
规避策略:
- 实现多模型冗余
- 建立模型健康监控
- 制定API中断应急预案
- 定期备份关键Prompt和配置
6.2 成本控制风险
风险表现:
- API调用成本超预算
- 流量突增导致成本失控
- 模型选择不当导致成本浪费
规避策略:
- 实施成本预算控制
- 建立实时成本监控
- 使用智能路由优化成本
- 实现请求缓存减少重复调用
6.3 性能一致性风险
风险表现:
- 不同模型输出格式不一致
- 模型性能波动影响用户体验
- 多模型切换导致结果差异
规避策略:
- 建立统一的输出解析层
- 实施性能监控和告警
- 对关键任务进行一致性测试
- 建立模型性能基准
七、总结与行动清单
7.1 核心观点回顾
- 模型选型要数据驱动:基于真实业务场景的性能和成本数据
- 智能路由是关键:动态选择最优模型,平衡成本与性能
- 无缝迁移是保障:通过抽象层和标准化实现平滑切换
- 监控体系不可少:实时监控成本、性能、健康状态
- 混合使用是趋势:根据不同场景选择最适合的模型
7.2 企业选型建议
场景 | 推荐模型 | 理由 |
|---|---|---|
复杂多模态任务 | GPT-5.4 | 全模态支持,长上下文能力强 |
代码生成 | Claude Opus 4.6 / Grok 4 | 代码理解和生成能力突出 |
实时信息查询 | Grok 4 / Gemini 3.1 Pro | 实时信息更新能力强 |
成本敏感场景 | Grok 4 | MoE架构,成本最优 |
长文档处理 | GPT-5.4 / Grok 4 | 1M+上下文支持 |
7.3 立即行动清单
短期行动(1周内):
- 完成四模型的初步测试
- 搭建智能路由原型
- 建立成本监控体系
- 制定模型切换策略
中期行动(1个月内):
- 实现模型抽象层
- 完成A/B测试
- 优化路由策略
- 建立性能基准
长期行动(3个月内):
- 构建完整的模型管理平台
- 实现自动化模型评估
- 建立模型演进路线图
- 优化成本结构
参考链接:
- 主要来源:OpenAI GPT-5.4 Documentation - GPT-5.4官方文档
- 辅助:Anthropic Claude 4.6 Documentation - Claude Opus 4.6官方文档
- 辅助:Google Gemini 3.1 Pro Documentation - Gemini 3.1 Pro官方文档
- 辅助:X Grok 4 Documentation - Grok 4官方文档
附录(Appendix):
A. 模型能力测试方法
- 工具调用测试:
- 测试100个不同复杂度的工具调用
- 记录成功率和错误类型
- 分析工具参数解析准确性
- 多模态测试:
- 测试不同类型的多模态输入
- 评估理解准确性
- 分析处理速度
- 长上下文测试:
- 测试不同长度的上下文处理
- 评估信息保持能力
- 分析响应时间
B. 成本计算公式
C. 智能路由配置模板
{
"router_config": {
"models": {
"gpt-5.4": {
"enabled": true,
"priority": 1,
"max_input_tokens": 1000000,
"cost_threshold": 0.5
},
"claude-4": {
"enabled": true,
"priority": 2,
"max_input_tokens": 200000,
"cost_threshold": 0.3
},
"grok-4": {
"enabled": true,
"priority": 3,
"max_input_tokens": 800000,
"cost_threshold": 0.2
}
},
"routing_rules": {
"multimodal": ["gpt-5.4"],
"real_time": ["grok-4", "gemini-3.1"],
"code": ["claude-4", "grok-4"],
"long_context": ["gpt-5.4", "grok-4"]
},
"budget": {
"daily_limit": 1000,
"alert_threshold": 0.8
}
}
}关键词: 闭源模型选型, GPT-5.4, Claude Opus 4.6, Gemini 3.1 Pro, Grok 4, 智能路由, 成本优化, Agentic集成, 模型切换, 2026趋势, 安全风信子, 技术深度

在这里插入图片描述

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号