OFC 2026 NVIDIA报告:面向AI工厂的光交换(OCS)技术使能、应用场景与落地挑战

OFC 2026 NVIDIA报告:面向AI工厂的光交换(OCS)技术使能、应用场景与落地挑战

光芯
发布于 2026-04-03 08:46:37
发布于 2026-04-03 08:46:37
本文来自于OFC 2026「Optical Networking for AI Datacenters: Technology Enablers and Key Applications」专题论坛中,来自NVIDIA的Giannis Patronas所作的题目为《Optical Switching for AI factories》的演讲报告内容。

一、行业背景:AI算力爆发带来的系统性网络核心挑战
当前AI产业的指数级发展,已将数据中心网络从配套支撑组件,推升至AI系统设计的核心一阶要素,光网络的性能、能效与可靠性,直接决定了AI超算集群的扩展性上限与运营成本。
1.1 AI算力与集群规模的指数级扩张
AI算力需求的爆发,来自三大核心趋势的叠加:
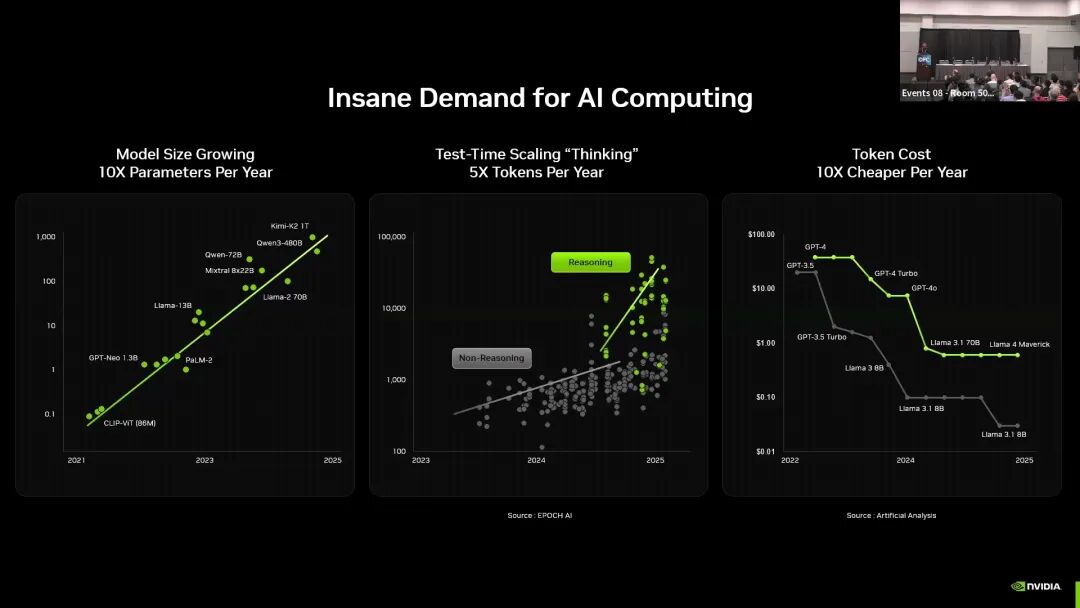
一是大语言模型规模保持每年10倍的增长速度,推理类任务的词元处理量以每年5倍的速度提升,同时词元成本以每年10倍的速度下降,进一步放大了全社会对AI算力的使用需求;
二是单芯片算力实现跨越式提升,从Pascal到Blackwell架构,NVIDIA在8年内实现了1000倍的AI算力飞跃,单芯片FP16算力从19 TFLOPS提升至4000 TFLOPS;

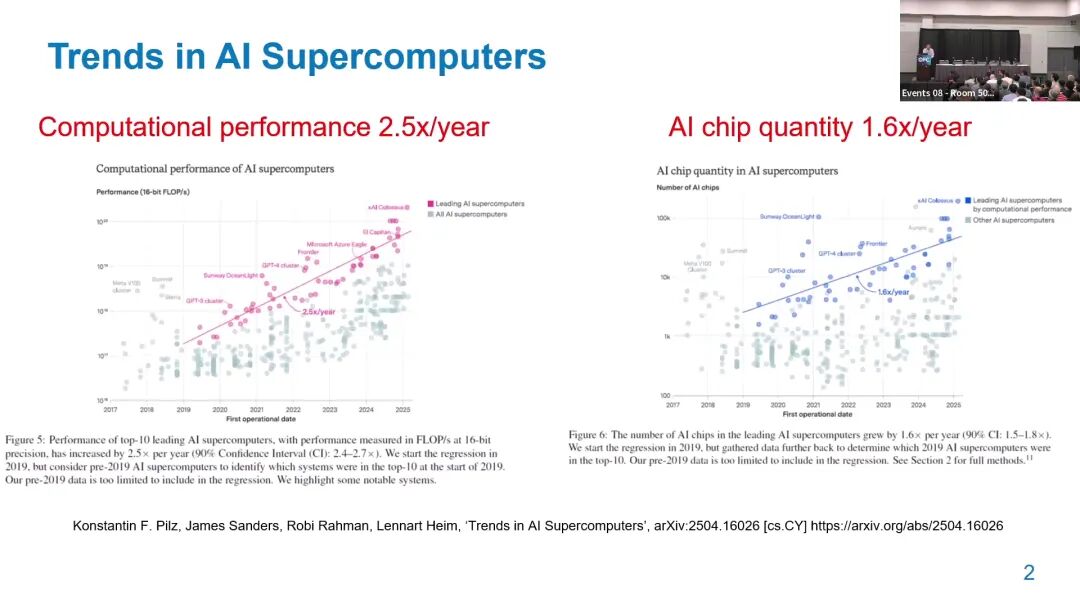
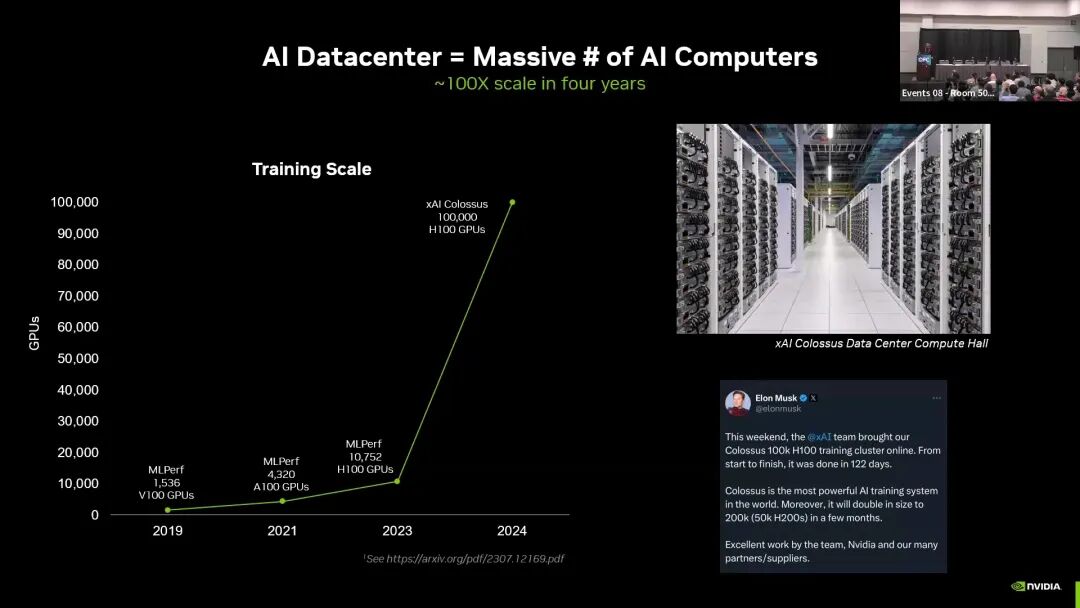
三是AI集群规模极速扩张,AI超算的AI芯片数量以每年1.6倍的速度增长,2019年主流训练集群的GPU规模仅为万级,2024年xAI发布的Colossus集群已上线10万片H100 GPU,并计划在数月内扩容至20万片,4年内集群规模实现了近100倍的提升。
1.2 功耗与可靠性的双重核心瓶颈
集群规模的指数级扩张,也带来了两大无法回避的系统性瓶颈:
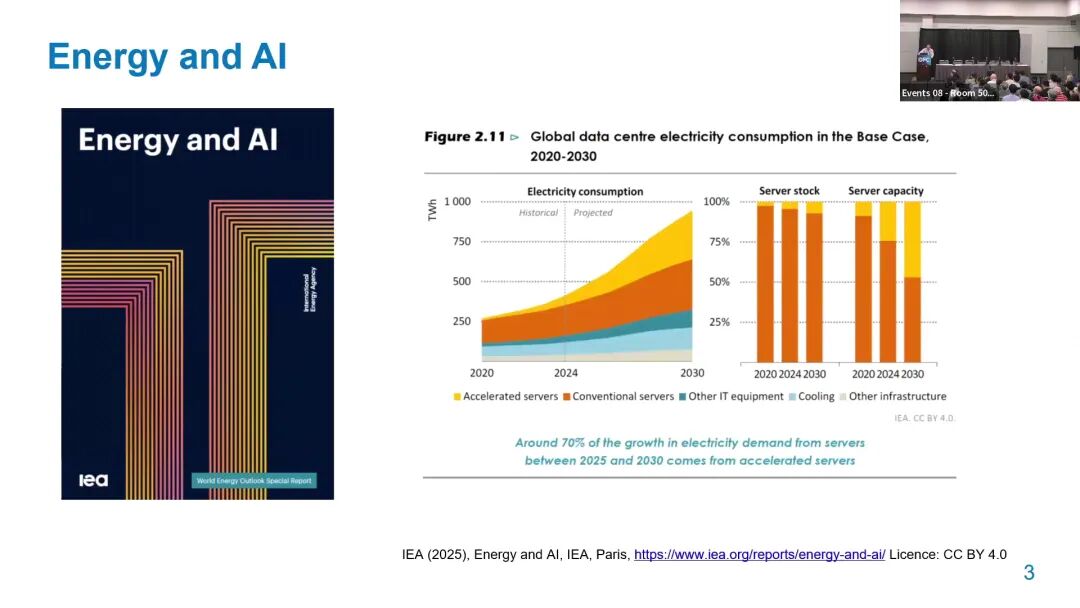
其一是功耗压力持续攀升。根据IEA 2025年发布的《Energy and AI》报告,2025-2030年全球数据中心电力需求增长的70%将来自加速服务器;当前大规模AI集群中,约8%的整机功耗由光网络承担,随着集群规模扩大、传输距离增加,光网络的功耗占比还将进一步提升。

其二是可靠性风险被持续放大。集群规模越大,单次网络故障的影响范围越广,单个网络故障可能导致整个训练任务关联的大量GPU资源被闲置,同时单次可靠性事件的经济成本、运维成本也随集群规模同步增长。
基于上述行业痛点,本次演讲提出核心命题:OCS(光交换)能否成为高速扩张的AI集群所需的高可扩展性、高灵活性、高能效网络的核心使能技术?

二、OCS在AI数据中心的核心应用场景
OCS的核心价值,在于实现了物理层拓扑的可重构,可针对性解决传统电交换网络在AI场景下的功耗、延迟、灵活性瓶颈。演讲明确了OCS在AI数据中心的三类核心插入点,其中重点阐述了横向扩展(Scale-out)与纵向扩展(Scale-up)两大核心应用场景。
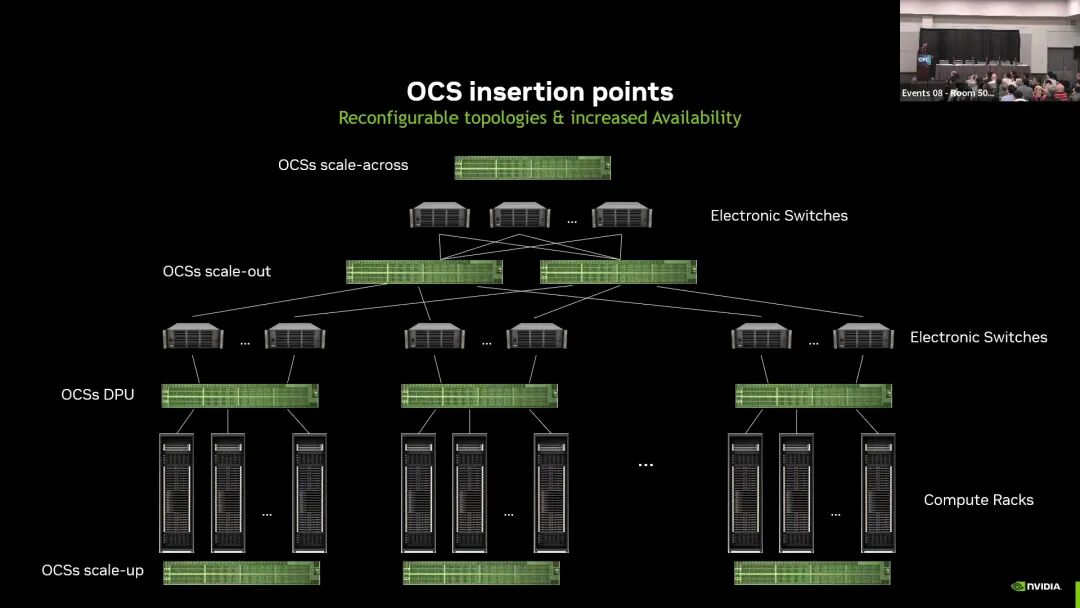
2.1 横向扩展(Scale-out)场景
Scale-out场景定位于数据中心建筑内,InfiniBand/以太网交换层之间的集群互联,OCS在此有两大核心落地用例。

第一个用例是提升网络弹性与故障恢复能力。在电交换层之间插入OCS,配套冗余硬件设计,当网络出现故障时,可通过OCS快速切换链路,剔除故障组件,替换为备用资源,有效缩小故障域,避免大量GPU资源因单点故障被闲置,提升集群整体可用性。
第二个用例是扁平化网络架构,降低功耗与转发延迟。AI训练业务的流量具备可预测、结构化的特征,基于这一特点,可用OCS替代1-2层电交换机,大幅减少电交换芯片与光模块的用量,同时缩短数据转发路径,降低网络延迟,实现更高效、更低功耗的Scale-out组网。
2.2 纵向扩展(Scale-up)场景
Scale-up场景是AI集群高带宽、高密度连接的核心场景,单个计算机架需支持数千条光纤链路,也是OCS最具潜力的新兴落地场景,核心解决静态直连与全电交换架构的固有缺陷。

第一个核心用例是构建灵活高效的大规模Scale-up域。在该场景下,全静态直连架构灵活性极差,无法适配动态变化的业务需求;全电交换架构则存在功耗高、延迟大、光模块用量大的问题。OCS提供了两者之间的最优折中方案,在保持低功耗、低光模块用量优势的同时,支持物理拓扑的动态调整,可灵活适配不同训练任务的流量需求。
第二个核心用例是提升资源利用率与系统可用性。通过OCS构建统一的GPU资源池,可按需分配算力资源,有效利用碎片化的算力;同时在机架运维、固件升级时,可通过OCS无缝下线目标机架,不影响业务的正常运行,大幅提升集群的整体运维效率与业务连续性。
2.3 跨园区扩展(Scale-across)场景
OCS可用于园区内不同楼宇、远程站点之间的集群互联,与当前本地城域网络的应用场景类似,可实现长距离、高带宽的灵活组网,适配多园区级别的超大规模AI集群建设需求。
三、OCS规模化部署的核心技术要求与现存缺口
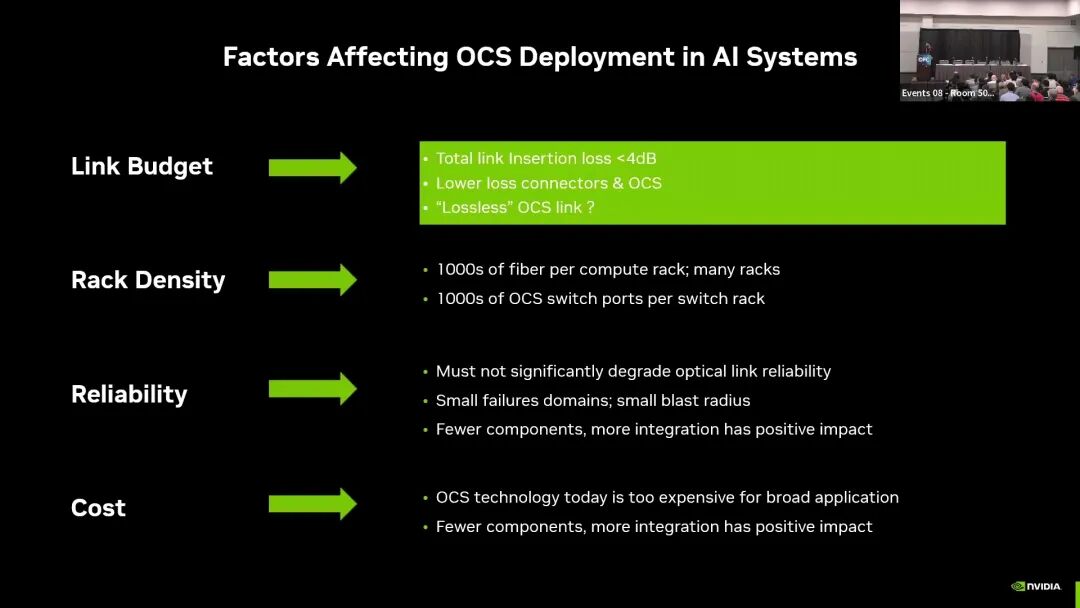
演讲明确指出,当前OCS技术仍无法满足AI集群的规模化商用部署需求,核心需补齐链路预算、集成密度、可靠性、成本四大维度的工程化缺口。

在链路预算维度,AI场景对OCS提出了极为严苛的低损耗要求:全链路插入损耗需控制在4dB以内,需兼容现有DR、FR等标准光模块接口,不劣化链路的BER与FEC性能,同时链路路径中最少包含4个平行光纤连接器。当前的核心缺口是,现有OCS器件的插入损耗过高,无法适配现有标准光模块的链路预算,需开发更低损耗的OCS器件与连接器方案。
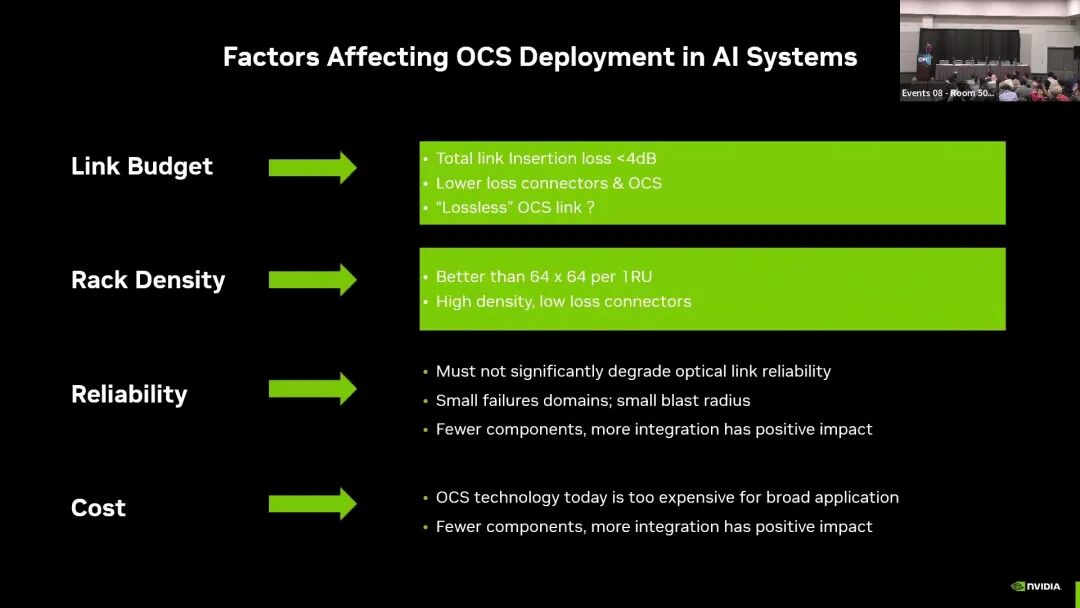
在集成密度维度,AI场景要求OCS设备在1RU空间内实现优于64×64的端口容量,同时配套高密度、低损耗的连接器,以适配单机架数千条光纤的部署需求。当前的核心缺口是,现有OCS设备的端口密度不足,连接器的密度与性能也无法匹配AI集群的高密度布线需求。
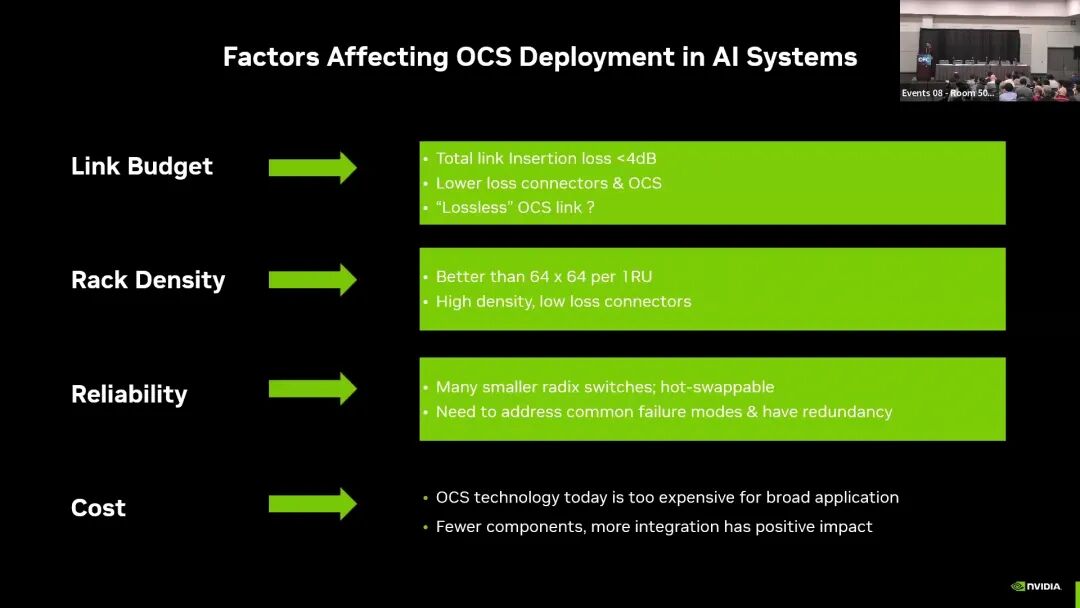
在可靠性维度,AI场景要求OCS设备不引入单点故障,需缩小故障域、控制故障影响范围,支持热插拔的小基数交换机,同时配套完善的冗余设计,不得显著降低光链路的整体可靠性。当前的核心缺口是,现有OCS设备的故障模式不明确,缺乏适配AI集群高可用要求的冗余设计与热插拔能力。
在成本维度,AI集群的规模化部署要求OCS技术可支撑万级端口的商用落地。当前的核心缺口是,OCS技术的整体成本过高,无法适配AI集群的规模化部署需求。
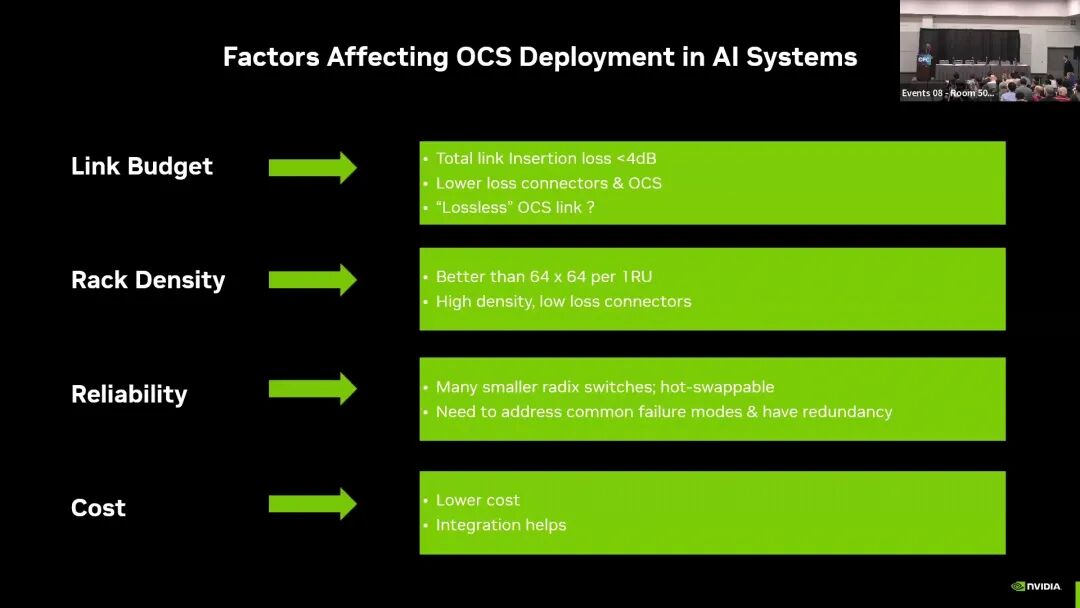
演讲同时指出,减少器件数量、提升芯片集成度,是同时解决成本、密度、可靠性三大缺口的核心方向;而光器件与AI系统的协同设计,是补齐所有技术缺口、实现OCS规模化落地的关键前提。
四、总结与展望

本次演讲的核心结论可归纳为三点:
第一,随着AI集群规模的指数级扩张,光网络已从传统的配套组件,升级为AI系统设计的一阶核心要素,直接决定集群的扩展性、能效与运营成本。
第二,OCS为AI数据中心网络打开了全新的设计空间,可针对性解决传统电交换网络的固有瓶颈,在Scale-out、Scale-up等核心场景具备明确的应用价值与落地潜力。
第三,要实现OCS在AI集群的规模化商用落地,必须补齐链路预算、集成密度、可靠性、成本四大维度的工程化缺口,而器件与系统的协同设计,是实现这一目标的核心前提。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号