Claude Code 源码泄露揭秘:AI 如何学会你的工作流?Skills 系统全链路拆解
原创
Claude Code 源码泄露揭秘:AI 如何学会你的工作流?Skills 系统全链路拆解
原创
运维有术
发布于 2026-04-06 08:05:55
发布于 2026-04-06 08:05:55
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 71 篇,Claude Code 源码揭秘系列第 3 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
封面图 - Claude Code Skills 系统全景信息图
图 1:Claude Code Skills 系统全景——从源码泄露到 Skills 生态
2026 年 3 月 31 日,安全研究员 Chaofan Shou 在美东时间凌晨 4:23 发现了一个打包事故——npm 包 @anthropic-ai/claude-code v2.1.88 里遗漏了 59.8MB 的 .map source map 文件。512,000 行 TypeScript 代码,1,900 个文件,Claude Code 的完整源码暴露在了公众面前。
VentureBeat、Layer5、ide.com 等多家媒体和独立开发者迅速跟进了源码分析。社区讨论的焦点集中在了 KAIROS 自主守护进程模式、Undercover 隐身模式、反蒸馏机制这些听起来就很刺激的功能上。
前面的文章中,我们已经拆解了 Claude Code 的 5 个 Agent 设计模式,也扒出了 Buddy 宠物系统背后的愚人节彩蛋。翻了一圈源码和各方分析报告后,我认为还有一个模块被严重低估了:Skills 系统。
理由很简单。KAIROS 是未来愿景,Undercover 是内部工具,反蒸馏是防御手段——这些都离普通开发者的日常很远。而 Skills 系统,尤其是其中的 /skillify 命令,直接回答了一个根本性的问题:AI 编程工具怎么从"你问它答"进化到"它观察你怎么工作,然后把你的工作流变成可复用的技能"?
今天这篇文章,就从源码层面完整拆解 Claude Code 的 Skills 系统。涉及的核心文件包括 bundledSkills.ts、skillify.ts、simplify.ts、loop.ts、scheduleRemoteAgents.ts、loadSkillsDir.ts 等 10 个关键模块。
1. Skills 系统全景:不只是提示词模板
什么是 Skill?
很多人第一次听到 Claude Code 的 Skills,会觉得它和 Cursor Rules 差不多——不就是写一段提示词让 AI 遵循吗?
翻了源码之后,我发现这个理解差得有点远。
Claude Code 里的一个 Skill,本质上是一个结构化的能力模块,包含完整的元数据定义:
// src/skills/bundledSkills.ts 核心类型
type BundledSkillDefinition = {
name: string; // 技能名称
description: string; // 技能描述
whenToUse: string; // 什么时候触发
argumentHint?: string; // 参数提示
allowedTools?: string[];// 允许使用的工具
context: 'inline' | 'fork'; // 执行方式
agent?: string; // 指定 Agent 类型
hooks?: Hook[]; // 钩子函数
isEnabled?: boolean; // 是否启用
}注意几个关键字段:whenToUse 让 Agent 自己判断要不要激活这个技能;context 区分 inline(在当前会话执行)和 fork(创建子 Agent 执行);allowedTools 控制这个技能能调用哪些工具。
Skill 的载体是 SKILL.md 文件,格式如下:
---
name: my-code-review
description: 代码审查技能
whenToUse: 当用户要求审查代码变更时
context: inline
---
# 步骤
1. 获取 git diff
2. 分析变更内容
3. 输出审查意见
# 成功标准
- 所有变更文件都被覆盖
- 每个问题都标注严重级别
# 执行类型
inline(在当前会话中执行)和 Cursor Rules 的 .cursorrules 文件相比,SKILL.md 的结构化程度高出一个量级。Cursor Rules 本质上是自由文本的偏好描述,而 SKILL.md 是一个有明确 schema 的能力单元。
两类技能来源
Claude Code 的技能有两个来源:
Bundled Skills(内置技能):编译时打包进二进制,通过 registerBundledSkill() 工厂函数注册。src/skills/bundled/index.ts(79 行)是注册入口,启动时把所有内置技能逐个注册进去。
Disk-based Skills(磁盘技能):用户自建的技能,放在 .claude/skills/ 目录下。src/skills/loadSkillsDir.ts(1086 行)负责加载,支持三层优先级:managed(策略强制)→ user(~/.claude/skills/)→ project(.claude/skills/)。
有意思的是,磁盘技能还支持条件激活——通过 frontmatter 里的 paths 字段匹配文件路径。比如一个只对 Python 项目生效的技能,可以设置 paths: ["**/*.py"],只有操作 Python 文件时才触发。这比 Cursor Rules 的"始终应用"模式精细得多。
注册与懒提取机制
registerBundledSkill() 的实现里藏了一个值得学习的工程细节:懒提取(Lazy Extraction)。
内置技能的资源文件(比如 SKILL.md 模板)是压缩存储在二进制里的。注册时并不立即解压,而是设置一个闭包。首次调用时才触发解压,后续调用直接复用结果。如果有并发调用,它们会等待同一个 Promise。
// 简化后的懒提取逻辑
let cached: Promise<string> | null = null;
function getSkillContent(): Promise<string> {
if (cached) return cached;
cached = decompressFromBinary(skillData);
return cached;
}这个设计带来了三个好处:启动速度快(不需要解压所有技能),内存占用低(不用的技能永远不加载),并发安全(多个请求不会重复解压)。
安全防护:从源码看 Anthropic 的安全意识
bundledSkills.ts 里的安全措施写得相当细致:
- 进程级 nonce 防护:
getBundledSkillsRoot()使用 nonce 确保解压路径不被篡改 - 严格权限:目录权限
0o700(仅所有者可读写执行),文件权限0o600(仅所有者可读写) - 符号链接防护:使用
O_NOFOLLOW | O_EXCL标志打开文件,防止符号链接攻击 - 路径遍历防护:
resolveSkillFilePath()验证解析后的路径不会逃出技能目录
说实话,看到这些措施的时候,我对 Anthropic 工程团队的印象加分不少。一个打包错误暴露了源码,但源码里的安全细节经得起审视。
Feature Flag 控制的技能灰度
bundled/index.ts 里还有一套技能灰度发布机制。每个技能可以绑定 Feature Flag:
KAIROS:控制 KAIROS 相关能力AGENT_TRIGGERS:控制 Agent 触发器类技能AGENT_TRIGGERS_REMOTE:控制远程 Agent 触发器BUILDING_CLAUDE_APPS:控制构建类技能RUN_SKILL_GENERATOR:控制技能生成器
部分技能还有用户类型限制。比如 /skillify、/remember、/verify、/stuck 这些命令,目前只对 USER_TYPE === 'ant'(Anthropic 内部用户)开放。社区里有人吐槽这一点,但从产品角度理解,这些高度实验性的功能先在内部验证,再逐步开放,是合理的节奏。
2. /skillify:让 AI 观察并学会你的工作流
如果说 Skills 系统是 Claude Code 的核心竞争力,那 /skillify 就是这个竞争力的引擎。
为什么?因为它是一个元技能——一个用来创建技能的技能。
想想看这意味着什么。传统的 AI 编程工具,不管是 Cursor Rules 还是 GitHub Copilot,规则都是人写的。你告诉 AI "代码风格用 ESLint Airbnb 规范"、"提交信息用 Conventional Commits 格式"——这是自上而下的指令模式。
/skillify 做的是自下而上的学习:AI 观察你在会话中的一举一动,特别是你纠正它的地方,然后自动把这些模式提炼成可复用的技能。
这是两种完全不同的范式。
双输入源设计
src/skills/bundled/skillify.ts(197 行)的核心输入有两个:
- Session Memory(会话记忆):整个会话的对话历史,AI 从中提取你的操作模式
- User Messages(用户消息):特别关注用户纠正 AI 的地方——这些纠正是用户偏好的强烈信号
第二个输入源的设计尤其巧妙。用户纠正 AI 的地方,往往是最能体现个人工作习惯和偏好的场景。比如你反复让 AI 把 console.log 换成 logger.info,这背后就是一个"日志规范"的隐性知识。/skillify 会把这些隐性的纠正模式捕捉下来,变成显性的技能定义。
四轮采访流程
/skillify 的核心流程是一个结构化的四轮采访。不是自由聊天,而是用 AskUserQuestion 接口做的引导式问答。
Round 1:高层确认
目标:对齐技能的大方向。
- 技能叫什么名字?
- 一句话描述它的用途
- 目标是什么?
- 成功标准怎么定义?
这轮结束时,AI 和用户应该在"我们要做一个什么技能"这个问题上达成共识。看似简单的四个问题,其实是在建立技能的边界——名字和描述划定了功能范围,目标和成功标准定义了完成标准。没有这个边界,后续的细化工作容易跑偏。
Round 2:更多细节
目标:补充步骤和参数。
- 这个技能的步骤列表是什么?
- 需要哪些输入参数?
- 执行环境选择:
inline(在当前会话)还是fork(创建子 Agent)? - 保存位置:
repo(项目级.claude/skills/)还是personal(用户级~/.claude/skills/)?
inline 和 fork 的选择是一个关键设计决策。inline 模式在当前会话上下文中执行,适合需要访问当前会话状态的任务——比如"根据我们刚才讨论的架构来生成代码"。fork 模式创建一个独立的子 Agent,适合隔离性要求高的任务——比如"跑一遍完整的测试套件,不要影响当前工作"。
Round 3:逐步拆解
目标:把每个步骤的细节填满。
对于步骤列表中的每一步,/skillify 会追问:
- 这一步的产出是什么?
- 成功标准是什么?
- 需要人工检查点吗?
- 可以并行执行吗?
- 执行方式(脚本/手动/AI 判断)?
- 有没有硬约束?
这一轮是整个采访中信息密度很大的部分。通过逐个步骤的追问,确保技能的每一步都有明确的输入、输出和验证标准。源码中对每个步骤的追问项做了结构化的模板,不是随机聊天。
Round 4:最终确认
目标:生成 SKILL.md 并获得用户批准。
- 触发短语(用户说什么话时激活这个技能)
- 注意事项和边界情况
确认后,/skillify 生成完整的 SKILL.md 文件,保存在用户指定的位置。
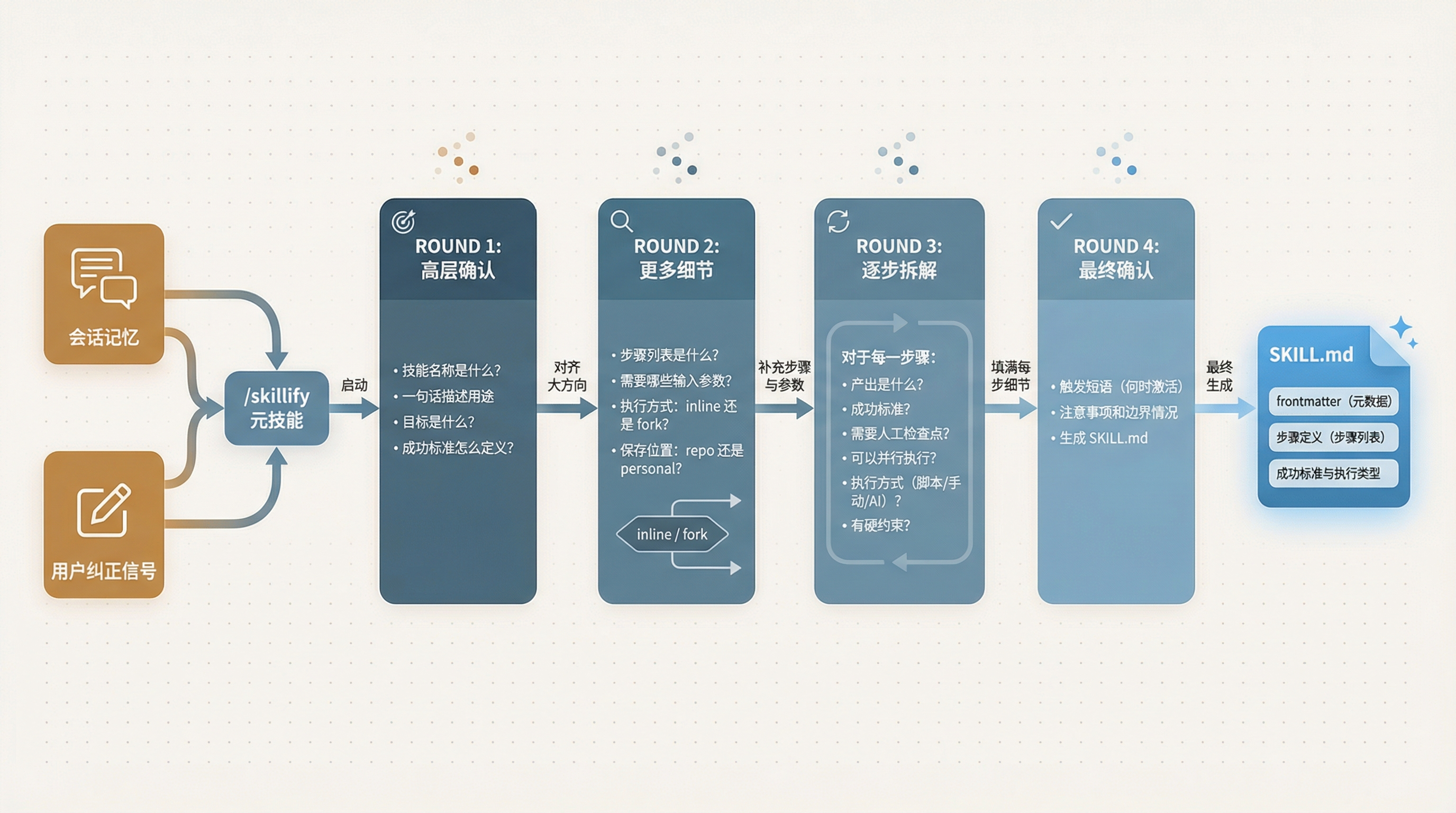
/skillify 四轮采访流程图
图 2:/skillify 四轮结构化采访流程——从双输入源到 SKILL.md 输出
为什么用 AskUserQuestion 而不是自由对话?
这是一个值得展开分析的设计选择。源码里用的是结构化的问答接口,而不是让 AI 自由聊天。
综合源码分析和社区讨论,我认为原因有三:
第一,控制对话走向。自由对话容易跑偏——AI 可能在第二步就开始讨论第七步的细节,或者在确认环节引入新的需求。结构化问答把每轮的边界划清楚。
第二,确保信息完整。每一轮都有明确的 checklist,不会因为聊天太顺畅而遗漏关键信息。技能的质量取决于输入信息的完整性——少一个步骤的成功标准,生成的技能就可能在实际执行中出问题。
第三,可预测的 token 消耗。四轮采访,每轮的问题数量是固定的,token 开销可控。自由对话的长度不可预测,在 CLI 环境下这是个实际问题——上下文窗口就那么大,聊天环节占了太多,留给实际执行的预算就少了。
SKILL.md 的格式设计
/skillify 最终生成的 SKILL.md 包含三个核心部分:
---
name: skill-name
description: 技能描述
whenToUse: 触发条件
context: inline | fork
---
# 步骤
## 步骤 1:[名称]
- 产出:...
- 成功标准:...
- 检查点:[是/否]
## 步骤 2:[名称]
...
# 成功标准
[整体成功标准]
# 执行类型
[inline/fork]知乎上有个讨论提到了一个容易被忽略的点:Skills 比 MCP 更节省 tokens。MCP 让每个工具描述都出现在 context 里,而 Skills 每个只占很少的索引空间,只有被激活的技能才加载完整内容。对于上下文窗口紧张的 CLI 场景,这个差别很关键。这也解释了为什么 Anthropic 要把 Skills 做成按需加载(懒提取)——不光是启动速度的考虑,也是运行时上下文预算的管理。
目前仅限内部使用
/skillify 目前只对 USER_TYPE === 'ant' 的用户开放,也就是 Anthropic 内部员工。从源码可以看到这个限制是硬编码的:
if (process.env.USER_TYPE !== 'ant') {
// 不注册 /skillify 技能
return;
}社区对这个限制有不少抱怨,但考虑到这个功能的实验性质和对 AI 理解能力的高要求,先在内部打磨再开放是合理的策略。从源码泄露到正式发布,中间通常还有一段距离。而且 /skillify 的质量高度依赖底层模型的理解能力——如果模型不能准确捕捉用户的纠正意图,生成的技能可能比手写的还差。Anthropic 内部使用 Claude 4.6 变体(代号 Capybara),理解能力可能和普通用户拿到的版本有差异。
3. /simplify:三个 Agent 同时审查你的代码
如果说 /skillify 展示了 AI 怎么学习你的工作流,那 /simplify 展示的是一个通用的多 Agent 并行模式。
src/skills/bundled/simplify.ts 只有 69 行,但设计思路清晰:一次 git diff,派出 3 个并行的 Agent,每个从不同视角审查代码。
三个 Agent 的分工
// 三个并行 Agent 的职责划分
Agent 1: 代码复用审查
- 搜索项目中已有的工具函数
- 标记重复逻辑("这段代码在 utils.ts 里已经存在")
Agent 2: 代码质量审查
- 冗余状态检测
- 参数膨胀标记
- 复制粘贴检测
- 泄漏抽象识别
- 字符串类型滥用
Agent 3: 效率审查
- 不必要的工作检测
- 错过的并发机会
- 热路径膨胀
- TOCTOU(Time of Check to Time of Use)问题
- 内存泄漏三个 Agent 覆盖了代码审查的三个核心维度:复用(不要重复造轮子)、质量(代码本身的健康度)、效率(运行时的性能表现)。
这个分工的设计有一个巧妙的考量:三个维度之间尽量不重叠。代码复用是一个独立的问题——你可能写了质量很好、效率也很高的代码,但碰巧项目里已经有了同样的功能。如果让一个 Agent 同时审查这三个维度,它可能会忽略这个"功能重复但实现优秀"的情况。三个 Agent 各管各的,反而能发现更多问题。
通用模式:同一输入,不同视角
/simplify 背后的设计模式值得提取出来,因为它不局限于代码审查:
同一个输入(git diff)
→ 分发给 N 个并行 Agent
→ 每个 Agent 聚焦一个维度
→ 汇总所有结果
→ 统一决策和修复这个模式可以复用到任何需要多维度评估的场景:安全审计(注入/XSS/权限/配置四个维度各自派出一个 Agent)、文档审查(准确性/完整性/可读性)、测试策略(单元/集成/E2E/性能)。关键约束是:维度之间要有清晰的边界,否则多个 Agent 会重复发现同一个问题,浪费上下文预算。
Phase 3:汇总修复的设计选择
源码中的 Phase 3 是一个值得注意的设计细节。它不是让三个 Agent 各自修复各自发现的问题,而是等所有 Agent 完成后统一修复。
为什么要这样?因为不同 Agent 发现的问题之间可能有依赖关系。比如 Agent 1 发现某段代码应该提取成工具函数,Agent 3 发现同一段代码有效率问题。如果各自修复,可能会产生冲突——Agent 1 把代码提取走了,Agent 3 修改的目标位置已经变了。
统一修复可以一次性解决所有问题,避免来回改动。这个设计选择背后是一个实用的工程判断:并行分析,串行修复。分析可以并行,因为分析之间互不影响;修复必须串行,因为修复之间可能有依赖。
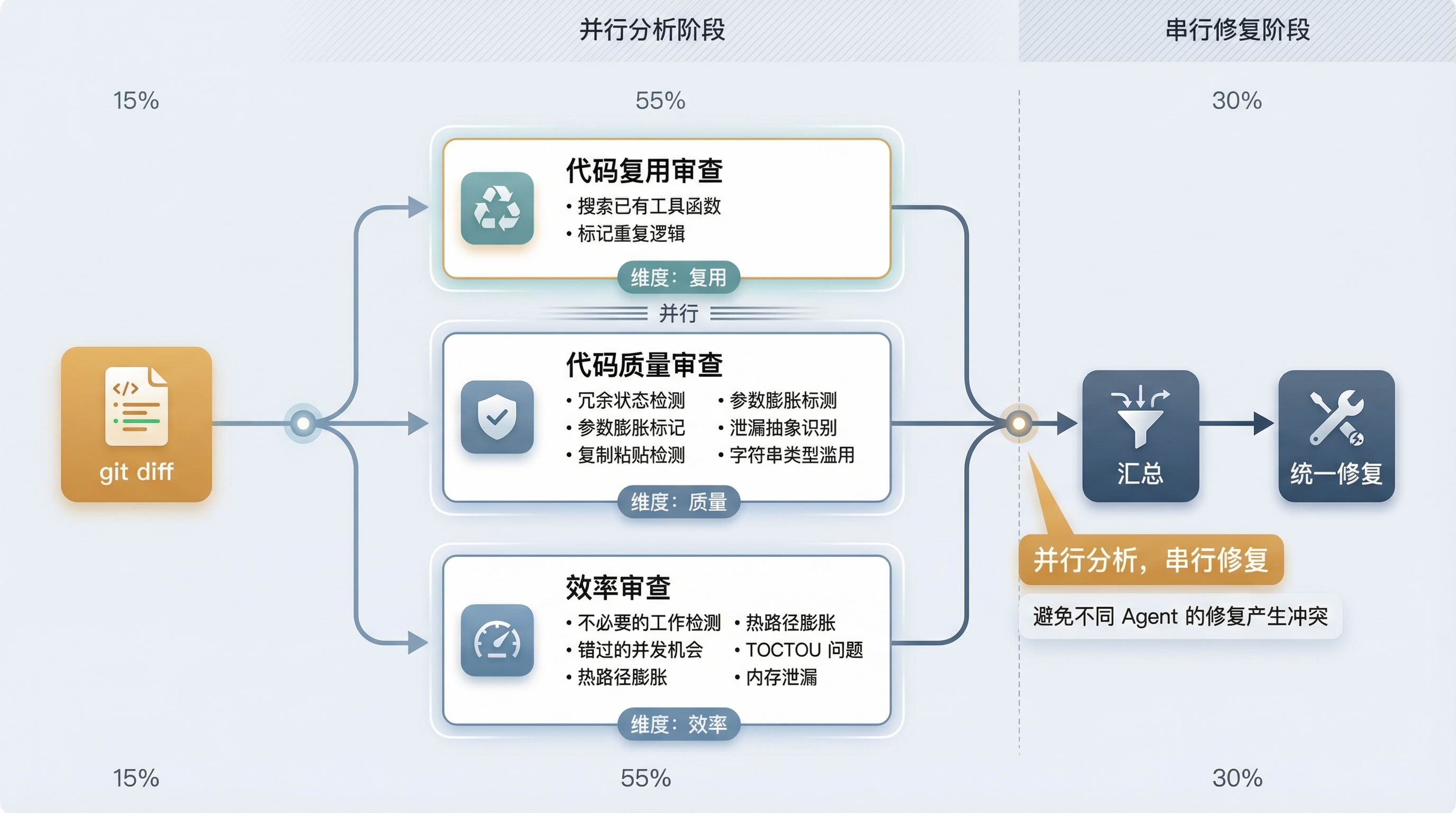
/simplify 三 Agent 并行审查架构图
图 3:/simplify 三 Agent 并行审查——并行分析、串行修复
你在项目中用过类似的多 Agent 并行方案吗?和单个 AI 做全面审查比,你觉得哪种方式更适合你的场景?欢迎在评论区聊聊你的经验。
4. /loop 和 /schedule:从单次执行到定时调度
从单次执行到定时调度,再到远程执行,Claude Code 的 Skills 系统在时间维度上做了三层扩展。
/loop:本地定时任务
src/skills/bundled/loop.ts(92 行)实现了一个本地的 cron 调度器。
默认间隔 10 分钟。间隔解析有三条优先规则:
1. 前缀 token(如 "every 5m")→ 优先级高
2. 尾部 "every" 子句(如 "check status every 30m")→ 优先级中
3. 默认值(10 分钟)→ 兜底它还内置了一个 cron 转换表,把 5m、1h、2d 这种人类可读的格式转换成标准 cron 表达式。这个转换表的逻辑虽然不复杂,但考虑了很多边界情况——比如 1d 要转成 0 0 * * *(每天零点),但零点恰好是惊群效应的高危时段。
惊群效应防护
源码里有一个工程细节让我印象深刻:避雷整点。
// 源码中的惊群效应防护(简化注释)
// 避开 :00 和 :30 整点(防惊群效应)
// 确定性抖动:recurring 任务最多延迟 10%什么是惊群效应(Thundering Herd)?想象一下,如果大量用户都设置"每小时执行一次",那所有任务都会在整点同时触发。服务器瞬间收到海量请求,可能造成拥塞甚至宕机。
Claude Code 的解决方案很巧妙:不让你在整点执行,而是加上一个确定性的抖动(deterministic jitter)。recurring 任务最多延迟 10% 的间隔时间。比如 10 分钟间隔的任务,实际执行时间可能在第 10-11 分钟之间。
"确定性"是关键——同一个任务每次的抖动是一样的。这样既避免了惊群,又保证了可预测性。如果你观察到某个任务在第 10 分 37 秒执行过一次,下次你可以合理预期它会在第 20 分 37 秒左右执行。
这种确定性抖动在分布式系统里是一个经典手法,Netflix 的 Polly 库、AWS 的 API 重试策略都用了类似的思路。但把它应用到 CLI 工具的本地定时任务里,说明 Anthropic 的工程师确实在考虑规模化的场景——即使每个用户只跑几个本地任务,乘以百万用户基数,整点问题就不是小事了。
两种持久化模式
/loop 支持两种模式:
模式 | 行为 | 适用场景 |
|---|---|---|
| 关闭会话后任务消失 | 临时性的重复操作 |
| 持久化到 | 长期运行的后台任务 |
还有一个贴心的细节:创建任务后立即执行一次,不用等第一个 cron 周期触发。这符合用户的心理预期——"我设了一个定时任务,当然想先看到它跑一次确认没问题"。
/schedule:远程 Agent 调度
如果说 /loop 是本地的小闹钟,那 /schedule 就是一个云端的自动化平台。
src/skills/bundled/scheduleRemoteAgents.ts(447 行,是所有技能文件里行数第二多的)实现了远程 Agent 调度,在 Anthropic 的 CCR(Cloud Container Runtime)云沙箱里运行。
完整的工作流包括:
1. 环境管理
每个远程 Agent 绑定一个 environment_id,可以挂载 MCP 连接器。这意味着远程 Agent 不只是跑一段代码,而是可以访问你的开发环境——数据库、API、文件系统,只要 MCP 连接器配置好了就能用。
环境 ID 的解析过程也值得注意。源码里用 Base58 解码 mcpsrv_ 前缀的 tagged ID,转换成 UUID。Base58 比 Base64 少了容易混淆的字符(0/O、l/I),在命令行环境里更不容易出错。
2. 调度设置
4 步创建流程:理解目标 → 编写 prompt → 设置调度 → 选择模型。最小间隔 1 小时(比 /loop 的粒度粗很多),这是合理的限制——云端资源比本地资源昂贵得多。
3. 时区处理
用户说"每天早上 9 点执行",系统需要把用户本地时间转换成 UTC cron 表达式。源码里处理了完整的时区转换逻辑。对于跨国团队来说,这个功能几乎是必需的——如果只能用 UTC 设时间,每个用户都得自己做时区换算。
4. CRUD 操作
支持 create、list、update、run,但没有 delete。这是一个有意思的设计省略——可能是出于安全审计的考虑,不允许删除历史调度记录。在合规要求严格的企业环境里,操作日志的不可篡改性是一个刚需。
从 /loop 到 /schedule 的演进路径
把 /loop 和 /schedule 放在一起看,能看到一条清晰的演进路径:
单次手动执行(/skillify 创建的技能)
→ 本地定时执行(/loop)
→ 远程定时执行(/schedule)
→ KAIROS 自主守护进程(未发布)每一层都在扩展 AI 的自主性:从"你让它做"到"它定时做"到"它在云端做"到"它自己决定做不做"。调研报告中提到的 AI 编程工具五阶段演进(补全 → 对话 → Agent → Skills → 自主 Agent),在这条路径上体现得很清楚。
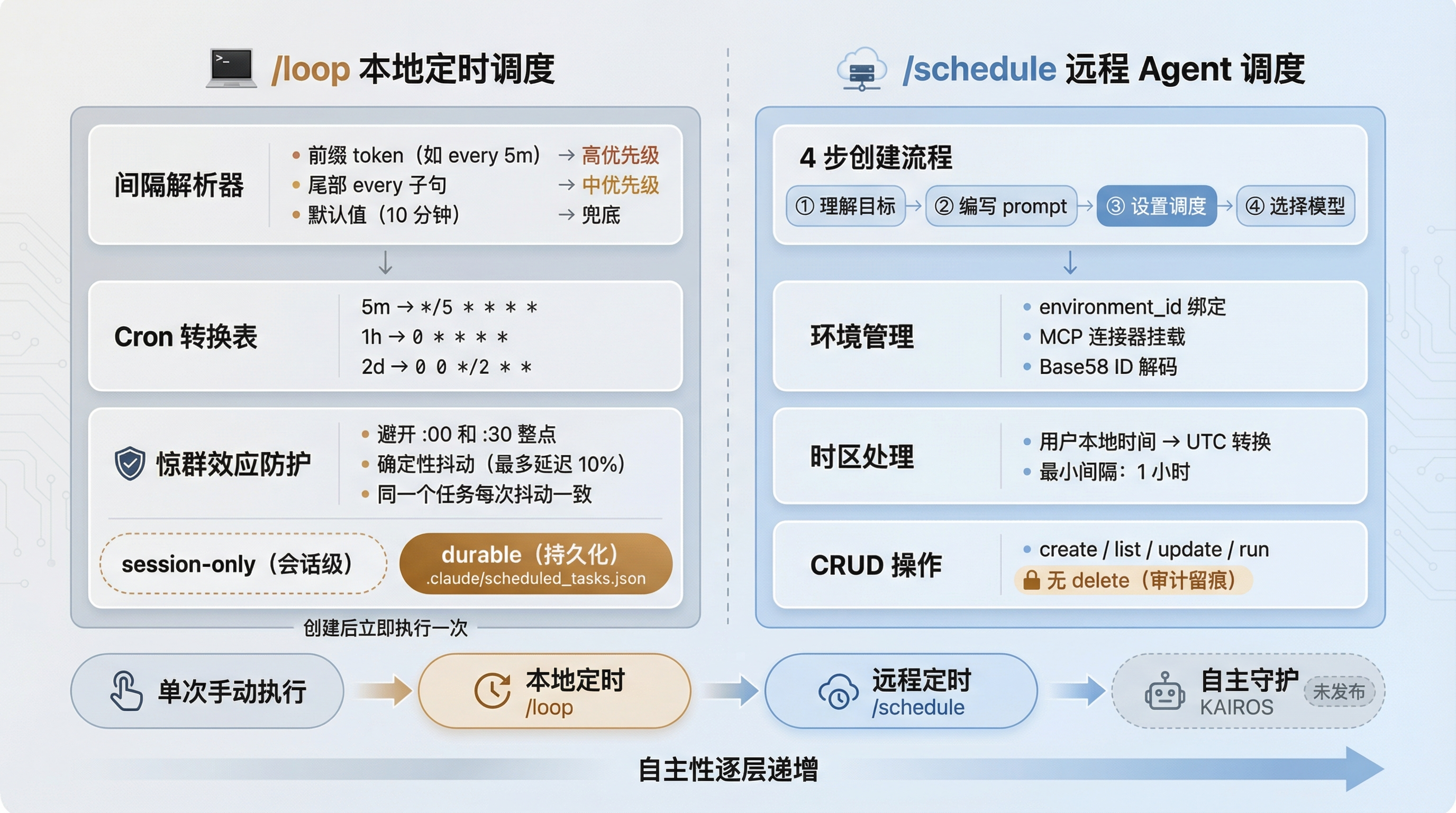
调度系统架构图 - /loop 本地调度 vs /schedule 远程调度
图 4:/loop 和 /schedule 调度系统对比——从本地定时到云端自主
5. 其他内置技能速览
除了上面重点拆解的几个技能,源码里还有几个值得提到的内置技能。每个都不复杂,但放在一起看,能感受到 Skills 系统覆盖面的广度。
/debug:调试日志分析
设计思路很实用:tail 读取近 64KB 日志,按级别分类(ERROR/WARN/INFO/DEBUG),定位关键错误。64KB 这个阈值应该是经验值——大到能覆盖常见问题的上下文,小到不会把整个上下文窗口撑满。适合快速排查"为什么突然报错了"这种场景。
/remember:跨层记忆审查
这个技能和 Claude Code 的三层记忆架构直接配合:
- auto-memory:AI 自动记录的会话笔记
- CLAUDE.md / CLAUDE.local.md:项目级和用户级的持久化记忆
- team memory:团队共享的记忆
/remember 做的是"记忆晋升"——把 auto-memory 里的内容,经过审查后晋升到 CLAUDE.md 或 team memory。这确保了只有经过验证的信息才进入长期记忆,避免 AI 的错误推断被固化。
从源码泄露的分析来看,Claude Code 的记忆系统有三层结构:MEMORY.md(轻量级索引,始终加载)、主题文件(按需获取)、原始转录(只通过 grep 检索特定标识符)。/remember 相当于在这三层之间做了一个"编辑"的角色——决定哪些临时记忆值得持久化。
/verify:代码变更验证
通过 Agent Hook 实现的代码变更验证。当代码发生变更时,自动触发验证流程,检查变更是否符合预期。源码里还包含了示例文件,展示怎么配置验证规则。
这个技能的价值在于它把"验证"变成了一个自动化步骤而不是手动检查。在 CI/CD 流程里,这种自动化是标准做法,但在日常编码中,很多开发者跳过了验证步骤——因为太麻烦了。把验证封装成一个技能,降低了执行成本。
/stuck:诊断冻结会话
专门用来诊断 Claude Code 自己卡死的情况。目前仅限内部用户。一个用来诊断自己卡死的技能——这个递归设计本身就挺有意思的。从工程角度看,这说明 Anthropic 内部确实遇到了会话卡死的问题,而且频率不低,否则不会专门做一个技能来处理。
6 种内置 Agent 类型
src/tools/AgentTool/built-in/ 目录下定义了 6 种 Agent:
Agent 类型 | 能力级别 | 典型用途 |
|---|---|---|
| 全工具访问 | 通用任务 |
| 只读搜索 | 代码探索、信息收集 |
| 只读分析 | 架构规划、方案设计 |
| 代码验证 | 变更检查、回归测试 |
| 帮助理解功能 | 新手引导、功能查询 |
| UI 设置 | 状态栏配置 |
权限递减的设计:general 可以做任何事,explore 和 plan 只能读不能写,verification 只能验证不能修改。这遵循了最小权限原则——每个 Agent 只拥有完成自己任务所需的最少权限。
从安全角度看,这个设计减少了 Agent 误操作的风险。一个只做代码探索的 Agent 不需要写文件的权限,给它了反而增加出错的可能。
团队协作:Team = TaskList
src/tools/TeamCreateTool/prompt.ts(113 行)实现了一套团队协作机制。核心映射关系是 Team = TaskList 的 1:1 对应。
工作流:创建团队 → 创建任务 → 生成队友 → 分配任务 → 自动消息传递 → 关闭团队。只读 Agent 做研究,全功能 Agent 做实现。
这套机制和 /simplify 的多 Agent 并行模式组合起来,就形成了一个完整的多 Agent 协作框架:/simplify 解决"同一时间多个 Agent 做同一件事的不同维度"的问题,Team 解决"同一时间多个 Agent 做不同任务"的问题。
总结:从 Skills 系统看 AI 编程工具的演进
翻完这些源码,回过头来看整个 Skills 系统,有几个趋势值得总结。
从被动响应到主动学习
传统的 AI 编程工具(包括早期的 Claude Code)是被动的:你问,它答。Cursor Rules 和 Windsurf Rules 虽然可以预设行为,但规则的编写、维护、更新全部依赖人工——规则过时了得手动改,新项目要重新写,团队协作还得同步规则文件。
Claude Code 的 Skills 系统,特别是 /skillify,代表了一个不同的方向:AI 主动观察你的工作模式,自动提炼成可复用的技能。从"用户写规则"到"AI 学规则",这是一个范式转变。
当然,现在 /skillify 还只在 Anthropic 内部使用,离普通用户还有距离。但方向已经明确了。
和竞品的客观对比
维度 | Claude Code Skills | Cursor Rules + Agent Skills | GitHub Copilot |
|---|---|---|---|
规则创建方式 | AI 自动学习(/skillify) | 人工编写 | 无此系统 |
文件格式 | SKILL.md(结构化) | .cursorrules + SKILL.md | - |
跨工具兼容 | OpenSkills 开放标准 | 兼容 Anthropic Skills 生态 | - |
多 Agent 支持 | 6 种内置类型 | 有限 | 无 |
定时调度 | /loop + /schedule | 无 | 无 |
远程执行 | CCR 云沙箱 | 无 | 无 |
一个有意思的发现是:Cursor 的 Agent Skills 系统兼容了 Anthropic 的 Skills 生态。通过 npm i -g openskills 安装 OpenSkills 工具后,Cursor 用户可以直接安装 Anthropic 官方提供的 Skills。即使在竞争关系中,开放标准的价值也被认可了。
Windsurf 被 Google 24 亿美元收购后,作为独立竞品已经退出。其技术基因融入了 Google 的 Antigravity 开发平台。GitHub Copilot 目前没有类似的 Skills/Rules 系统,在 Agentic 能力层面对比 Claude Code 和 Cursor 还有差距。
源码里的工程哲学
从这些源码中能看到 Anthropic 工程团队的几个设计原则:
安全默认(Secure by Default):0o700 权限、O_NOFOLLOW 防护、nonce 验证——每一个文件操作都有安全考量。这不是事后补丁,是设计时就考虑进去的。
渐进式复杂度:从简单的单次执行(/skillify 生成的技能)到本地定时(/loop)到远程调度(/schedule),每一层都在前一层的基础上扩展。用户可以按需选择合适的层级,不需要一上来就理解整个系统的复杂性。
最小权限原则:Agent 类型从 general 到 explore 到 verification,权限递减。每个 Agent 只能做自己职责范围内的事。
确定性优于随机性:惊群效应的抖动是确定性的,同一个任务每次的延迟一样。可预测的行为比随机行为更容易调试和监控。
AI 编程工具演进路径图
图 5:AI 编程工具五阶段演进路径——Skills 时代是当前的转折点
一个开放的问题
社区里有个共识越来越强:模型才是真正的护城河,CLI 工具架构不再是核心壁垒。Claude Code 的 ARR 已经达到 25 亿美元(据行业分析数据),80% 来自企业客户。但源码泄露后,韩国开发者 2 小时内就做出了 Python 重写版 claw-code(50,000 stars),Rust 版的 Kuberwastaken 也紧随其后。
这说明什么?工具层正在水平化。真正决定胜负的,是模型能力(Claude 4.6 vs GPT-4o vs Gemini)和生态系统(Skills 标准、MCP 协议、OpenSkills 工具)。
Skills 系统的开放标准策略,或许比任何一个具体功能都更有战略意义。如果 Cursor、Google、甚至 OpenAI 都兼容 SKILL.md 格式,那 Anthropic 就从"卖工具"变成了"定标准"——这个定位的变化,可能比任何一个功能更新都重要。
你觉得 Skills 标准会成为 AI 编程工具的通用格式吗?不同工具之间共享同一套技能生态,这是你期望看到的方向吗?欢迎在评论区说说你的判断。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号