大模型应用:大模型运行全流程解析:从初始化加载→计算→结果输出.69
原创
大模型应用:大模型运行全流程解析:从初始化加载→计算→结果输出.69
原创
未闻花名
发布于 2026-04-07 07:49:07
发布于 2026-04-07 07:49:07
一、引言
大模型的运行本质上是一条从静态存储到动态智能的完整技术链路。整个过程始于硬盘中保存的模型权重与配置文件,这些静态数据在启动时被加载至系统内存,并由CPU完成初步解析与组织。随后,模型的核心计算任务被调度至GPU,权重数据从内存迁移至显存,依托张量核心进行高速并行运算。这一硬件协作链条,“硬盘→CPU与内存→GPU与显存”构成了大模型高效推理的物理基础。在软件层面,系统依次执行配置解析、模型结构构建、权重加载、输入预处理、多层前向传播、注意力机制计算以及最终的文本解码等关键步骤。每一步都紧密衔接,确保从原始输入到自然语言输出的流畅转换。尤其在生成阶段,自回归解码机制逐字预测,结合采样策略与后处理规则,将高维向量转化为人类可读、语义连贯的文本结果。
为深入理解这一流程,我们可通过可视化手段呈现计算图结构、显存占用变化、各层耗时分布及注意力权重热力图,从而直观把握模型运行的内在逻辑与性能瓶颈。整体而言,大模型的运行不仅是算法的胜利,更是软硬件协同设计的典范,它将冰冷的数字权重激活为有温度的智能交互,背后依赖的是精密的工程架构与对底层资源的极致调度。掌握这一全流程机制,是优化推理效率、定制部署方案以及推动大模型落地应用的关键前提。

二、大模型运行核心流程
1. 数据流转路径
大模型的完整运行流程可分为三大核心阶段,各阶段环环相扣,数据流转路径为:

1.1 硬盘(静态配置/权重文件)
- 存储预训练的大模型权重文件,通常为几十GB至几百GB
- 存储配置文件,包括模型架构、超参数、词汇表等
- 格式通常为Safetensors、PyTorch的.pt/.pth、TensorFlow的.ckpt
核心要点:
- 通常使用SSD/NVMe存储以加快读取速度;
- 模型权重在推理前一次性加载到内存;
- 量化版本(INT8/INT4)可大幅减少文件大小
1.2 内存(预处理/重组)
- 从硬盘加载完整的模型权重到系统内存
- 对输入文本进行预处理:分词、编码、填充
- 数据格式转换和批处理重组
处理步骤:
- 1. 分词编码:将输入文本通过 tokenizer 切分为子词或词元,并映射为对应的 Token ID 序列,作为模型可处理的数值化输入。
- 2. 序列填充:为保证批量计算效率,将不同长度的序列统一填充(padding)至相同长度,通常在末尾添加特殊填充 token,并配合 attention mask 避免干扰。
- 3. 批处理:将多个独立请求的 Token 序列拼接成一个批次(batch),一次性送入模型,充分利用 GPU 并行计算能力,显著提升吞吐量。
- 4. 权重重组:在加载模型权重后,按实际计算图或硬件优化需求(如 Tensor Core 对齐、算子融合)对权重张量进行转置、分块或内存布局调整,以提升访存效率与计算性能。
1.3 显存(计算就绪)
- 存储计算所需的权重、输入数据、KV缓存
- 作为GPU直接访问的高速缓冲区
内存分配:
- 权重区域:存储模型全部参数,通常以FP16或INT8等压缩格式加载至显存,是推理计算的基础,占用显存的主要部分。
- KV缓存区:在自回归生成过程中,为避免重复计算历史token的键(Key)和值(Value),将其缓存于此区域,显著加速后续token的注意力计算,但随序列长度线性增长。
- 工作缓冲区:用于存放前向传播中的中间激活值、临时张量及算子计算所需的暂存空间,其大小取决于模型层数、批处理规模和序列长度。
- 输入/输出区:存放当前待处理的输入token序列及正在生成的输出结果,作为数据在CPU与GPU之间或模型各阶段间传递的接口,通常体积较小但访问频繁。
1.4 GPU(并行计算)
- 执行模型的前向传播计算
- 使用张量核心加速矩阵运算
计算阶段:
- 首先,输入嵌入将用户提供的文本(如“你好”)通过词表映射为高维向量,并叠加位置编码以保留序列顺序信息;
- 接着,这些向量依次通过多层Transformer结构,每层包含自注意力机制(捕捉词与词之间的全局依赖关系)和前馈神经网络(进行非线性特征变换),逐层提炼语义表示;
- 随后,输出投影将最后一层的隐藏状态映射回词表维度,生成每个可能词汇的原始得分(logits);
- 最后,采样模块依据这些得分,结合温度调节、top-k 或 top-p 等策略,从概率分布中选择下一个词元,逐步生成连贯、合理的自然语言输出。
这一链条实现了从符号到语义、再到新符号的智能转换,是大模型生成能力的核心路径。
1.5 内存(解码/后处理)
- 从GPU获取输出的logits或已生成的token ID;
- 根据设定策略(如贪婪搜索、集束搜索或带温度的随机采样)选择下一个token;
- 对最终token序列进行后处理(去特殊符号、修复空格等)并解码为可读文本。
解码过程:
- Logits处理:模型输出的原始logits首先经过softmax函数转换为概率分布,使每个词元对应一个归一化的生成概率;为进一步提升生成质量与多样性,通常结合top-k(仅保留概率最高的k个候选)或top-p(累积概率不超过p的最小词集)策略进行动态筛选,有效抑制低质量或无关词汇的采样。
- 采样选择:在筛选后的候选集合中,依据指定策略(如贪婪搜索、随机采样、束搜索或带温度调节的采样)选择下一个token;温度参数可控制输出的随机性,高温增加多样性,低温趋向确定性,从而在创造性与稳定性之间取得平衡。
- 重复检测:为避免模型陷入重复循环,如不断输出相同短语,系统会引入重复惩罚机制,例如降低已生成n-gram词组的logits分数,或直接禁止近期出现过的token再次被选中,确保输出内容流畅且富有变化。
- 停止判断:生成过程持续进行,直到满足任一终止条件,要么模型输出预设的结束符(EOS token),表示语义完整;要么达到预设的最大生成长度,防止无限延续。此时,系统将最终token序列解码为自然语言文本并返回结果。
1.6 用户(自然语言结果)
- 输出完整生成的文本序列
- 可能包含多个候选结果(集束搜索)
- 生成概率和置信度分数
格式转换:
- 模型生成的Token ID序列首先通过词汇表(tokenizer的解码映射)转换为对应的子词或单词,形成原始文本字符串;
- 随后,该字符串经过后处理(如去除特殊符号、合并空格、还原标点等)
- 最终格式化为符合人类阅读习惯的自然语言输出。
2. 整体运行流程
阶段 | 核心目标 | 主导硬件 | 关键产出 |
|---|---|---|---|
初始化加载 | 将静态模型文件转化为 GPU 显存中可运行的就绪模型 | CPU + 内存、GPU + 显存、硬盘 | 显存中就绪的模型权重、预分配的 KV 缓存区 |
运行计算 | 基于用户输入,通过 GPU 并行计算生成 Token ID 序列 | GPU 核心、显存 | 机器可识别的 Token ID 序列 |
输出结果 | 将 Token ID 序列转化为人类可理解的自然语言文本 | CPU + 内存 | 最终自然语言结果、释放硬件资源 |
2.1 阶段 1:模型初始化加载(硬盘→显存就绪)
模型初始化加载是将硬盘上的静态文件转化为 GPU 显存中"可计算就绪模型"的过程,核心分为 6 个关键步骤,是后续运行计算的基础。
2.1.1 步骤 1:环境初始化 & 模型配置解析
- 核心目标:搭建运行环境,解析模型的配置参数文件(config.json)。
- 具体操作:
- 1. 校验 Python/框架/CUDA 版本兼容性,初始化运行上下文;
- 2. 读取并解析 config.json,提取模型结构(层数、维度)、运行规则(精度、Token ID)等核心参数。
- 硬件依赖:CPU + 少量内存。
关键参数示例(config.json 片段):
{
"model_type": "llama",
"num_hidden_layers": 32,
"hidden_size": 4096,
"vocab_size": 32000,
"bos_token_id": 1,
"eos_token_id": 2,
"use_cache": true
}2.1.2 步骤 2:词表文件加载 & 词典初始化
- 核心目标:构建模型与自然语言的 “翻译字典”。
- 具体操作:
- 1. 读取 vocab.txt/tokenizer.json,加载 Token 与 ID 的映射关系;
- 2. 在内存中构建双向字典(Token→ID、ID→Token),初始化分词器。
- 硬件依赖:CPU + 内存(占用几十 MB)。
2.1.3 步骤 3:权重文件定位 & 完整性校验
- 核心目标:确保核心权重文件完整可用,避免加载中断。
- 具体操作:
- 1. 定位分片/单文件权重(.bin/.pth),生成文件清单;
- 2. 校验文件存在性、大小、哈希值。
- 硬件依赖:硬盘 + CPU。
2.1.4 步骤 4:权重文件分片读取 & 内存缓冲区缓存
- 核心目标:将静态权重文件转化为内存中的结构化张量。
- 具体操作:
- 1. 预分配内存缓冲区(1-2 个分片大小),采用 FIFO 策略;
- 2. 按顺序读取分片文件,写入缓冲区并解析为张量,过滤无用数据。
- 硬件依赖:硬盘(高速读写) + CPU + 内存,占用几GB。
2.1.5 步骤 5:内存中权重分片重组 & 精度优化
- 核心目标:构建完整模型并压缩精度,减少显存占用。
- 具体操作:
- 1. 按模型结构拼接分片张量,生成完整权重;
- 2. 将 FP32 权重压缩为 FP16(体积减半)或 INT8(体积缩至 1/4)。
- 硬件依赖:CPU + 内存,占用十几GB。
2.1.6 步骤 6:模型权重迁移至显存 & GPU 就绪初始化
- 核心目标:将优化后的模型迁移到 GPU 显存,完成最终就绪。
- 具体操作:
- 1. 在显存中预分配权重区、KV 缓存区、中间结果区;
- 2. 通过 PCIe 接口将内存权重迁移至显存,初始化 GPU 计算图;
- 3. 校验显存中模型维度,确认就绪。
- 硬件依赖:CPU + GPU + 显存(占用几 GB 到几十 GB)。
2.1.7 初始化加载阶段可视化
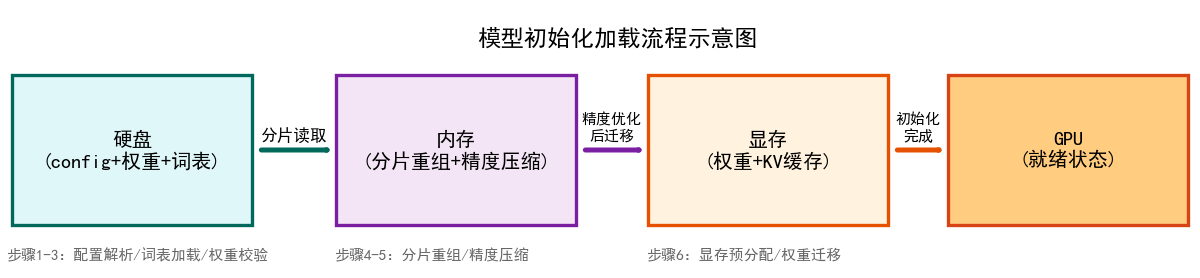
- 左侧为硬盘模块,标注核心文件类型;
- 中间内存模块展示分片重组和精度压缩核心操作;
- 右侧显存 + GPU 模块标识最终就绪状态;
- 箭头标注数据流转方向和关键操作,直观展示初始化加载的核心路径。
2.2 阶段 2:模型运行计算(显存→Token ID 序列)
模型已完成初始化加载,GPU 显存中存储着完整的模型权重、预分配的 KV 缓存区,此时处于 “就绪状态”,等待接收输入。整个运行计算过程是逐 Token 生成的循环过程,大模型采用 “自回归生成” 逻辑,核心分为输入就绪、单次前向传播、KV 缓存更新、生成循环终止4 个步骤。
2.2.1 步骤 1:输入数据最终预处理 & 迁移至显存(CPU+GPU 协作,准备计算原料)
- 核心目标:将用户输入转化为 GPU 可计算的张量格式。
- 具体操作:
- 1. 用户输入自然语言接收
- 程序接收用户的输入内容(比如 “介绍大模型运行流程”),同时可接收附加配置(比如生成最大长度 512Token、温度 0.7)。
- 2. 自然语言→Token ID 转化
- 调用初始化加载阶段已驻留内存的分词器(Tokenizer)和“Token→ID 字典”,对用户输入进行分词处理:
- 先按模型的分词规则,将完整句子拆分为一个个独立的 Token(比如 “介绍大模型运行流程”→ 拆分为 “介绍”“大”“模型”“运行”“流程” 等,部分模型会拆分为子词)。
- 再将每个 Token 映射为对应的整数 ID(比如 “介绍”→1234,“模型”→5678),形成一维的 Token ID 序列。
- 调用初始化加载阶段已驻留内存的分词器(Tokenizer)和“Token→ID 字典”,对用户输入进行分词处理:
- 3. 输入序列标准化处理
- 给 Token ID 序列添加特殊标记,确保模型能识别序列的起止和角色:
- 头部添加“bos_token_id”(句子开始标记,比如 ID=1),标识输入的开始。
- 若为对话模型,还会添加系统提示词对应的 Token ID、用户角色标记 ID 等(按
chat_template配置)。 - 尾部暂不添加“eos_token_id”(句子结束标记),留待生成完成后补充。
- 检查序列长度,若超过模型支持的max_position_embeddings(比如 2048),则进行截断处理,避免报错。
- 给 Token ID 序列添加特殊标记,确保模型能识别序列的起止和角色:
- 4. Token ID 序列→张量(Tensor)转化 & 显存迁移
- 将标准化后的 Token ID 序列,转化为深度学习框架可识别的张量数据结构(形状通常为[1, seq_len],1 表示批次大小,seq_len 表示输入序列长度)。
- 通过 PCIe 接口,将该张量迁移到 GPU 显存的IO 缓冲区,供 GPU 核心读取计算。同时,将生成配置(最大长度、温度等)也传入 GPU,作为计算约束条件。
- 1. 用户输入自然语言接收
- 硬件依赖:
- 主导硬件:CPU(分词、格式标准化)、GPU(接收张量数据)、内存(存储分词器和字典)、显存(存储输入张量,占用少量空间)。
- 耗时特点:耗时极短(毫秒级),远低于后续的循环计算。
2.2.2 步骤 2:单次前向传播计算(GPU 核心主导,核心是 “生成下一个 Token ID”)
- 核心目标:基于上下文生成下一个 Token ID 的概率分布并采样。
- 具体操作
- 1. 数据读取:显存→GPU 核心
- GPU 核心(SM 并行计算单元)从显存中读取 3 类核心数据:
- 模型权重区:完整的 FP16 模型权重(神经网络骨架)。
- IO 缓冲区:当前的 Token ID 张量(初始为用户输入的序列,后续为循环生成的序列)。
- KV 缓存区:第一轮循环时为空,后续循环为已生成 Token 对应的注意力缓存数据。
- GPU 核心(SM 并行计算单元)从显存中读取 3 类核心数据:
- 2. 位置编码添加
- 模型无法直接识别 Token 的顺序,因此需要给每个 Token ID 添加位置编码,标识其在序列中的位置:
- 常见的位置编码方式有RoPE(旋转位置编码)(Llama 系列)、Sinusoidal(正弦余弦位置编码)。
- 计算过程在 GPU 核心中完成,将位置信息嵌入到 Token 的特征向量中,确保模型能理解上下文的先后关系。
- 模型无法直接识别 Token 的顺序,因此需要给每个 Token ID 添加位置编码,标识其在序列中的位置:
- 3. 多头注意力机制计算
- 这是模型 “理解上下文” 的核心步骤,GPU 会并行计算多头注意力,核心逻辑是 “让每个 Token 都能关注到序列中其他 Token 的信息”:
- 第一步:将 Token 的特征向量拆分为"查询向量(Q)、"键向量(K)"、"值向量(V)",并按注意力头数进行拆分(比如 32 头,就将向量拆分为 32 份)。
- 第二步:计算 Q 与 K 的相似度(点积运算),得到注意力得分矩阵,反映每个 Token 对其他 Token 的关注程度。
- 第三步:对注意力得分矩阵进行归一化处理(除以缩放因子),再通过 Softmax 函数转化为 0-1 之间的概率分布(注意力权重)。
- 第四步:将注意力权重与 V 向量相乘,加权求和后,拼接所有注意力头的结果,得到注意力层的输出特征向量。
- 关键优化:利用KV 缓存,本轮计算只需要生成新 Token 的 Q 向量,K、V 向量直接复用前一轮缓存的结果,无需重新计算所有前文,大幅提升效率(对应config.json中的use_cache: true)。
- 这是模型 “理解上下文” 的核心步骤,GPU 会并行计算多头注意力,核心逻辑是 “让每个 Token 都能关注到序列中其他 Token 的信息”:
- 4. 前馈网络(FFN)计算
- 对注意力层的输出进行进一步的非线性变换,提取更复杂的特征:
- 第一步:通过全连接层,将特征向量从 hidden_size(比如 4096)映射到intermediate_size(比如 11008),并通过激活函数(比如 Silu)引入非线性。
- 第二步:再通过另一个全连接层,将特征向量映射回hidden_size,得到前馈网络的输出。
- 对注意力层的输出进行进一步的非线性变换,提取更复杂的特征:
- 5. 层归一化 & 残差连接
- 对前馈网络的输出进行层归一化处理,调整特征向量的分布,防止梯度消失或爆炸,保证数值稳定性(依赖config.json中的layer_norm_eps参数)。
- 引入残差连接,将当前层的输入与输出相加,保留原始特征信息,帮助模型训练和推理时的梯度传递(即使深层网络也能稳定运行)。
- 6. 输出层计算:Token 概率分布生成
- 经过所有 Transformer 层的计算后,通过最终的全连接层(输出层),将特征向量映射到vocab_size(比如 32000)维度,得到每个 Token 的原始得分(logits)。
- 通过 Softmax 函数,将原始得分转化为 0-1 之间的概率分布,每个数值对应一个 Token ID 的生成概率(概率总和为 1)。
- 7. 采样:从概率分布中选择下一个 Token ID
- 不是直接选择概率最高的 Token ID(易生成重复、僵硬的内容),而是通过「采样策略」选择,核心受温度(temperature)影响:
- 温度 = 0:贪心采样,直接选择概率最高的 Token ID,生成结果最严谨,但多样性不足。
- 温度 = 0.7(默认):适度采样,降低高概率 Token 的优势,提升低概率 Token 的选中概率,平衡严谨性和多样性。
- 温度 > 1:生成结果更具多样性,但容易出现逻辑混乱、无意义的内容。
- 采样得到一个新的 Token ID,这是本轮前向传播的唯一输出结果。
- 不是直接选择概率最高的 Token ID(易生成重复、僵硬的内容),而是通过「采样策略」选择,核心受温度(temperature)影响:
- 1. 数据读取:显存→GPU 核心
- 硬件依赖:
- 主导硬件:GPU 核心(SM 单元)(并行计算,决定生成速度)、显存(存储权重、缓存、中间结果,占用峰值空间)。
- 耗时特点:每一轮单次前向传播耗时固定(毫秒级),取决于 GPU 性能,比如高性能 GPU 每秒可生成几十到上百个 Token。
- 关键优化:KV 缓存、并行计算、FP16 精度,这三者是提升单次计算效率的核心。
2.2.3 步骤 3:KV 缓存更新 & 生成序列拼接(GPU + 显存协作,为下一轮循环做准备)
- 核心目标:每生成一个新的 Token ID,都要更新缓存和序列,确保下一轮循环能基于完整的上下文进行计算。
- 具体操作:
- 1. 新 Token 的 K/V 向量缓存
- 将本轮前向传播中,新生成 Token 对应的键向量(K)和值向量(V),写入显存的KV 缓存区,按序列顺序追加存储,不覆盖原有缓存数据。
- KV 缓存区会动态扩展,但不超过初始化加载时预分配的最大空间,若接近上限,会触发缓存裁剪(优先丢弃最早的 Token 缓存)。
- 2. 新Token ID与原有序列拼接
- 将本轮采样得到的新 Token ID,拼接至原有 Token ID 张量的尾部,形成新的、更长的 Token ID 序列(形状变为[1, seq_len+1])。
- 新序列仍存储在显存的IO 缓冲区,作为下一轮前向传播的输入。
- 3. 中间结果校验
- 简单校验新序列的长度,确保未超过用户配置的最大生成长度,同时检查新 Token ID 是否为eos_token_id(句子结束标记)。
- 1. 新 Token 的 K/V 向量缓存
- 硬件依赖:
- 主导硬件:GPU(缓存写入、序列拼接)、显存(存储扩展后的缓存和序列)。
- 耗时特点:耗时极短(微秒级),几乎不影响整体生成效率。
2.2.4 步骤 4:生成循环终止(CPU+GPU 协作,停止计算并准备输出)
- 核心目标:单次前向传播→KV 缓存更新是一个循环,会持续进行,直到满足终止条件,停止运行计算。
- 具体操作:
- 1. 终止条件判断(每轮循环后执行)
- 程序会检查 3 个终止条件,满足任意一个即停止循环:
- 条件 1:生成的 Token ID 序列长度达到用户配置的最大长度(比如 512Token)。
- 条件 2:新生成的 Token ID 为“eos_token_id”(句子结束标记,比如 ID=2),标识模型已完成内容生成。
- 条件 3:生成过程中出现错误,如显存不足、计算溢出,强制终止循环。
- 程序会检查 3 个终止条件,满足任意一个即停止循环:
- 2. 循环终止后的预处理
- 停止 GPU 的前向传播计算,冻结显存中的最终 Token ID 序列和KV 缓存区,防止数据被篡改。
- 将最终 Token ID 序列从显存的IO 缓冲区迁移回内存,同时保留少量关键中间结果用于后续异常排查。
- 此时,运行计算阶段完成,内存中存储着完整的、机器可识别的 Token ID 序列,无人类可理解的内容,等待进入输出结果阶段。
- 1. 终止条件判断(每轮循环后执行)
- 硬件依赖:
- 主导硬件:CPU(条件判断、流程调度)、GPU(停止计算、数据迁移)、内存(存储最终 Token ID 序列)。
- 耗时特点:循环终止的总耗时 = 循环次数 × 单次前向传播耗时,比如生成 500 个 Token,每次耗时 20 毫秒,总耗时约 10 秒。
- 常见结果:最终 Token ID 序列包含用户输入对应的 Token ID和模型生成对应的 Token ID,尾部通常带有eos_token_id。
2.2.5 运行计算阶段可视化图
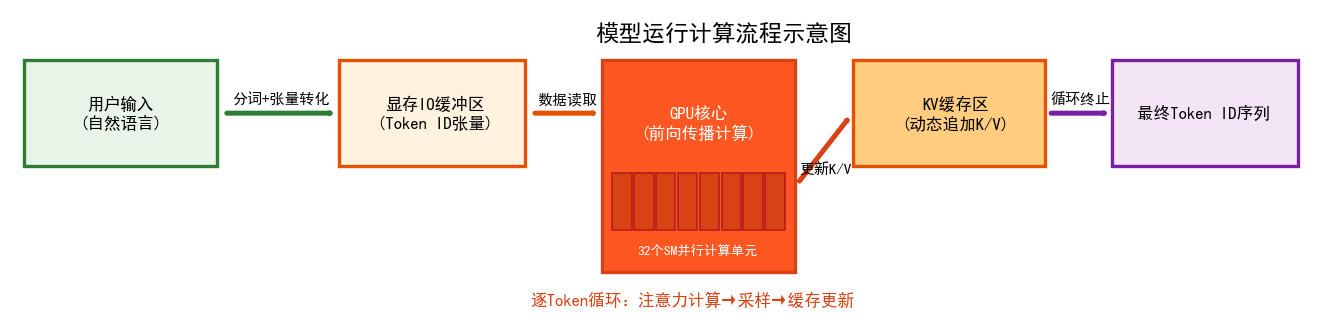
- 左侧展示用户输入到显存 IO 缓冲区的转化过程;
- 中间 GPU 核心模块标注并行计算单元和核心操作;
- 右侧 KV 缓存区展示动态追加逻辑,最终输出 Token ID 序列;
- 标注 “逐 Token 循环” 核心逻辑,体现自回归生成的特点。
2.3 阶段 3:模型输出结果的完整过程(CPU 主导,核心是 “Token ID→自然语言”)
这一阶段承接运行计算阶段的最终 Token ID 序列,核心是将 “机器语言” 转化为 “人类可理解的自然语言”,同时释放所有占用的硬件资源,避免资源泄露,全程以 CPU 为主导,几乎不占用 GPU 资源。
2.3.1 步骤 1:最终 Token ID 序列预处理(CPU + 内存主导,清理无效数据)
- 核心目标:内存中的 Token ID 序列包含一些无效或多余数据,需要先清理,确保后续解码的准确性。
- 具体操作:
- 1. 无效 Token ID 过滤
- 过滤掉序列中的特殊标记(除了必要的分隔符):
- 移除头部的句子开始标记bos_token_id,该标记仅用于模型计算,无需展示给用户。
- 移除尾部的句子结束标记eos_token_id,该标记标识生成完成,无实际语义。
- 若为对话模型,还会移除系统提示词、角色标记对应的 Token ID,只保留模型生成的核心内容对应的 Token ID。
- 过滤掉序列中的特殊标记(除了必要的分隔符):
- 2. 序列截断与修复
- 若因达到最大生成长度而终止循环,序列尾部可能无完整语义,可选择性进行截断,比如截断到最近的标点符号后。
- 检查序列中是否存在无效 Token ID,比如超出vocab_size的ID,若有则进行修复或删除,避免解码报错。
- 3. Token ID 序列整理
- 将清理后的 Token ID 序列,整理为一维的纯整数数组,方便后续调用「ID→Token 字典」进行解码。
- 1. 无效 Token ID 过滤
- 硬件依赖:
- 主导硬件:CPU(数据过滤、整理)、内存(存储清理后的 Token ID 序列)。
- 耗时特点:耗时极短(毫秒级),几乎可忽略。
2.3.2 步骤 2:Token ID→自然语言解码(CPU + 内存主导,核心是 “反向映射”)
- 核心目标:这是输出结果阶段的核心步骤,通过反向映射,将机器可识别的 Token ID 序列,转化为人类可理解的自然语言文本。
- 具体操作:
- 1. 调用 ID→Token 字典进行反向映射
- 遍历清理后的 Token ID 序列,逐个读取每个 Token ID,调用初始化加载阶段已驻留内存的“ID→Token 字典”,将其映射为对应的 Token(文字/子词):
- 比如 Token ID=1234→“介绍”,Token ID=5678→“模型”。
- 若为子词分词模型(比如 GPT、Llama),部分 Token 会以 “##” 开头,表示该子词需与前一个子词拼接,此时会自动去除 “##”,并与前一个 Token 拼接为完整词语,比如 “## 型”→ 与前一个 “模” 拼接为 “模型”。
- 遍历清理后的 Token ID 序列,逐个读取每个 Token ID,调用初始化加载阶段已驻留内存的“ID→Token 字典”,将其映射为对应的 Token(文字/子词):
- 2. Token 序列→完整文本拼接
- 将所有映射后的 Token,按序列顺序拼接为一个完整的字符串,形成初步的自然语言文本。
- 进行简单的格式优化,比如补充缺失的标点符号、调整换行符、去除多余的空格,提升文本的可读性。
- 3. 文本内容校验与优化
- 针对生成的文本,进行可选的后处理优化:
- 逻辑校验:简单检查文本是否存在明显的逻辑混乱,比如前后矛盾、语句不通,若有则进行标记或简单修正。
- 格式标准化:若用户要求特定格式(比如 Markdown、JSON),则将文本转化为对应格式。
- 敏感信息过滤:过滤文本中的敏感词汇、违规内容,确保输出内容合规。
- 此时,得到最终的、可直接展示给用户的自然语言文本结果。
- 针对生成的文本,进行可选的后处理优化:
- 1. 调用 ID→Token 字典进行反向映射
- 硬件依赖:
- 主导硬件:CPU(反向映射、文本拼接、格式优化)、内存(存储字典、Token 序列、最终文本)。
- 耗时特点:耗时极短(毫秒级),远低于运行计算阶段。
- 关键注意点:解码的准确性依赖“ID→Token 字典”的完整性,若字典缺失对应映射,会出现 “未知 Token” 标记,比如
<unk>。
2.3.3 步骤 3:结果输出与缓存(CPU + 存储主导,交付用户并留存备份)
- 核心目标:将最终的自然语言文本交付给用户,同时可选择留存备份,方便用户后续查看或复用。
- 具体操作:
- 1. 多渠道结果输出
- 按照用户的配置,将最终文本输出到指定载体,常见输出渠道包括:
- 终端/命令行:直接打印文本结果,供本地运行时查看。
- 网页/API 接口:将文本封装为 JSON 格式(比如 {"result": "xxx"}),返回给调用方(如前端网页、第三方应用)。
- 文件:将文本写入本地txt或md文件,存储在指定目录,供用户后续打开查看。
- 按照用户的配置,将最终文本输出到指定载体,常见输出渠道包括:
- 2. 结果缓存与日志记录
- 可选将最终结果、生成配置、耗时信息等,写入日志文件或数据库,进行缓存留存:
- 方便用户后续查询历史生成结果,无需重新运行模型。
- 便于开发者排查问题、优化模型生成效果。
- 缓存的结果通常会附带时间戳、模型版本、输入内容等元信息,方便后续筛选和管理。
- 可选将最终结果、生成配置、耗时信息等,写入日志文件或数据库,进行缓存留存:
- 1. 多渠道结果输出
- 硬件依赖:
- 主导硬件:CPU(输出调度、格式封装)、存储(硬盘)(写入文件、数据库,可选)。
- 耗时特点:取决于输出渠道,本地终端输出耗时极短,写入大文件或远程数据库耗时稍长(秒级)。
2.3.4 步骤 4:硬件资源全面释放(CPU+GPU 主导,避免资源泄露)
- 核心目标:结果输出完成后,程序会自动释放本次运行过程中占用的所有硬件资源,为后续模型运行或其他程序提供可用资源,这是容易被忽略但至关重要的步骤。
- 具体操作:
- 1. 显存资源释放
- 程序向 GPU 发送资源释放指令,按 “从易到难” 的顺序释放显存资源:
- 第一步:释放KV缓存区的所有数据,这是临时缓存,无需留存。
- 第二步:释放IO 缓冲区的输入/输出张量数据、中间结果区的临时计算结果。
- 第三步:可选释放模型权重区的模型权重数据:
- 若用户后续还需频繁运行模型,可保留权重数据,让模型保持 “就绪状态”,下次运行可跳过初始化加载阶段,大幅提升启动速度。
- 若用户后续暂无运行需求,可完全释放权重数据,将显存占用恢复到模型运行前的初始状态。
- 释放完成后,GPU 显存占用会大幅下降(比如从 10.4GB 降至 2.2GB),GPU 恢复到空闲状态。
- 程序向 GPU 发送资源释放指令,按 “从易到难” 的顺序释放显存资源:
- 2. 内存资源释放
- 释放内存中本次运行相关的所有数据,保留长期驻留的配置信息(如分词器、字典,若模型进程未关闭):
- 第一步:释放最终 Token ID 序列、Token 序列、自然语言文本等临时数据。
- 第二步:释放显存迁移回内存的中间结果、缓存数据。
- 第三步:若模型进程关闭,释放分词器、字典、配置字典等所有数据。
- 释放完成后,内存占用会大幅下降(比如从 10GB 降至 2GB),内存恢复到空闲状态。
- 释放内存中本次运行相关的所有数据,保留长期驻留的配置信息(如分词器、字典,若模型进程未关闭):
- 3. CPU 与其他资源释放
- 关闭本次运行相关的临时进程、线程,释放 CPU 的调度资源。
- 释放打开的文件句柄、网络连接(若有),避免资源泄露。
- 若模型进程关闭,会完全释放所有占用的 CPU 资源,模型进程终止。
- 1. 显存资源释放
- 硬件依赖:
- 主导硬件:CPU(资源释放调度)、GPU(显存资源释放)、内存(内存数据回收)。
- 耗时特点:耗时极短(毫秒级),释放完成后,硬件可立即投入其他任务。
- 关键意义:避免资源泄露,防止长期运行后硬件资源被耗尽,导致后续程序无法正常运行。
2.3.5 输出结果阶段可视化图

- 左侧展示 Token ID 序列的预处理过程;
- 中间解码模块标注核心反向映射逻辑,附带示例;
- 右侧展示结果输出渠道和资源释放模块;
- 箭头清晰标注各步骤的流转关系。
三、总结
走完大模型从加载到出结果的全流程,最大的感悟不是纠结于参数细节,而是读懂平衡与取舍。大模型运行从不是单一环节的比拼,而是软件逻辑与硬件能力的双向适配。就像搭积木,再好的权重文件,没有合理的加载逻辑和足够的硬件资源,也拼不出能用的模型。很多时候我们困在 OOM、卡顿里,不是硬件不够强,而是没摸清每个环节的节奏,不懂在精度与资源、速度与效果间做取舍。
其次,底层逻辑比调包技巧更重要。以前只会用框架调用模型,遇到问题只能瞎猜;读懂全流程后才明白,任何故障都有迹可循,加载失败多是基础没打牢,生成问题多是节奏没踩对。理解底层不是为了钻牛角尖,而是拥有快速破局的底气。
最后,大模型运行的核心是顺势而为。不用追求极致优化,适合场景就好:日常使用没必要死磕满精度,显存紧张就适度压缩;不频繁调用就及时释放资源,高频使用就保留缓存。技术落地从来不是越复杂越好,把基础流程摸透、做好适配与取舍,反而能让大模型跑得又稳又顺,这才是最实在的收获。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号