深度解析palantir(三)
原创

自省:
- 冷热数据合并成完整表
- 分区 = 多收银台并行处理,最后按行拼接结果
- 检查点 = 崩溃后的复活点
- 至少一次(快) / 精确一次 (慢)= 两种重复与一致性策略
- 延迟 = 处理快慢
- 水位线 = 给迟到数据设的最晚等待底线,数据齐了可以提前关窗口
Palantir Foundry 流处理核心概念
这份文档是Foundry实时流处理能力的完整底层原理手册,它定义了Foundry中针对低延迟实时数据的核心载体「流(Stream)」的架构、能力、配置与最佳实践。
它和你之前学习的「数据集」是Foundry平台批处理+流处理的双核心载体:数据集是面向批量、高吞吐、离线场景的基础,流是面向实时、低延迟、在线场景的基础,且流完整继承了数据集的所有企业级能力(权限、版本、Schema、分支等),实现了真正的批流一体架构。
以下是文档内容的逐模块深度拆解,同时完整对应你提供的Pipeline Builder流配置截图,实现原理与实操的完全打通。
一、流的核心定义:与数据集的对比与定位
1. 核心本质
流是Foundry中针对实时数据的结构化载体,是数据从进入平台到被下游系统实时处理的核心表示形式。 和数据集的底层设计对比如下,你可以快速建立认知:
特性 | 数据集(Dataset) | 流(Stream) |
|---|---|---|
底层封装 | 对底层文件系统中一组文件的逻辑包装 | 对行级数据集合的逻辑包装,底层分为「热缓冲区」+「冷存储」两层 |
核心定位 | 批量、离线、高吞吐的批处理场景 | 实时、低延迟、持续流入的流处理场景 |
核心存储格式 | Parquet(列式存储,适合批量分析) | Avro(行式存储,适合实时流读写) |
通用能力 | 分支、版本控制、权限管理、Schema管理、数据沿袭 | 完整继承数据集的所有企业级能力,额外提供数据的低延迟实时视图 |
结构化要求 | 支持结构化、半结构化、非结构化数据 | 本质是纯表格化的,仅支持结构化数据,必须绑定Schema |
2. 核心设计优势
Foundry流的核心差异化,是解决了传统流处理系统的两大行业痛点:
- 批流能力割裂:传统流处理的实时数据,只能给实时应用使用,离线分析需要额外同步数据;而Foundry流的冷存储会自动归档为标准数据集,所有Foundry应用(哪怕不支持实时处理)都可以直接操作流数据。
- 实时与低成本不可兼得:传统流处理为了低延迟,全量数据都存在昂贵的热存储中;而Foundry流通过「热缓冲区+冷存储」的混合架构,同时享受热存储的低延迟和冷存储的低成本。
二、流存储架构:热缓冲区 + 冷存储
这是Foundry流的底层核心架构,文档中明确了两层存储的分工、特性与协同逻辑,也是低延迟与低成本兼得的核心原因。
1. 热缓冲区(热存储)
核心定位
热缓冲区是流数据的实时接入层与低延迟读取层,所有实时流入的行数据,第一时间会存入热缓冲区,供所有支持实时读取的下游应用直接访问。
核心特性
- 是实现毫秒/秒级低延迟变换的核心基础,数据写入后立即可读,无需等待文件归档;
- 为数据接入提供原生的「至少一次」语义保障,为平台内的流处理提供可选的「精确一次」语义;
- 仅存储最近几分钟的热数据,容量小、读写性能极高,对应你截图里的
Output Stream实时输出,就是先写入热缓冲区。
2. 冷存储(冷缓冲区)
核心定位
冷存储是流数据的长期持久化层,Foundry会每隔几分钟,自动把热缓冲区里的数据转移到冷存储中,这个过程官方称为归档。
核心特性
- 归档后的流数据,会自动转换成标准的Foundry数据集,和你之前学习的批量数据集完全一致,所有Foundry应用(Pipeline Builder、Code Repositories、Contour、BI工具等)都可以直接操作,哪怕不支持实时处理;
- 底层基于兼容HDFS的文件系统(S3、HDFS等)存储,成本极低,适合存储全量历史流数据;
- 归档过程完全自动、对用户透明,无需手动配置调度任务。
3. 混合视图:冷热数据的无缝打通
文档中重点强调的核心能力:所有支持低延迟的Foundry产品,都可以读取流的混合视图。 简单来说,下游应用读取流数据时,会自动合并「热缓冲区里的最新实时数据」+「冷存储里的历史归档数据」,给用户呈现一个完整、无断点的全量数据视图。
- 对用户来说,完全不用关心数据在热存储还是冷存储,读写逻辑完全统一;
- 同时享受热存储的低延迟(最新数据秒级可见)和冷存储的低成本(历史数据廉价存储)。
三、流的事务机制:与数据集的核心差异
这部分必须和你之前学习的数据集事务做强对比,才能彻底理解流的实时性设计。
1. 数据集的事务回顾
数据集的事务是批量原子操作,有明确的事务边界:一个事务对应一次批量文件修改(SNAPSHOT/APPEND/UPDATE/DELETE),事务提交后,整个数据集的视图才会更新,是批处理的设计逻辑。
2. 流的事务机制
文档中明确了流的核心设计:流本身没有固有的事务边界,每一行数据就是一个独立的事务。
- 流会在行级粒度跟踪数据的处理状态,数据写入一行,就完成一个独立事务,立即可被下游读取;
- 无需等待批量提交、无需轮询、无需攒批,天然支持推送式的实时变换,数据流入后立刻触发下游处理,这是流能实现低延迟的核心原因。
四、流类型配置:吞吐量与延迟的权衡
文档中明确了流的两种核心配置项,用于适配不同的吞吐量需求,官方反复强调必须先看流指标,再修改配置,避免盲目调整导致反向优化。
1. 高吞吐量配置
核心作用
专门适配每秒数据量极大的流场景,通过牺牲极少量的延迟,换取更高的吞吐能力。
适用场景(官方明确的触发条件)
只有当流指标出现以下情况时,才需要开启:
- 流的平均批处理大小,已经等于配置的最大批处理大小;
- 流任务因为Kafka生产者批次过期,出现报错、数据丢失。
权衡
收益:大幅提升流的每秒数据承载能力; 代价:会引入少量非零延迟(毫秒级),因为系统会攒少量批次再写入,提升吞吐。
2. 压缩配置
核心作用
开启后,会在数据写入热缓冲区时,对消息批次进行压缩,减少数据体积。
适用场景(官方明确的触发条件)
只有当流满足以下条件时,才建议开启:
- 流数据中包含大量重复字符串(比如重复的日志字段、固定的业务标识);
- 流出现了网络带宽瓶颈,导致延迟升高、吞吐量低于预期、甚至数据丢失。
权衡
收益:大幅降低网络传输带宽占用、减少热/冷存储的成本; 代价:压缩和解压缩会消耗额外的CPU资源,可能会给流任务带来额外的计算开销。
配置入口
文档中明确了配置位置:创建流时可直接设置,已有流可通过「流数据集→详情→流设置」修改,和你之前看的数据集详情页逻辑完全一致。
五、分区:流高吞吐量的核心保障
1. 核心定义
分区是Foundry流实现并行处理的核心机制:创建流时,系统会把输入流拆分成多个独立的分区,每个分区可以并行读写、并行处理,从而大幅提升流的整体吞吐量。
2. 核心特性与最佳实践
- 吞吐量线性提升:官方给出了明确的经验法则:每个分区大约可以为流提升5mb/s的吞吐量。比如10个分区,流的最大吞吐量大约可以达到50mb/s。
- 用户完全透明:这是Foundry的核心优化——尽管底层是多分区并行处理,但用户对流的所有读写操作,都和单分区完全一致,不用关心底层分区的细节、不用手动处理分区逻辑,完全屏蔽了原生流处理(如Kafka)的分区复杂度。
- 配置方式:创建流时,通过吞吐量滑块控制分区数量;也可以在流设置中修改,对应你截图里的
Number of Output Partitions配置项,就是用来控制流输出的分区数,调整吞吐量。
六、支持的字段类型
文档中明确:Foundry流支持与数据集完全一致的所有字段类型,包括BOOLEAN、INTEGER、STRING、MAP、ARRAY、STRUCT、DATE、TIMESTAMP等全量类型。 这个设计的核心价值是批流无缝兼容:
- 批量数据集的Schema,可以直接复用给流,无需修改字段类型;
- 流归档后的数据集,和批量数据集的类型完全一致,下游加工逻辑无需任何修改,真正实现批流一体。
七、流任务与检查点:流处理的容错核心
1. 流任务
文档中明确:所有流任务在内部都表示为任务图(DAG有向无环图),对应你Pipeline Builder里的流处理流水线画布。
- 流任务的可视化画布,就是任务图的直观展示;
- 数据会按照任务图里的有向边,从数据源(流)开始,经过各个变换算子,最终流到数据接收器(输出流);
- 你截图里的
Output Stream,就是任务图的终点——数据接收器。
2. 检查点(Checkpoint):流任务7×24小时稳定运行的核心
检查点是Foundry流实现容错、故障自动恢复的核心机制,也是实现「精确一次」语义的基础。
核心定义
检查点是一个特殊的数据快照,它存储了两个核心信息:
- 流任务的当前处理位置:已经处理到流的哪一行数据,避免重启后重复处理;
- 任务图中每个算子的实时运行状态:比如聚合算子的中间计算结果、窗口状态等。
工作流程
- 流数据源会定期生成检查点(默认2秒一次);
- 检查点会和业务数据一起,沿着任务图的算子流动;
- 当检查点流到任务图末端的所有数据接收器时,系统会确认:这个检查点之前的所有数据,已经全部处理完成;
- 系统会持久化保存这个最新的检查点。
核心价值(容错能力)
如果流任务因为故障、重启、升级而中断,重启后会自动从最新的检查点位置继续运行,不需要从头重新处理所有历史数据,既保证了数据不丢不重,又避免了重复计算的开销。 同时,你可以在流任务的「任务详情页面」,实时查看最近几个检查点的状态、大小、处理耗时,用于流任务的性能调优与故障排查。
八、流一致性保证:截图配置项的完整解读
这部分是文档的核心重点,完全对应你截图里的Data consistency guarantee下拉配置项,也是流处理中最核心的语义保障。
Foundry流提供两种一致性语义:At Least Once(至少一次) 和 Exactly Once(精确一次),下面分别拆解定义、优缺点、适用场景,同时对应截图里的配置。
1. At Least Once(至少一次语义)
核心定义
保证每一条流入的消息,至少会被下游传递、处理一次;但在检查点出错、任务重试的场景下,同一条消息可能会被多次传递、处理,也就是可能出现重复数据。
核心优缺点
优点 | 缺点 |
|---|---|
1. 绝对保证数据不丢失,消息耐久性极强;2. 延迟极低:消息处理完成后立刻对下游可见,无需等待检查点完成,比精确一次语义延迟更低 | 下游消费应用必须自行处理重复数据,比如通过主键去重、实现幂等处理逻辑 |
适用场景
- 对延迟要求极高,可容忍少量重复数据的场景:比如实时监控大盘、日志采集、设备状态上报;
- 下游可以轻松实现去重的场景:比如基于唯一主键的业务数据,下游可以通过主键去重。
2. Exactly Once(精确一次语义)
核心定义
保证每一条流入的消息,会被传递、处理且仅处理一次,绝对不会出现数据丢失,也绝对不会出现重复数据,是消息传递的最高级别保障。
核心优缺点
优点 | 缺点 |
|---|---|
1. 绝对保证数据不丢不重,处理结果完全一致;2. 彻底消除了下游处理重复数据的需求,无需实现幂等逻辑,大幅简化下游应用的开发复杂度 | 会引入更高的可见性延迟:只有当检查点完整流过整个任务图、确认所有数据处理完成后,消息才会对下游可见(默认检查点间隔2秒,也就是延迟约2秒);注:数据本身还是实时处理的,只是可见性延迟了 |
适用场景
- 对数据准确性要求极高,绝对不能有重复的场景:比如金融实时交易、财务对账、精准的业务指标计算、计费场景;
- 下游无法实现去重、无法做幂等处理的场景。
3. 官方明确的配置边界与权衡
- 配置入口:就是你截图里的Pipeline Builder → Build settings → Advanced configuration → Data consistency guarantee下拉框,流管道的两种语义都在这里配置。
- 边界说明:目前Foundry的流数据源(比如从Kafka接入流)仅支持「至少一次」的导入和导出;但流管道内部的处理逻辑,同时支持两种语义。
- 核心权衡:两种语义的选择,本质是延迟和处理复杂度的权衡:
- 想要更低的延迟,能接受下游处理重复数据 → 选「至少一次」;
- 想要简化下游逻辑,保证数据绝对准确,能接受秒级的可见性延迟 → 选「精确一次」。
九、全元素与文档的对应关系
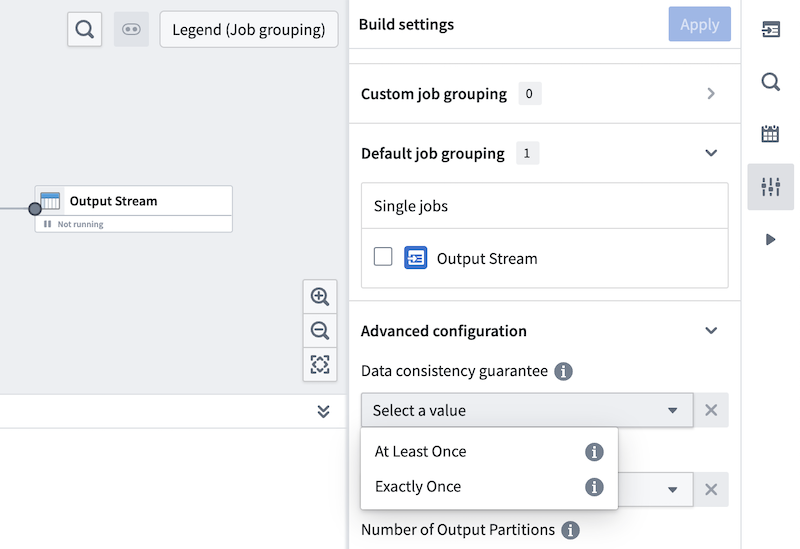
你提供的Pipeline Builder流配置截图,所有元素都能和文档内容完全对应,这里给你完整拆解:
截图界面元素 | 对应文档中的核心概念 | 核心作用 |
|---|---|---|
Build settings | 流管道的搭建设置 | 流任务的核心配置入口,配置完成后点击Apply生效 |
Custom job grouping / Default job grouping | 流任务、分区的并行处理 | 控制流任务的作业分组、并行度与资源分配,对应流的并行处理能力 |
Single jobs → Output Stream | 流任务的任务图、数据接收器 | 流处理流水线的最终输出,对应文档中流任务的数据流终点 |
Advanced configuration → Data consistency guarantee | 流一致性保证 | 文档核心的「至少一次/精确一次」语义配置,就是你截图里的下拉框 |
Number of Output Partitions | 流的分区配置 | 控制输出流的分区数量,调整流的吞吐量,对应文档中的分区章节 |
十、整体能力闭环:Foundry批流一体架构总结
文档中定义的所有流能力,和你之前学习的数据集、Pipeline Builder、数据连接等组件,形成了完整的批流一体闭环,一个标准的实时数据处理流程如下:
- 实时数据接入:通过「数据连接」应用,对接Kafka、MQTT、业务数据库CDC等实时数据源,将数据接入Foundry,生成流;
- 实时加工处理:在Pipeline Builder中搭建流处理流水线,配置一致性语义、作业分组、输出分区,完成实时数据的清洗、关联、聚合、窗口计算;
- 双层存储落地:处理后的实时数据先写入热缓冲区,供下游低延迟应用(实时大盘、预警系统)秒级读取;几分钟后自动归档到冷存储,生成标准数据集,供离线分析、BI报表、批量加工使用;
- 运维容错保障:通过检查点机制实现流任务的故障自动恢复,通过流指标监控吞吐量、延迟,调整流类型、分区数,保障流任务7×24小时稳定运行;
- 全链路企业级管控:流完整继承了数据集的权限管理、Schema管理、版本控制、分支、数据沿袭、数据健康等所有能力,和批处理链路完全打通,实现了一套平台、一套逻辑、同时支撑批流两种场景。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号