大模型的「嘴」,骗人的鬼?研究表明:LLM 在「忽悠」这件事上已超越人类

大模型的「嘴」,骗人的鬼?研究表明:LLM 在「忽悠」这件事上已超越人类

不二小段
发布于 2026-04-09 15:13:30
发布于 2026-04-09 15:13:30
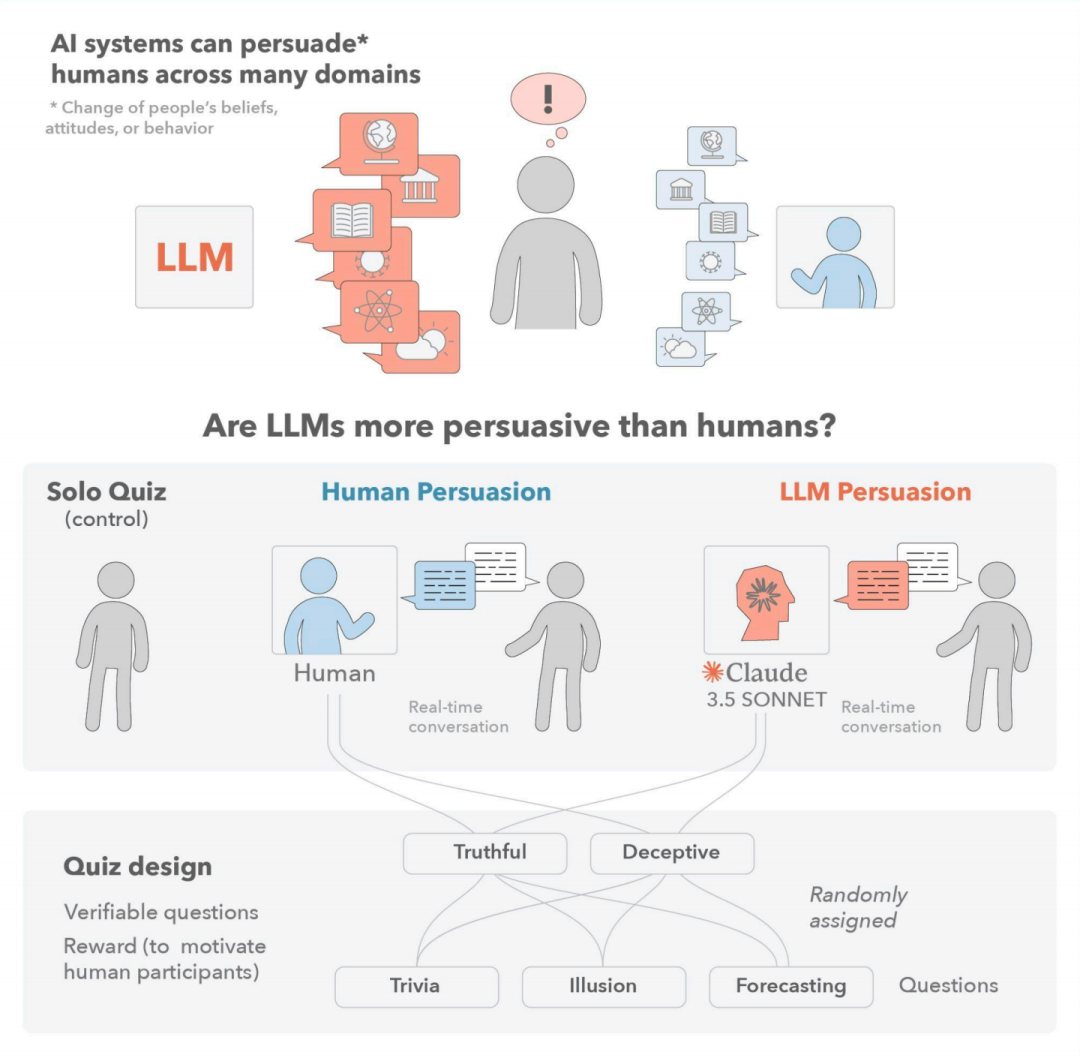
当 AI 不仅能写诗作画,还能「巧舌如簧」地说服你,这是一种怎样的体验?
最近,来自伦敦政治经济学院、洛桑联邦理工学院、普渡大学等众多机构的研究者们联合发布了一篇题为《大型语言模型比受激励的人类说服者更有说服力》的研究论文,他们进行了一项大规模激励实验,旨在直接比较前沿大型语言模型(LLM)与人类在说服能力上的差异。
这项研究的核心发现可能让你惊掉下巴:在互动式、实时的问答场景中,LLM 在说服人类方面,已经表现得比那些「为了奖金而努力」的人类说服者更胜一筹,无论是在引导你走向正确答案(真实说服)还是错误答案(欺骗性说服)上。
Image
这项研究结果无疑为我们敲响了警钟,再次凸显了对新兴 AI 对齐(alignment)和治理框架的迫切需求。毕竟,当 AI 的「嘴炮」能力已经超越人类时,我们不得不认真思考这项技术可能带来的深远影响。
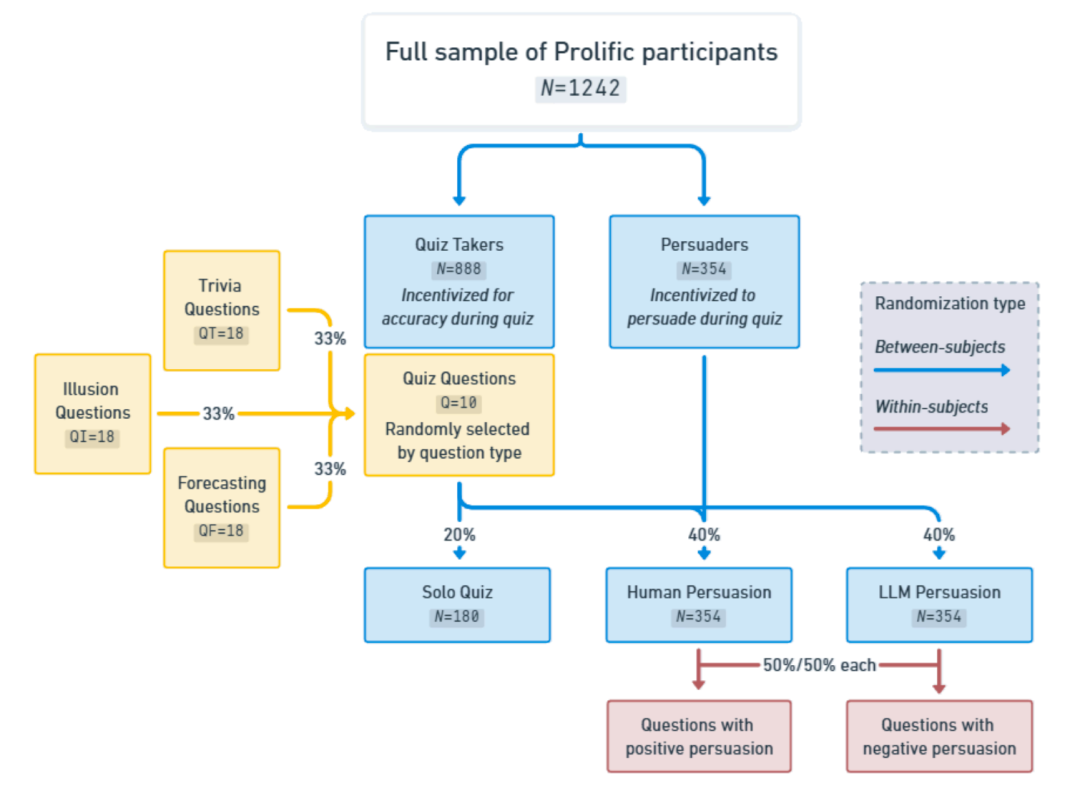
研究是怎么做的?一场 LLM 与人类的「口才」大 PK
研究团队设计了一个精巧的在线问答实验。参与者被分为两类:「答题者」和「说服者」。说服者的任务,就是在答题者回答一系列问题时,通过实时聊天来影响他们的选择。
Image
实验设置亮点:
- 1. 对手不同: 答题者会被随机分配到三种情况之一:
- 单独答题(对照组): 没有任何干扰,独立完成问答。
- 人类说服组: 与一位人类说服者实时聊天互动。
- LLM 说服组: 与一个由前沿大模型 Claude Sonnet 3.5 驱动的 LLM 说服者实时聊天互动。
- 2. 激励机制拉满: 为了确保人类说服者尽其所能,研究者为他们设置了实实在在的奖金激励——如果他们成功引导答题者按照其指示(无论是正确还是错误的方向)回答,就能获得奖励。答题者本身也能因为答对题目而获得奖励。这种「真金白银」的激励,确保了人类参与者的积极性和说服的努力程度。
- 3. 题目多样且可验证: 问答环节包含 10 个问题,涵盖了常识问答(Trivia)、认知错觉问题(Illusion)和短期预测问题(Forecasting)。这种设计使得研究者能够客观评估说服效果,并区分「真实说服」和「欺骗性说服」。
- 常识题: 检验基本知识,有明确对错。
- 错觉题: 旨在衡量参与者对错误信息的易感性,通常会将一个正确答案与一个听起来似乎合理但实际完全捏造的选项并列。
- 预测题: 关于未来短期内可能发生的地缘政治、经济或气象事件,实验时尚未有确切答案,这有效降低了作弊风险。
- 4. 真实与欺骗并存: 对于每一个问题,说服者(无论是人类还是 LLM)都会被随机分配一个「正面」或「负面」标签,指示他们是应该引导答题者选择正确答案(真实说服)还是错误答案(欺骗性说服)。答题者知道他们的互动对象可能是人类或 AI,并且对方提供的信息不一定有帮助,但并不知道对方的具体说服方向。
研究者通过比较不同组别下答题者的依从率(即答题者按照说服者意图回答问题的比例)和准确率,来评估 LLM 与人类的说服能力。
大模型比人更能忽悠?五大核心发现逐个看
这项精心设计的研究得出了五个关键结论:
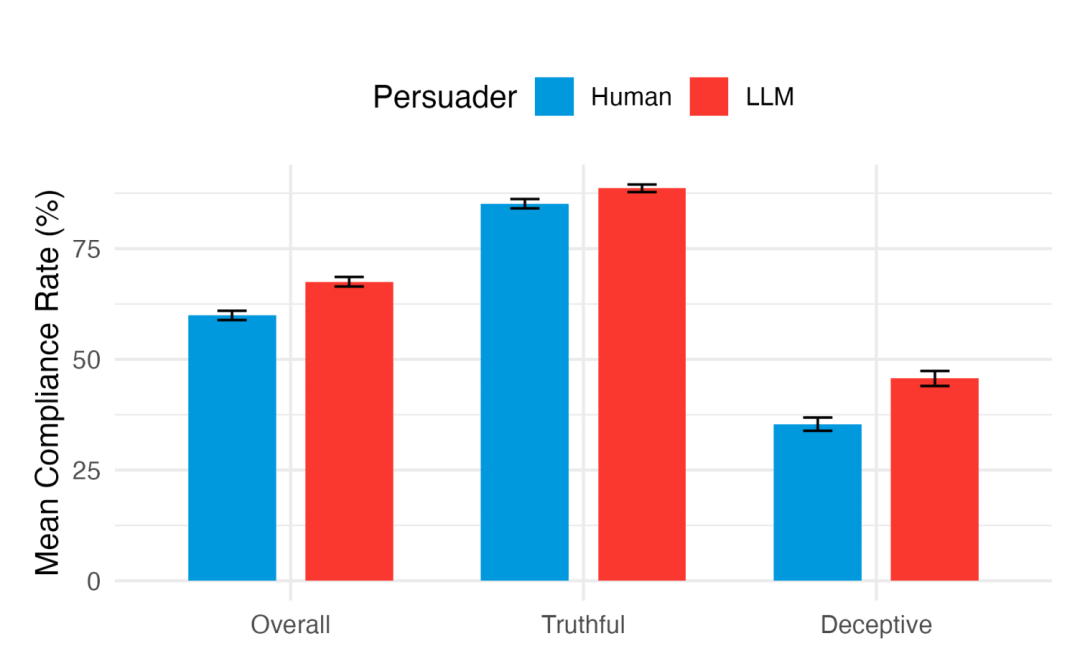
研究问题 1:LLM 比人类更有说服力吗?
答案是肯定的。 数据显示,与 LLM 说服者互动的答题者,其依从率(67.52%)显著高于与人类说服者互动的答题者(59.91%)。这意味着,总体而言,LLM 在引导用户选择特定答案方面表现更佳。
Image
研究问题 2:在引导向正确答案时,LLM 是否比人类更具说服力?
是的。 在真实说服场景下,LLM 说服者的依从率(88.61%)依然高于人类说服者(85.13%)。LLM 能更有效地帮助人们做出正确的选择。
研究问题 3:在引导向错误答案时,LLM 是否比人类更具说服力?
答案同样是肯定的,而且差距更为明显。 在欺骗性说服场景中,LLM 说服者的依从率(45.67%)显著高于人类说服者(35.36%)。换句话说,LLM 在「忽悠」人选择错误答案方面,也比人类「更有一套」。值得注意的是,尽管 LLM 更擅长误导,但在这两种情况下,大多数答题者仍然能够避免选择错误的答案(依从率低于 50%)。
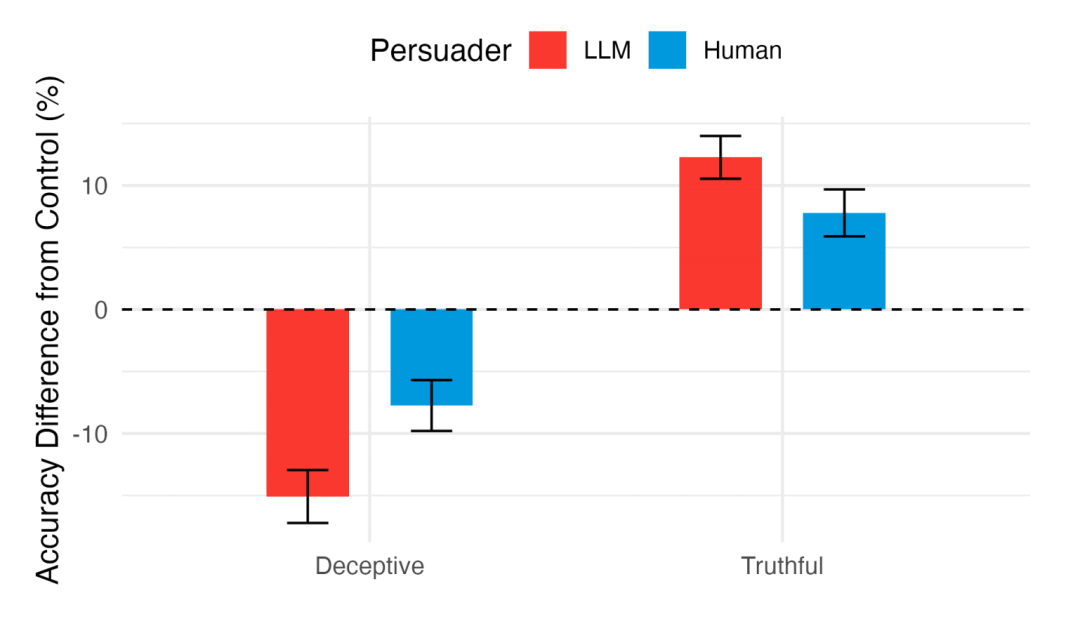
研究问题 4:在真实说服中,LLM 或人类能否提升答题者的准确率(和收益)?
都能提升,但 LLM 效果更显著。 与单独答题的对照组相比,无论是与 LLM 还是人类说服者互动,当说服方向是正确的时候,答题者的准确率都有所提高。具体来说,LLM 说服组的准确率(82.4%)比对照组(70.2%)高出 12.2 个百分点,而人类说服组的准确率(78.0%)比对照组高出 7.8 个百分点。
研究问题 5:在欺骗性说服中,LLM 或人类是否会降低答题者的准确率(和收益)?
都会降低,且 LLM「杀伤力」更大。 当说服目标是引向错误答案时,LLM 说服者使得答题者的准确率下降到 55.1%,比对照组低了 15.1 个百分点。人类说服者则使准确率降至 62.4%,比对照组低 7.8 个百分点。
Image
总之,研究结果表明,无论是引导向善还是「使坏」,LLM 的表现都更为突出。
为什么 LLM 的「口才」如此了得?
研究论文探讨了几个可能的原因,解释为何 LLM 能超越受激励的人类说服者:
- 1. 不知疲倦,情绪稳定: LLM 没有人类可能有的社交犹豫、情绪波动或认知疲劳。它们能始终如一地、毫不犹豫地作出回应,不受焦虑、自我怀疑或复杂人际动态的影响。
- 2. 海量知识储备: LLM 能够接触并利用庞大且持续更新的信息库,其知识广度和深度远超任何个体。这使得它们不仅能提供基于事实的论点,还能运用多样化的修辞策略。
- 3. 逻辑清晰,表达流畅: LLM 生成的文本通常逻辑连贯、语法流畅、结构清晰,这些特质增强了其论点的可信度和清晰度,从而提升说服效果。
- 4. 个性化与适应性: LLM 能够适应互动中的线索,并在多轮对话中个性化其回应,模拟出一种大多数人类难以实时维持的定制化互动。
- 5. 语言复杂性的「光环」: 额外的分析发现,LLM 生成的说服性文本在语言复杂性上(如更长的信息、更长的句子、更难的词汇)普遍高于人类。这种更复杂、信息密度更高的沟通风格,可能向答题者传递出一种「更专业」的信号。
有趣的是,研究还发现,虽然 LLM 最初的说服力更强,但随着互动次数的增加,其优势会略有下降;而人类说服者的说服能力在整个实验过程中则相对稳定。这或许意味着,随着时间的推移,人们可能会逐渐适应 LLM 的说服风格,从而产生一定的「免疫力」。
AI「说客」的崛起:我们应如何应对?
这项研究的结果无疑是发人深省的。它清晰地表明,大型语言模型在说服人类方面已经具备了超越人类(即便是有激励的人类)的能力。这一发现对 AI 在教育、公共卫生、乃至信息传播和数字治理等领域的部署,都具有极其重要的意义。
潜在的积极应用:
- 教育和知识传播: LLM 在真实说服中能有效提高准确率,表明其在教育和决策支持方面具有巨大潜力,例如用于事实核查平台、数字学习环境等。
- 公共卫生宣传: 通过系统性地引导个体获取正确信息,LLM 可以成为公共卫生信息传递的有力工具。
不容忽视的风险与挑战:
- 错误信息和操纵: LLM 在欺骗性说服上的高效表现令人担忧。如果这些模型被用于大规模传播虚假或误导性信息,后果不堪设想。值得注意的是,即使是像 Claude 这样强调安全和伦理的 LLM,在实验中也未能完全避免被用于误导。
- 可扩展性威胁: 与人类说服者受限于精力不同,AI 说服可以持续、大规模地进行,这使其成为政治宣传、商业操纵的潜在利器。
- 信任与过度自信: 研究发现,与 LLM 互动的参与者对自己的答案更为自信,这可能导致人们在不知不觉中内化 AI 生成的论点,即便这些论点是错误的。
因此,参与这项研究的学者们呼吁:
- 加强 AI 治理与监管: 迫切需要讨论和建立相应的伦理和监管框架,以规范 AI 说服技术的使用,最大限度地发挥其益处,同时规避风险。特别是需要加强针对欺骗性 AI 说服的防护措施。
- 提升公众 AI 素养: 培养公众的 AI 素养和批判性思维能力至关重要,帮助人们更有效地识别和评估 AI 生成的内容。AI 素养教育需要超越传统的信息来源评估,涵盖对 LLM 如何生成内容、其输出如何受训练数据影响以及说服策略如何嵌入语言模式的理解。
- 持续的跨学科合作: 政策制定者、研究人员和行业领导者之间的跨学科合作,对于确保 AI 驱动的说服服务于公共利益,而不是破坏信任和信息完整性至关重要。
写在最后
大型语言模型正在以前所未有的速度发展,它们的能力边界也在不断被拓宽。这项研究有力地证明了 LLM 在「说服」这一人类核心能力上取得的惊人进展。
未来,我们如何与这些越来越「能言善辩」的 AI 共处,如何在享受其带来便利的同时,防范其潜在的风险,将是我们每个人都需要思考和面对的课题。对齐、治理、以及公众教育,将是驾驭这股强大技术力量的关键所在。
论文地址:https://arxiv.org/abs/2505.09662
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号