解析最新开源的 AReaL-boba² 框架:异步强化学习在大型推理模型训练中的应用

解析最新开源的 AReaL-boba² 框架:异步强化学习在大型推理模型训练中的应用

不二小段
发布于 2026-04-09 15:46:59
发布于 2026-04-09 15:46:59
自 OpenAI 推出 o1 模型以来,推理已经逐渐成为了大语言模型的必备能力。在推理能力背后,强化学习(RL)扮演着越来越重要的角色,但也对训练系统提出了新的要求。
最近,蚂蚁技术研究院和清华大学交叉智能研究院共同提出并开源了一个全新的项目——AReaL-boba²,通过架构创新、算法创新和一系列系统级优化,实现完全异步的 RL 系统,大幅提升 GPU 利用率,训练速度达到传统同步系统的 2.77 倍,大幅提升效率的同时模型性能不降,甚至略有提升!
那么,AReaL-boba² 究竟是如何实现如此高效的异步训练?新的训练范式又会带来什么样的行业机会呢?
效率之困:我们为什么需要异步并行 RL 系统
强化学习赋予了大模型推理思考的能力,将传统的 CoT 思维链过程进一步强化,使得模型在数学、编程、逻辑乃至智能体任务中能力提升巨大。这类模型通常被称为大型推理模型 (Large Reasoning Models, LRMs)。
然而,要高效地训练这些 LRMs,高效的 RL 训练系统面临着许多挑战:
- 频繁切换的开销:RL 系统需要在 LLM 的生成(inference)和训练(training)之间频繁切换,如果没有精心优化,这种频繁切换会带来巨大的系统开销。
- 动态变化的工作负载:对于的不同 prompt,LRM 生成的思考过程和答案长度可能差异巨大,且在整个 RL 过程中不断变化。这导致生成和训练的工作负载也会随之剧烈波动,高性能硬件很容易出现空闲,造成算力资源的浪费。
- 对新鲜数据的需求:RL 算法(如 PPO)通常要求使用 on-policy 数据进行训练,这意味着训练样本必须是由最新的模型生成的,这样才能保证模型学到的是当前最优的行为,从而达到最佳性能。
同步 RL 系统的做法和痛点
现有的大多数大规模 RL 系统都采用了完全同步的设计,严格交替执行 LLM 的生成和训练。好处是能确保 LLM 始终用最新的输出来训练,从而在实践中获得最佳性能。
然而,同步 RL 系统的「痛点」也同样突出:
- 推理设备利用率低:在同步模式下,生成阶段必须等待批次 (batch) 中最长的输出序列全部完成之后,才能开始下一阶段的训练。如果遇到个别输出特别长的情况,GPU 就会闲置在那里「摸鱼」。
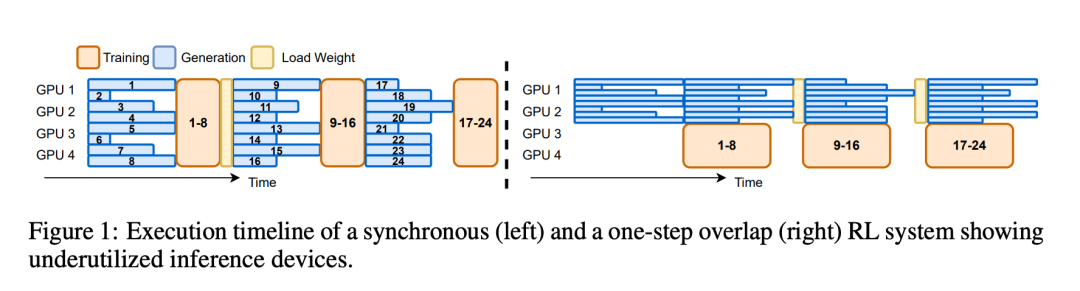
Image
- 可扩展性差:同步系统将生成任务分散到所有设备上,降低了每个 GPU 的解码批次大小。这使得解码过程容易陷入内存或 IO 瓶颈,即使增加设备也无法有效提升吞吐量。
并行化 RL 的初步探索
既然同步 RL 有这么多问题,大家自然会想到异步 RL。学术界和工业界早有探索。例如,此前的 IMPALA 和 SEED RL 等系统在游戏 AI 领域取得了成功,它们也采用了异步或者部分异步的思路。
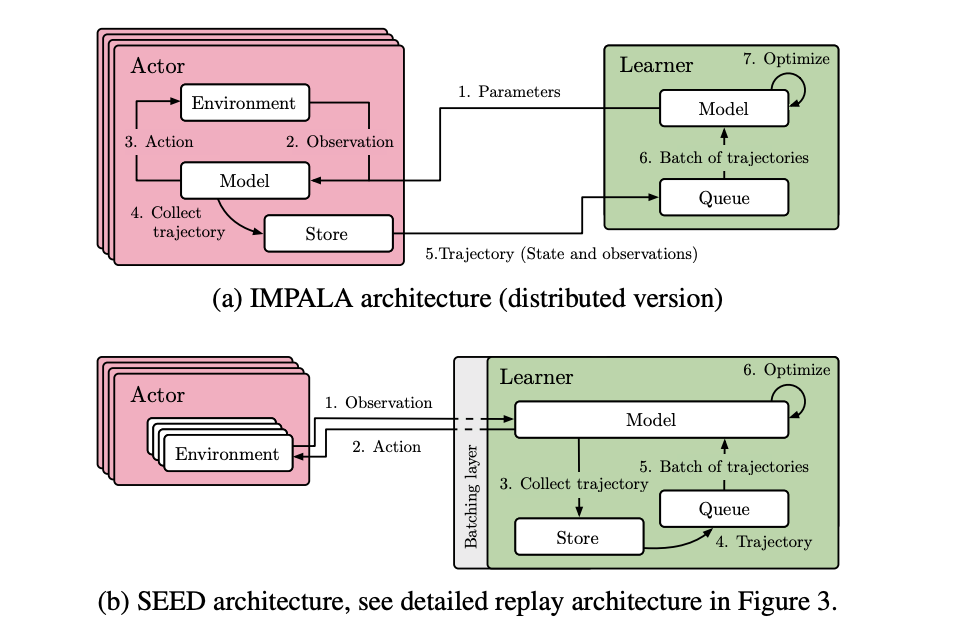
Image
一些近期的工作也尝试将并行生成和训练引入 LLM,它们允许使用前一两个模型版本生成的数据来更新当前模型。
然而,这些系统大多仍然遵循「批次生成」的设定,也就是一个训练批次内的所有样本仍然来自同一个模型版本。这意味着,在生成阶段内部,由输出长度不一致导致的系统效率低下问题,依然没有得到根本解决。
算力全开:AReaL-boba² 实现异步 RL 突破
AReaL-boba² 项目从一开始的目标就非常明确:设计一个硬件高效、可扩展、并且能为定制化 RL 工作流提供足够灵活性的系统,专门针对大型推理模型 (LRMs) 的训练需求,同时实现算法与系统的协同设计。
架构创新:彻底解耦生成与训练
为了克服同步系统的局限性,AReaL-boba² 的核心思想就是:在不牺牲最终模型性能的前提下,完全解耦生成与训练。
下面这张 AReaL-boba² 系统架构图展示了异步生成与训练组件:
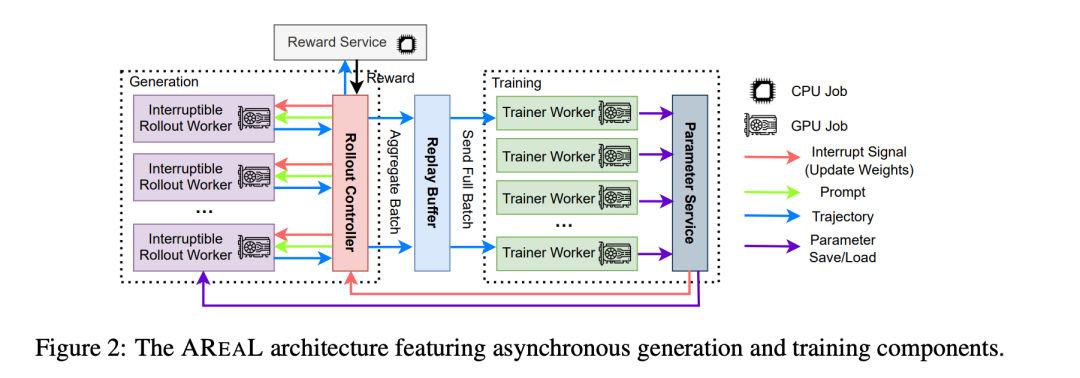
Image
AReaL-boba² 系统主要由以下四个核心组件构成:
- 可中断的采样工作器:处理两类请求,一是根据提示生成响应;二是中断所有正在进行的生成任务,并加载新版本的模型参数。当中断发生时,Rollout Worker 会丢弃旧权重计算出的 KV 缓存,并用新权重重新计算。 之后,它会继续解码未完成的序列,直到下一次中断或任务终止。
- 奖励服务:负责评估模型生成响应的准确性。例如,在代码生成任务中,它会提取生成的代码,并执行单元测试来验证代码的正确性,然后给出一个奖励分数。
- 训练工作器:这些工作器会持续地从一个名为「重放缓冲池」 的地方采样数据。当收集到足够一个训练批次的数据后,它们就会执行 PPO 等 RL 算法来更新模型参数 ,并将更新后的参数保存到分布式存储中。为了保证数据的新鲜度,从重放缓冲池中取出的数据通常只使用一次。
- 采样控制器:整个系统的「指挥中心」,协调着采样工作器、奖励服务和训练工作器之间的工作。在训练过程中,它会从数据集中读取问题,调用采样工作器的 generate 请求让模型作答;收到模型输出后,将其发送给奖励服务打分;最后,将包含问题、模型输出轨迹以及奖励的完整数据存入重放缓冲池,等待训练工作器取用。当训练工作器更新了模型参数后,控制器会调用采样工作器的 update_weights 请求,将最新的模型权重同步过去。
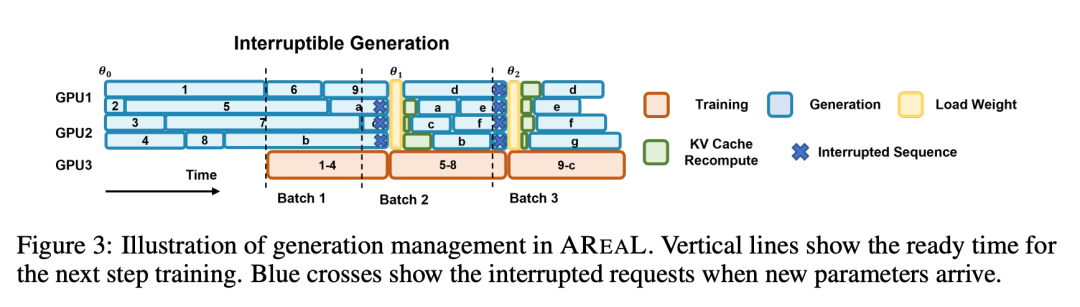
Image
这张图展示了 AReaL-boba² 中生成和训练的管理流程。这种异步流水线确保了生成和训练资源都能持续得到充分利用。
算法创新:见招拆招攻克难题
异步系统显然能够提高设备利用率,那么,代价是什么呢?主要是以下两个方面:
第一是数据过时。由于异步特性,一个训练批次中可能包含来自多个旧模型版本所生成的数据。而过时的数据则会导致训练数据的分布与最新模型的实际输出之间存在差距。
第二是策略版本不一致。AReaL-boba² 的可中断采样机制可能导致一条生成轨迹由不同策略版本(即不同时期的模型权重)共同完成。这从根本上违反了标准 PPO 算法对于所有动作都由同一策略产生的假设。
面对异步系统引入的新问题,AReaL-boba² 团队见招拆招,提出了以下算法创新:
- 过时感知训练:为了避免数据过时带来的负面影响,AReaL-boba² 引入了一个超参数来限制生成轨迹所使用的策略版本与当前正在训练的策略版本之间的最大差异,即允许的最大过时程度。训练时,优先处理较旧的轨迹,以确保过时程度保持在可控范围内。
- 解耦 PPO 目标:为了更有效地利用略微过时的数据,并解决策略版本不一致的问题,AReaL-boba² 采用了一种解耦的 PPO 目标函数来区分了行为策略和近端策略,放宽对「一个训练批次内的所有数据都必须由单一策略生成」的要求。
系统优化:榨干每一滴算力性能
除了架构和算法上的宏观创新,AReaL-boba² 还在系统层面进行了一系列精细的优化,以最大化训练吞吐量:
CPU/GPU 操作解耦及 asyncio 协程:将 GPU 计算与 CPU 密集型操作解耦执行,避免了不必要的等待。同时利用 asyncio 协程向采样工作器中并发发送多个请求并对生成结果计算奖励,避免了请求之间的相互阻塞。
动态批处理:采用 padding-free 的序列包策略,结合动态分配算法,最大化训练节点 GPU 显存利用率。
并行奖励服务:并行优化奖励计算,进一步提升效率。
又快又稳:AReaL-boba² 赋能大模型研发
AReaL-boba² 实现的异步 RL 能够显著缩短训练时间,降低训练成本,这给大模型行业带来了太多的想象力。
提升研发效率,加速创新迭代
AReaL-boba² 效果最直接的体现就是研发效率的提升。
实验结果表明,在相同的 GPU 数量下,AReaL-boba² 相较于目前最优的同步 RL 系统,能够实现高达 2.77 倍的训练吞吐量提升。 这意味着,原来需要跑一周的实验,现在可能两三天就能完成。
同时,AReaL-boba² 在多达 512 个 GPU 上展现出近似线性的扩展效率,这意味着它能够很好地支持未来更大规模模型的训练需求。同时,线性扩展也意味着只需要增多一倍GPU数量就可以将训练速度翻倍,对资源充足且希望进行快速验证的研发团队也有极大的作用。
性能稳定兼备,甚至效果更优
效率的提升往往伴随着对稳定性和最终性能的担忧。然而,在多个数学和代码推理基准测试中 (如 AIME24, LiveCodeBench),AReaL-boba² 训练出的模型性能与同步系统持平,甚至在某些情况下略有提升。
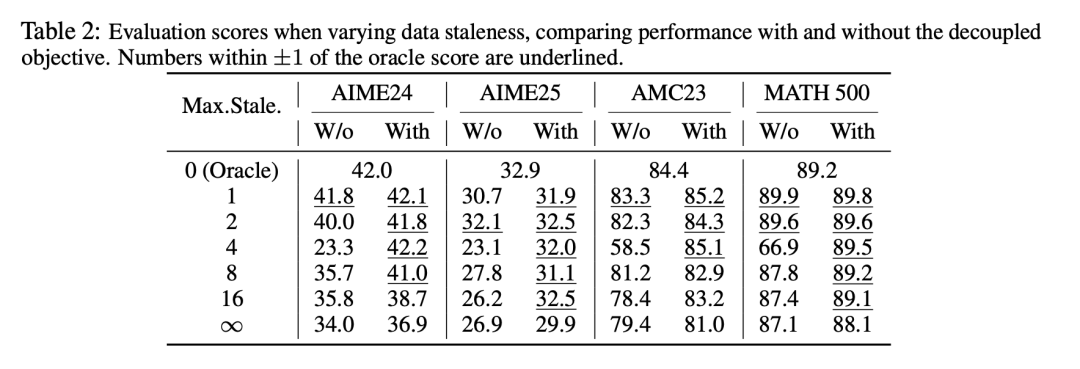
Image
催生新兴范式,拓展研究边界
AReaL-boba² 的灵活性和高效率意味着研究人员可以在有限的时间和预算内进行更多的训练和实验,为探索更复杂的 RL 算法、奖励机制以及更长的推理路径打开了大门。
论文也提到,尽管当前评估主要集中在单步数学和编码任务,但 AReaL-boba² 架构本身并不局限于这些领域,未来可以探索其在多轮交互和智能体场景中的应用。
对于需要多轮交互、长程规划的智能体任务,传统同步 RL 的低效可能会成为瓶颈,而 AReaL-boba² 的异步特性和对长序列生成的鲁棒性则可能为此类研究提供强大的系统支持。
小结:AReaL-boba² 开创规模化 RL 新篇章
AReaL-boba² 的出现,是继 DeepSeek-R1 点燃社区对 RL 热情之后,又一振奋人心的进展。
作为一种高效、可扩展且稳定的强化学习训练新范式,AReaL-boba² 成功地解决了同步 RL 系统中普遍存在的 GPU 利用率低下和扩展性差的痛点,在大幅提升训练效率的同时,保证了模型的最终性能。
更重要的是,AReaL-boba² 项目选择了完全开源,包括代码、脚本、可复现结果的数据集以及模型权重。他们希望帮助所有人轻松且低成本地构建专属 AI 智能体,就像制作一杯奶茶那样。

Image
这无疑会极大地降低研究门槛,让全球的 AI 研究者和开发者都能从中受益,共同推动大型推理模型乃至通用人工智能的边界。
我们有理由相信,AReaL-boba² 这样的工作,将为可靠地规模化 RL 训练提供坚实的基础,并催生更多在 AI 推理和智能体领域的突破性进展。AI 的未来,正在被这些坚实的创新一步步构建。
论文地址:https://arxiv.org/pdf/2505.24298
开源地址:https://github.com/inclusionAI/AReaL
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号