LlamaIndex 分享生产级 Agent 五大设计模式落地实践

LlamaIndex 分享生产级 Agent 五大设计模式落地实践

不二小段
发布于 2026-04-09 17:39:21
发布于 2026-04-09 17:39:21
Agent 的浪潮,正以不可阻挡之势席卷整个 AI 领域,我们似乎正处在一个「万物皆可 Agent」的时代。
然而,狂热之下,一个现实的问题摆在所有开发者面前:
如何构建一个真正能在生产环境中稳定运行、解决实际问题的 Agent,而不是一个时灵时不灵的「AI 玩具」?
早在去年年底,Anthropic 就在《构建有效智能体》中提出了 5 种 Agent 设计模式,但很少有人讲明白如何落地。
在一场技术分享中,Laurie Voss 给出了他的答案。他是 LlamaIndex 的开发者关系副总裁,更广为人知的身份是 npm 的联合创始人。

Laurie 和他的团队每天都在观察和帮助成千上万的开发者构建 Agent 应用。基于海量的实践案例,LlamaIndex 提炼出了一套行之有效的 Agent 实践,它们能为 LLM 戴上「缰绳」,让 Agent 的行为变得更加可靠和高效。

让我们一起学习这份极具含金量的生产级 Agent 构建指南。
Agent 的「灵魂三问」:是什么、为什么、怎么用?
在 2025 年,「Agent」这个词几乎被用滥了。但在 Laurie 看来,一个真正的 Agent 应该具备清晰的定义:
它是一种半自主的软件,能够使用工具来达成一个目标,而你无需明确指定它达成目标的每一个步骤。

这里的关键词是「半自主」和「使用工具」。这意味着 Agent 与传统编程范式发生了根本性的转变——开发者将决策权交给了 LLM。LLM 可以根据目标,自行决定调用哪个工具、以何种顺序调用。
这种灵活性正是 Agent 最大的魅力所在。它尤其擅长处理那些传统软件难以应对的、海量的、非结构化的「脏数据」。

Laurie 提出了一个他个人非常推崇的 Agent 设计核心原则:
一个好的 Agent 应用场景,本质上都是将大段文本转化为小段文本。
这个观点非常精辟,因为 LLM 的强大之处就在于理解、推理和概括。

比如:
- • 解读一份复杂的合同(大量法律条文 -> 关键条款摘要)
- • 处理一张发票(图片或 PDF -> 结构化的账单数据)
- • 应用监管条例(冗长的法规 -> 是否合规的判断)
- • 总结会议纪要(几小时的录音 -> 可执行的任务列表)
这些场景的核心都是「信息压缩」。
更重要的是,Laurie 鼓励开发者超越聊天机器人(Think beyond the chatbot)。

Chatbot 只是 2023 年的玩法,将 LLM 的能力深度集成到现有的软件工作流中,利用它处理非结构化数据的能力,将其转化为结构化数据,再喂给传统软件进行后续处理,这才是更广阔、更具价值的应用空间。
Agent 与 RAG:天作之合,缺一不可
谈到处理非结构化数据,就绕不开一个核心技术:RAG,检索增强生成。
为什么 Agent 离不开 RAG?
因为大模型需要数据!

除非你做的 Agent 是一个极其通用的闲聊工具,否则你必然需要让它基于你的私有数据(公司的、特定领域的)来回答问题或执行任务。你不可能把公司所有的文档、数据库、API 说明都塞进一个 prompt 里。
RAG 就是解决这个问题的最佳方案。
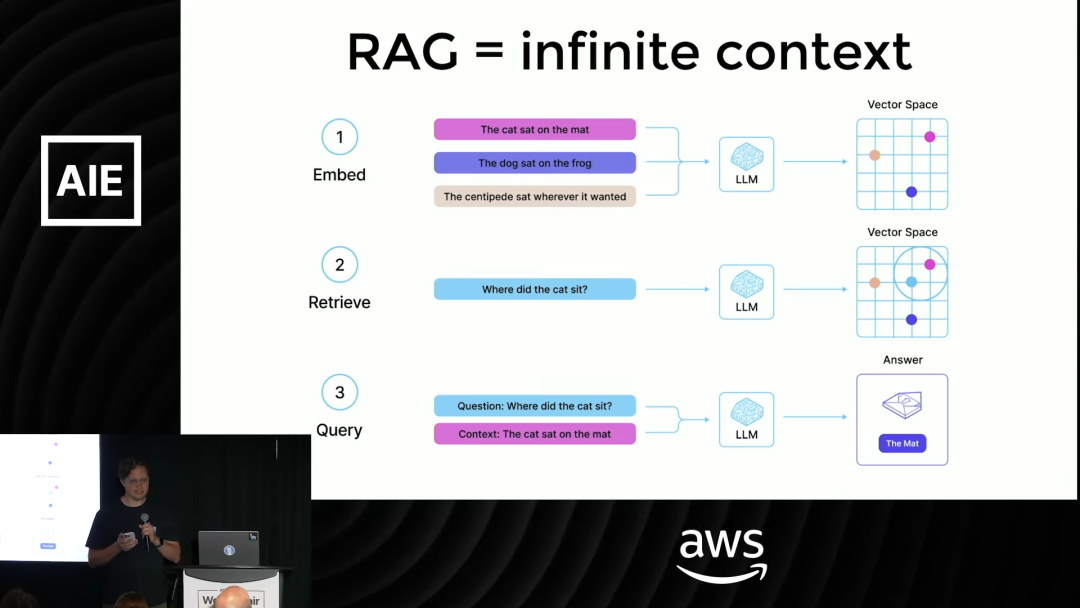
它通过以下步骤工作:
- 1. 数据索引 (Indexing):将你所有的私有数据(PDF、Word、Notion、Slack 记录等)进行切块和向量化,存入向量数据库。LlamaIndex 提供的 LlamaParse 服务在这一步能发挥巨大作用,它可以高质量地解析复杂文档,从源头上提升数据质量。
- 2. 检索 (Retrieval):当用户提出一个问题时,将问题也向量化,然后在向量数据库中寻找与问题最相关的上下文信息块。
- 3. 生成 (Generation):将用户原始问题和检索到的相关上下文信息,一同打包发送给 LLM,让它基于这些信息生成最终答案。
很多人讨论,随着 LLM 的上下文窗口越来越大,RAG 是否会被淘汰?Laurie 的回答是:「RAG will never die」。
原因很简单:
- • 成本与速度:发送更少、更相关的数据永远比发送海量数据更便宜、更快。
- • 准确性:给 LLM 提供更精准、干扰更少的上下文,总能得到更高质量的回答。
因此,Agent 需要 RAG 来获取完成任务所需的知识。
但反过来,RAG 也需要 Agent。

传统的「朴素 RAG」(Naive RAG),即简单地检索 Top-K 个最相关的文本块丢给 LLM,在很多复杂场景下表现不佳。而 LlamaIndex 在大量生产案例中发现,在 RAG 之上叠加一个 Agent 层,能显著提升结果质量。
一个 Agent 可以做到朴素 RAG 无法做到的事情:
- • 内省 (Introspection):Agent 可以反思:「这个复杂问题,是不是可以拆解成几个简单的小问题来分别回答?」
- • 自我纠错 (Self-Correction):Agent 可以判断:「我检索到的数据看起来是胡说八道,需要重新检索一次吗?」
- • 答案评估 (Answer Evaluation):Agent 可以审视自己的输出:「我给出的答案真的合理吗?是否需要再试一次?」
这种「元认知」能力,使得 Agent 成为 RAG 性能的放大器,无论在速度还是准确性上,都能带来质的飞跃。
生产级 Agent 的五大设计模式
去年 12 月,Anthropic 发表了一篇关于构建 Agent 的文章,其中总结的几个设计模式,让 LlamaIndex 团队深感共鸣——这也正是他们在实践中摸索出的经验。

Laurie 结合 LlamaIndex 的具体实现,将这五大模式再次进行了系统性阐述。
1. 链式调用 (Chaining)
这是最基础、最直观的模式。顾名思义,就是将多个 LLM 调用串联起来,前一个 LLM 的输出作为后一个 LLM 的输入。
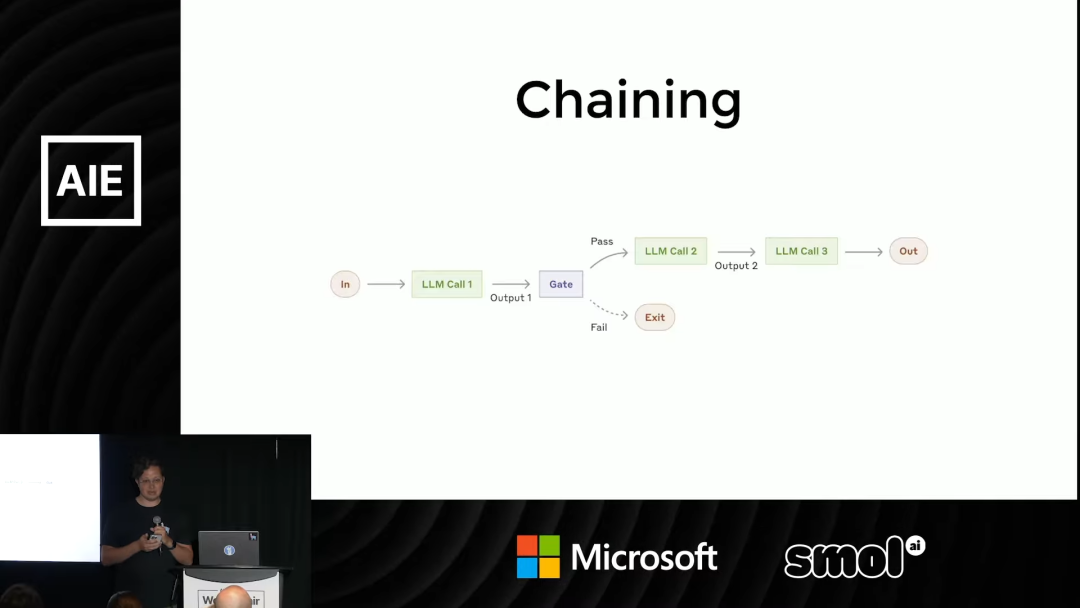
比如,第一步让 LLM 从一段非结构化文本中提取关键信息,第二步让另一个 LLM 基于提取出的信息撰写一封邮件。
在 LlamaIndex 中,通过 Workflows 抽象可以非常容易地构建一个链。开发者只需定义普通的 Python 函数,并使用类型注解来声明数据如何在工作流的各个步骤之间传递。
这仅仅是开始,Agent 的世界远比链式调用要丰富得多。
2. 路由 (Routing)
当任务路径不是单一线性时,就需要路由模式。
在这个模式中,你预先定义好多个不同的工具或子任务链,每个用于解决特定类型的问题。然后,引入一个「路由 Agent」或「决策 LLM」,它的唯一职责就是根据用户的输入,判断接下来应该调用哪一个工具或走哪一条路径。
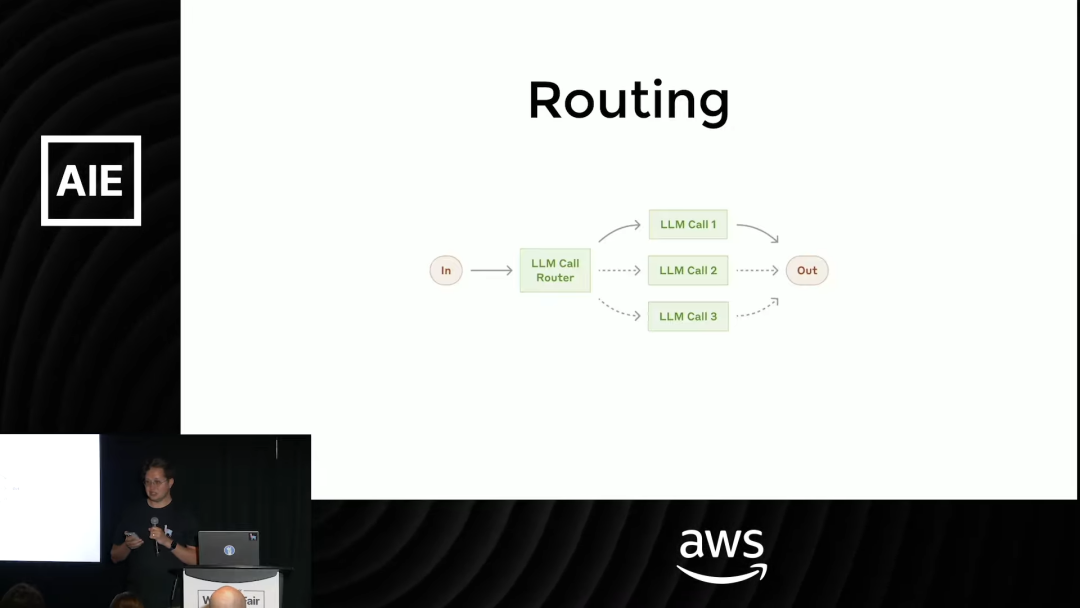
这就像一个智能电话客服,能根据你的问题,自动将你转接到「查账单」、「办业务」或「人工投诉」等不同部门。
在 LlamaIndex Workflows 中,可以通过分支来实现,让一个 LLM 的决策来引导后续的工作流走向。
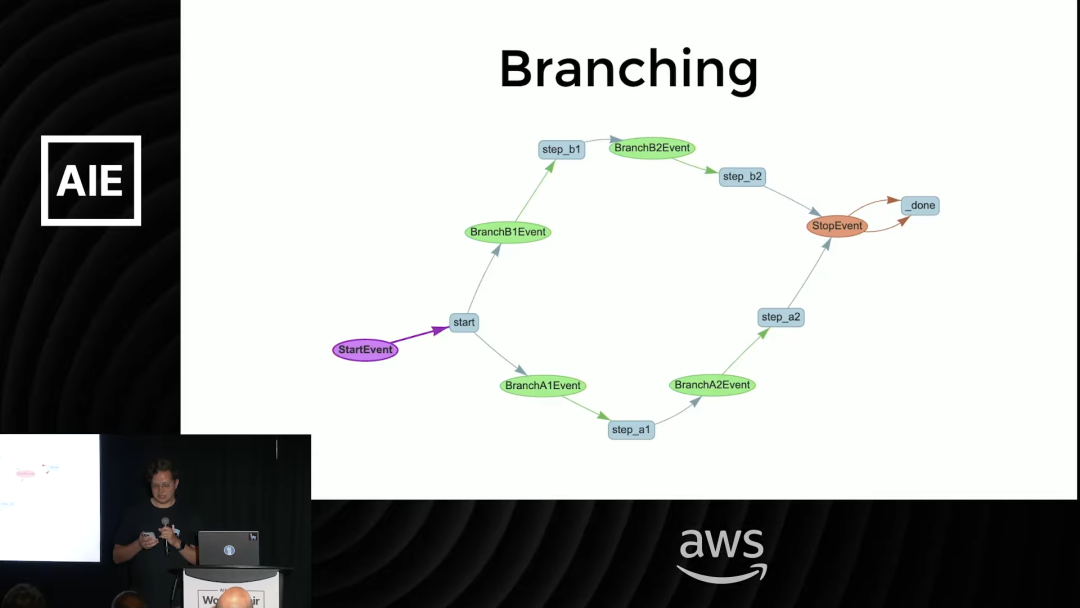
3. 并行化 (Parallelization)
并行化模式的核心是同时运行多个 LLM,然后对它们的结果进行聚合。
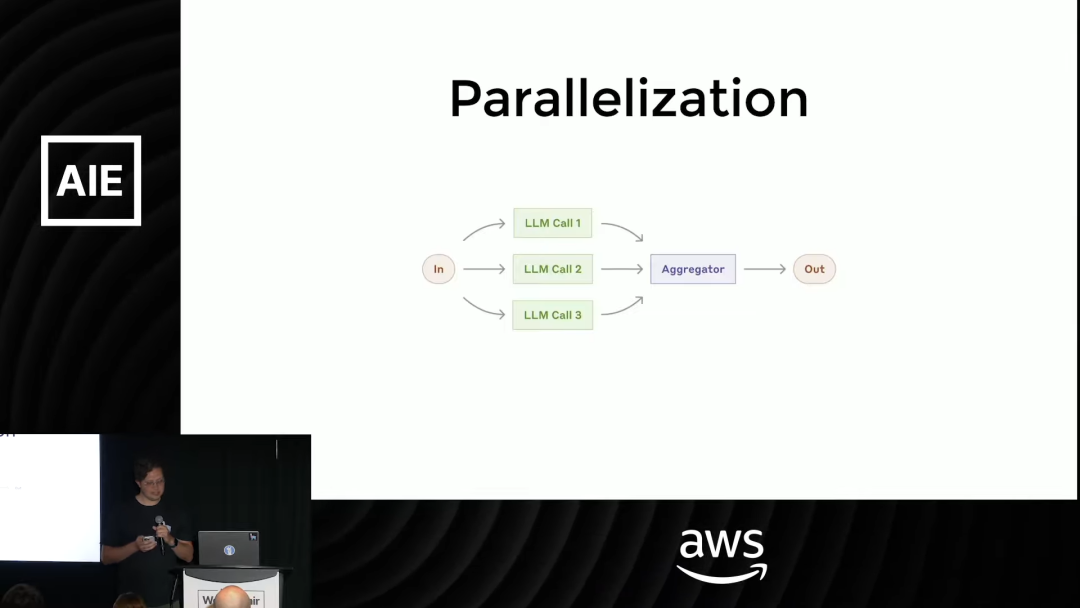
Anthropic 定义了并行化的两种主要方式:
- • 分区/分工: 这指的是对同一个输入,执行完全不同的任务。最经典的例子就是安全护栏 (Guardrails)。
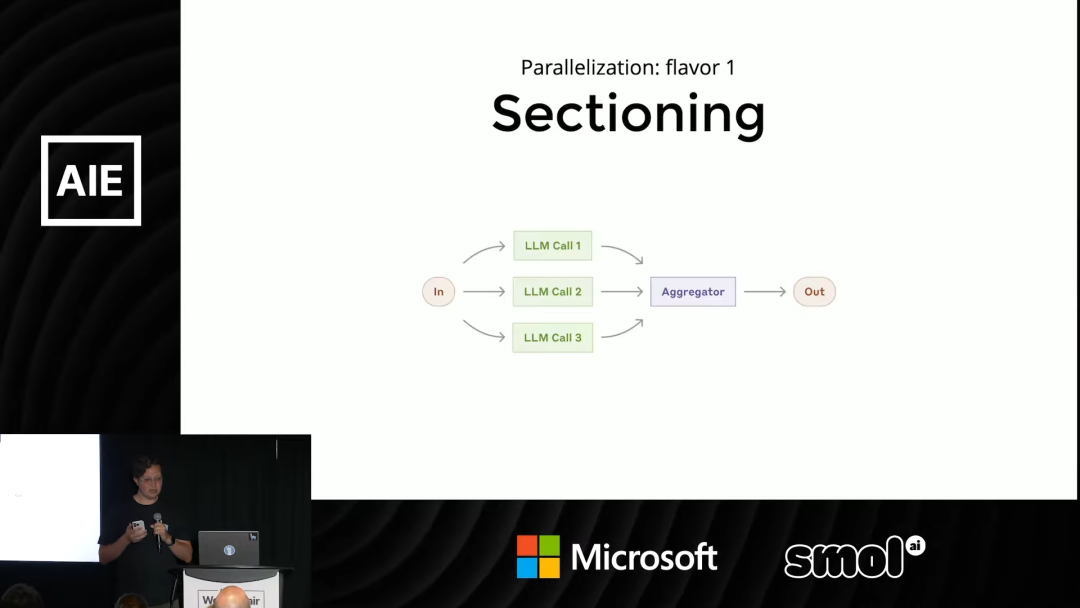
假设用户输入一个请求。系统可以并行启动两个任务:
- • 轨道一(处理):正常执行用户的请求,比如回答问题或生成代码。
- • 轨道二(审查):审查用户的请求是否包含恶意、非法或违反规则的内容。 这两个任务可以同时进行。如果审查轨道发现问题,它可以直接切断处理轨道的输出,从而保证系统的安全性和合规性。
- • 投票: 这指的是将同一个查询,发送给多个并行的处理轨道。
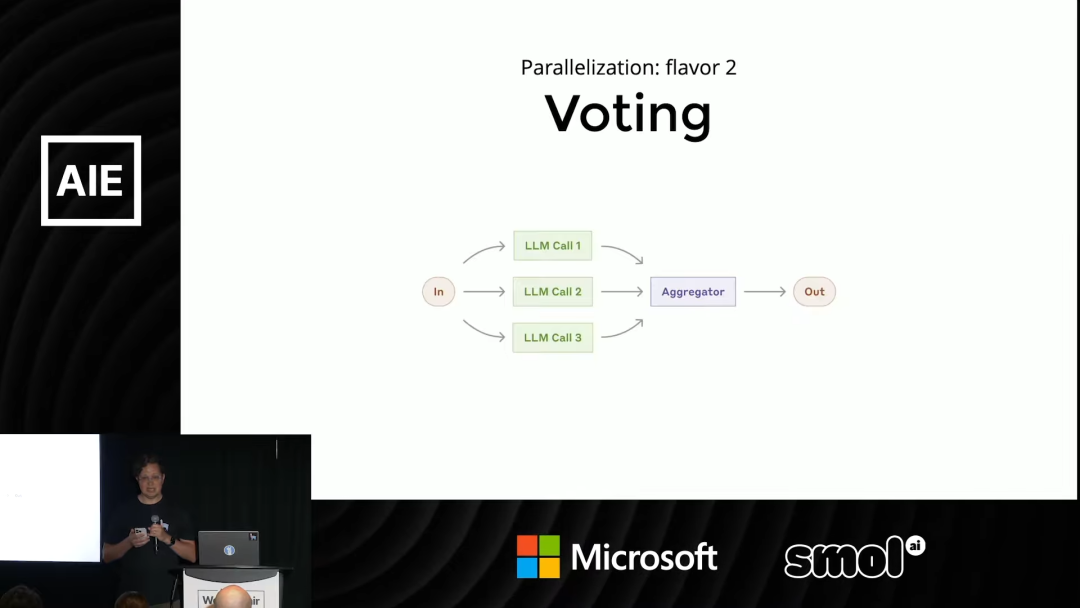
这些轨道可以是完全相同的 LLM(利用其输出的非确定性),也可以是多个不同的 LLM(各有专长)。最后,对所有轨道返回的答案进行聚合,可以采用「少数服从多数」或「全体一致」等策略。这是对抗和减少幻觉 (Hallucination) 的一种绝佳方式。
Laurie 解释道:「LLM 会产生幻觉,但它们产生幻觉的方式各不相同。让三个不同的 LLM 对同一个事实产生一模一样的幻觉,这种概率极低。」
因此,如果多个独立的 LLM 都得出了相同的结论,那么这个结论的可信度就大大提高了。
在 LlamaIndex Workflows 中,可以通过并发 (concurrency) 机制,让一个节点同时发出多个事件,然后在下游的一个节点收集所有事件的结果,从而轻松实现并行化。
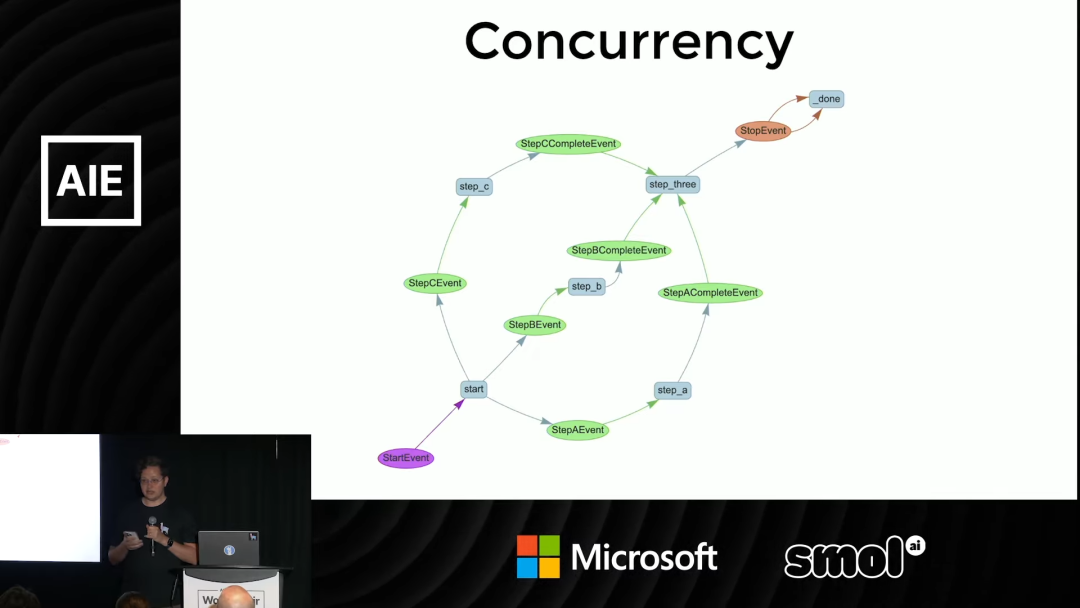
4. 调度器-工作单元 (Orchestrator-Workers)
这是并行化模式的一种高级应用。
在这个模式中,一个上层的「调度器 LLM」(Orchestrator) 负责分解复杂任务。它会审视一个宏大的、多部分的问题,将其拆解成若干个更简单、可以独立解决的子问题。
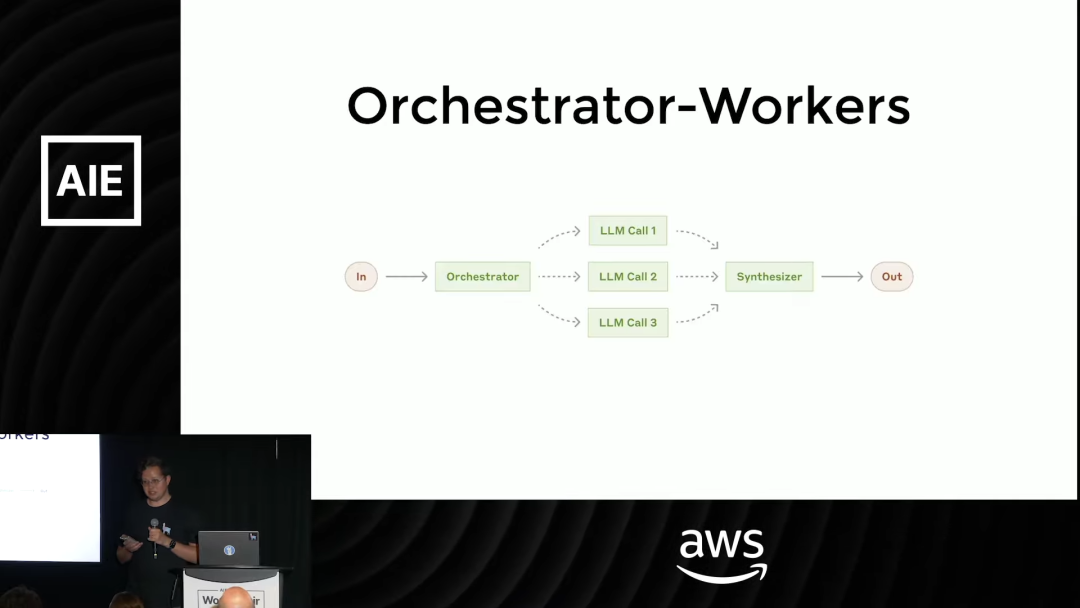
然后,这些子问题被分发给多个并行的「工作单元 LLM」(Workers) 去执行。每个 Worker 专注于解决自己的那个小问题。
最后,所有 Worker 的答案被收集起来,由调度器或另一个聚合 LLM 进行汇总,形成一个全面、连贯的最终答案。
「这就是深度研究 (deep research) 的工作原理」,Laurie 说。这种模式非常强大,能够应对那些需要多角度、多层次信息检索和分析的复杂查询。
5. 评估-优化 / 自我反思
在这个模式中,你可以让一个 LLM 去评判另一个(甚至是它自己)的工作质量。
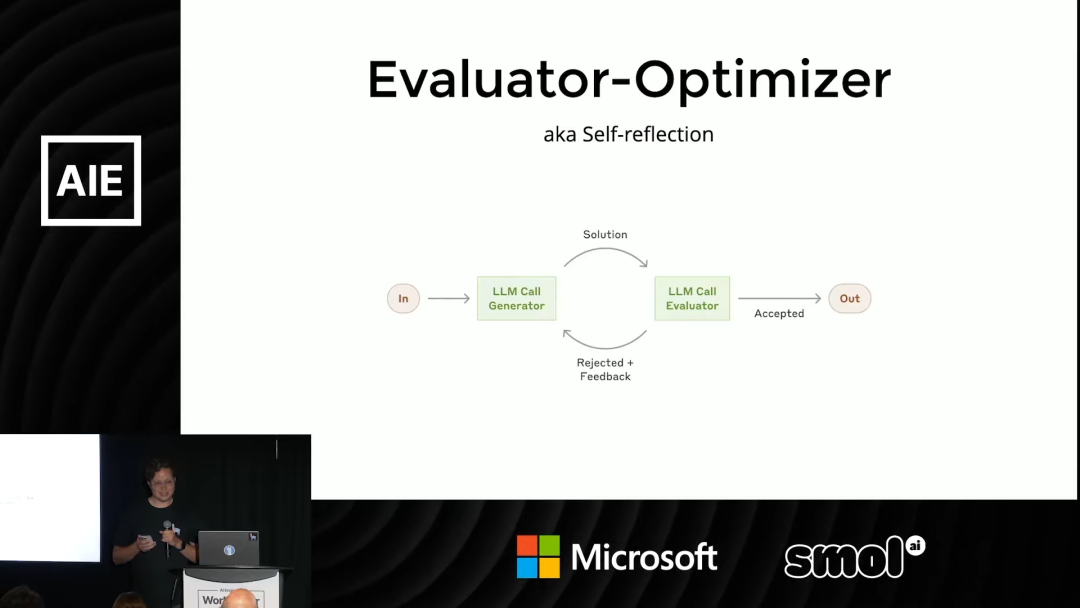
具体流程是:
- 1. 初始 LLM 生成一个输出。
- 2. 将这个输出,连同最初的问题和目标,一起交给一个「评估器 LLM」。
- 3. 评估器 LLM 会判断:「这个输出是否准确地回答了问题?是否达成了预设目标?有没有遗漏关键点?有没有产生幻觉?」
- 4. 如果评估器认为输出不合格,它可以生成具体的反馈,并将任务连同反馈信息一起打回给第一个 LLM,让它「返工重做」。
通过这种方式,系统形成了一个反馈循环。Agent 可以在一次执行中不断迭代、优化自己的答案,直到满足评估标准为止。
在 LlamaIndex Workflows 中,实现循环就像创建一个 Python 的 for 或 while 循环一样简单,可以将工作流指回第一步,开启新一轮的优化。
真正的力量在于组合。 Laurie 强调,你可以将这五大模式任意组合,构建出能够应对任何复杂场景的、极其强大的工作流。
LlamaIndex 如何化繁为简
理论很丰满,实现起来是否复杂?LlamaIndex 的目标就是让这一切变得简单。
- • 定义工具 (Tool):在 LlamaIndex 中,一个工具就是一个被特定装饰器包裹的普通 Python 函数。Agent 会自动识别并知道如何调用它。
- • 构建多智能体系统 (Multi-Agent System):这是 Agent 领域的另一个前沿。你可以创建多个各司其职的 Agent,每个都有自己的系统提示 (system prompt)、LLM 和专属工具集。然后,将这些 Agent 组成一个团队,让它们互相协作,传递控制权来解决一个更大的问题。
在 LlamaIndex 中构建一个多智能体系统有多简单?Laurie 表示:
「这只需要一行代码。」
你只需创建一个 FnAgent 列表,然后将它喂给一个多智能体控制器,剩下的交给框架处理。
结语:超越 Chatbot,拥抱未来
构建一个稳定、可靠、高效的生产级 Agent,并非遥不可及的魔法,而是遵循一套扎实的工程学设计原则的成果。
核心思想就是为 LLM 的不确定性引入结构和指导,通过分而治之、并行验证和自我迭代,将单一 LLM 的能力上限层层放大,同时又有效抑制了其固有的缺陷(如幻觉)。
正如 Laurie 所强调的,AI 应用的未来远不止于聊天界面。真正的蓝海,在于将 LLM 处理非结构化信息的能力,像水和电一样,无缝集成到我们现有和未来的所有软件系统中。
而掌握了这些设计模式的开发者,无疑将是塑造这个未来的主力军。
如果你想亲手实践,Laurie 提供了一个完整的 Agent Workflow 教学 Notebook,可以指导你构建一个深度研究型 Agent:
bit.ly/deep-research-notebook
是时候动手,让你的 Agent 告别摇号中奖,迈向真正的可靠可用了。
参考来源
Effective agent design patterns in production — Laurie Voss, LlamaIndex | https://www.youtube.com/watch?v=72XxWkd8Jrk
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号