别再秀微服务、分布式了!硅谷资深工程师揭秘:好的系统设计,都「无聊」透顶

别再秀微服务、分布式了!硅谷资深工程师揭秘:好的系统设计,都「无聊」透顶

不二小段
发布于 2026-04-09 18:01:11
发布于 2026-04-09 18:01:11
你是否也刷到过这样的帖子:「你肯定没听说过用队列吧?」,或者在社交媒体上看到这样的论断:「如果你还在数据库里用布尔值,那你就是个糟糕的工程师!」?
这些看似高深、实则片面的「系统设计建议」如今在技术圈里屡见不鲜。
甚至,一些公认的经典,比如《设计数据密集型应用》,虽然是好书,但对于工程师日常遇到的大多数系统设计问题来说,可能也有些「杀鸡用牛刀」。
那么,到底什么是好的系统设计?
最近,一篇名为 「我所知道的关于优秀系统设计的一切」(Everything I know about good system design)的博文在国外上爆火。
作者 Sean Goedecke 是一位经验丰富的工程师,他用朴实无华的语言,提出了一个重要的观点:
好的系统设计,往往是「无聊」的、看起来平平无奇的。
Sean 认为,如果软件设计是关于如何组织代码,那么系统设计就是关于如何组合服务。
软件设计的原语是变量、函数、类;而系统设计的原语则是应用服务器、数据库、缓存、队列、事件总线等等。
这篇文章不是一份面试八股,也不是什么高深理论。它更像是一位资深老兵的经验之谈,充满了在真实世界里摸爬滚打后沉淀下来的智慧。
接下来,就让我们跟随 Sean 的思路,深入探索这门「无聊」设计的艺术。🚀
好的系统设计,看起来都「平平无奇」
Sean 开篇就抛出了一个反直觉的观点:好的系统设计是自我消除的。
当你感觉到「嗯,这事比我想象的要简单」,或者「我从来不用操心系统的那个部分,它一直很稳」,那么你就正身处一个优秀的设计之中。
与之相反,糟糕的设计往往看起来更「令人印象深刻」。
我总是对那些看起来很唬人的系统保持警惕。如果一个系统用上了分布式共识机制、多种事件驱动通信、CQRS 等等各种花哨的技巧,我就会怀疑,这是不是为了弥补某个根本性的错误决策,或者干脆就是过度设计了。
这个观点在工程师社区引发了强烈的共鸣。大家纷纷表示,复杂系统往往反映了优秀设计的缺席。
当然,有些业务场景确实需要极致的复杂性,但 Sean 强调了一个黄金法则:
一个能正常工作的复杂系统,总是从一个能正常工作的简单系统演化而来的。
从零开始直接构建一个复杂的系统,几乎注定会走向灾难。
万恶之源:状态管理
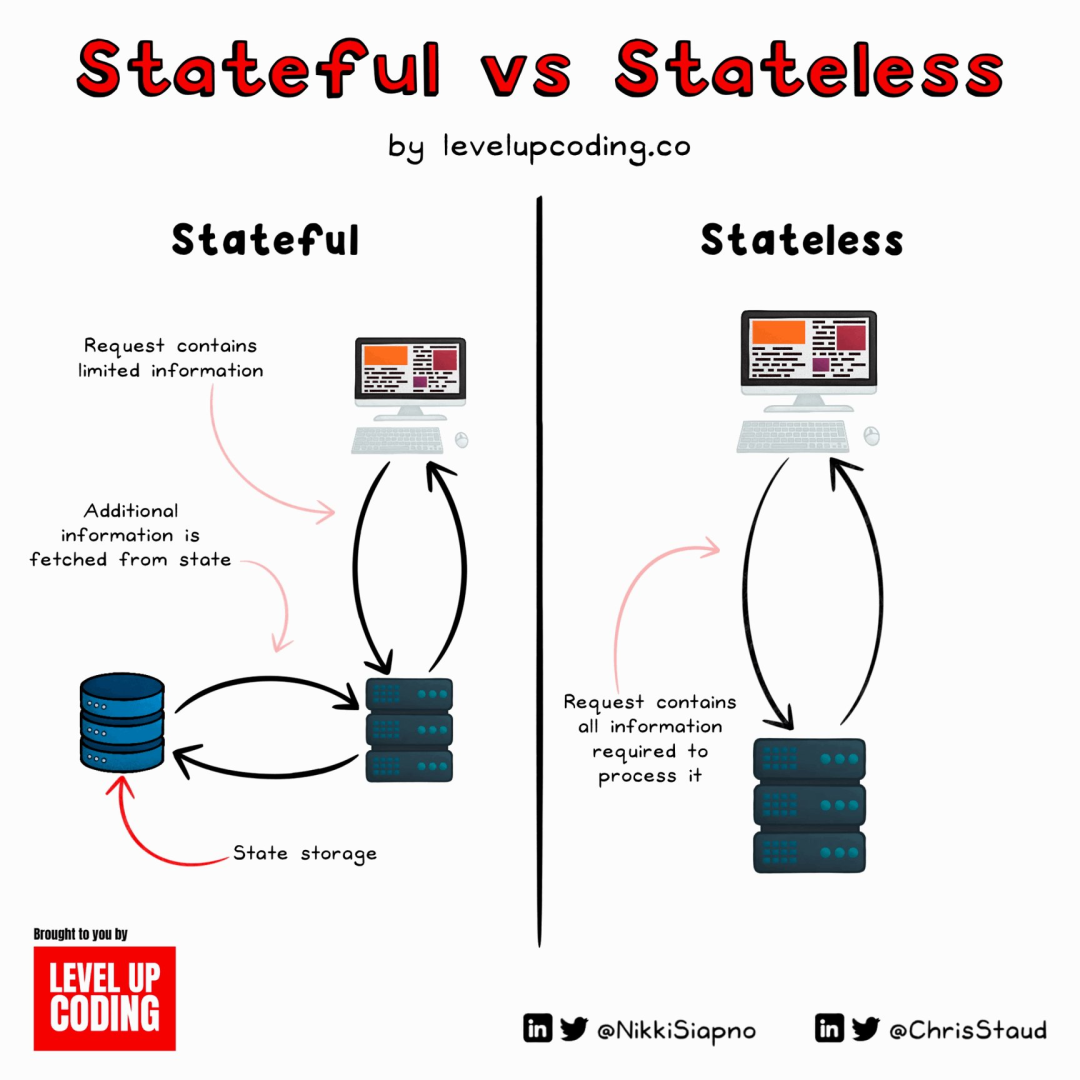
Sean 指出,系统设计中最困难的部分,就是状态(State)。
如果你需要存储任何信息,哪怕只是一小会儿,你都得做出一系列棘手的决策。反之,如果你的应用不存储持久化信息,它就是无状态的(stateless)。
一个典型的无状态服务例子是:GitHub 内部有一个 API,接收一个 PDF 文件,返回它的 HTML 渲染版本。这种服务可以无限次地重启,只要挂了,容器管理器会自动拉起一个新的实例,一切恢复正常。
但有状态的(stateful)服务就没这么简单了。
有状态的组件会进入糟糕的状态(bad state)。
如果你的数据库里出现了一条格式错误的数据,导致应用崩溃,你不能简单地重启了事,必须手动介入修复。如果数据库磁盘满了,你也得想办法清理或扩容。
因此,Sean 提出的核心原则是:
尽可能减少系统中的有状态组件。
在实践中,这意味着你应该让一个服务专门负责管理状态(即与数据库交互),而其他服务则处理无状态的计算任务。
要避免五个不同的服务同时写入同一张表。
Sean 建议,应该让其中四个服务通过 API 请求或发送事件给第五个服务,将所有写入逻辑都收敛到这一个服务中。这能极大地简化系统的复杂度和潜在的并发问题。
系统设计的核心与最大争议:数据库
既然状态管理是核心,那么存储状态的数据库自然就是系统设计中最重要的组件。这一部分,也在 Hacker News 上引发了最激烈的辩论。
争论点一:多个服务应该共享数据库吗?
Sean 的观点很明确:不应该。应该用一个服务作为数据库的代理,其他服务通过 API 与之通信。
但有网友提出了强烈的反对意见。他认为,这种做法的权衡远非显而易见:
- • 直接访问数据库:
- • 优点:数据库本身就是一个成熟的、经过战斗考验的接口。它自带事务、权限控制、强大的查询能力。你不需要自己去设计和实现这些。
- • 缺点:服务与数据库模式强耦合。
- • 通过 API 服务访问:
- • 优点:服务间解耦,数据库模式的变更被限制在单个服务内部。
- • 缺点:你需要自己实现一套 API、访问控制、事务补偿策略等。这会引入更多的故障点和「微服务税」。
一位亚马逊的工程师现身说法,表示在亚马逊,高层曾明确规定禁止任何团队写入共享的 DynamoDB 表。每个团队必须为自己的数据提供 API。这一决策极大地提升了可靠性和开发速度。
这个争论的本质其实是耦合边界的问题。正如一位网友所总结的:
如果所有访问共享数据库的服务都由同一个团队维护,那么这种模式在很长一段时间内都是可行的。但如果涉及到跨团队协作,紧耦合就会成为问题的根源和瓶颈。
争论点二:数据库 JOIN vs. 应用层 JOIN
Sean 的建议是:「在查询数据库时,就让数据库干活。比如,用 JOIN 替代多次查询然后在内存中拼接数据。」
这几乎是数据库使用的第一准则。然而,在「高可扩展」系统成为主流的今天,这个观点也遭到了挑战。
一位网友认为:
在现代高可扩展架构中,我更倾向于在后端应用层做 JOIN。因为后端应用是无状态的,可以轻易地水平扩展,而数据库的扩展则要困难得多。
他的逻辑是,通过简单的索引(如 user_id)从数据库加载数据,然后在应用层进行拼接,可以将数据库的压力降到最低。甚至,可以把拼接逻辑进一步推到前端,这样数据可以被高度缓存,从而释放更多服务端资源。
当然,这种「反模式」有其适用场景。对于绝大多数业务,单个 PostgreSQL 或 MySQL 实例的性能已经绰绰有余,垂直扩展(升级硬件)的成本远低于水平扩展带来的架构复杂性。
总结一下:
- • 默认规则:尽可能使用数据库的
JOIN,让数据库做它最擅长的事。 - • 例外情况:当
JOIN导致数据量爆炸性增长、数据库成为瓶颈、或者你需要跨多个数据源进行关联时,应用层JOIN是一个值得考虑的、务实的选择。
争论点三:ORM 的「原罪」
由 JOIN 引发的,是另一场经久不衰的圣战:ORM (Object-Relational Mapping) vs. 原生 SQL。

评论区里,许多开发者痛斥 ORM,认为它隐藏了数据库的细节,导致了臭名昭著的 N+1 查询问题,并且让开发者失去了对 SQL 的掌控力。
所谓 N+1 问题,简单来说,就是你先用一条 SQL 查询出 N 条主记录(比如100个用户),然后在一个循环里,为每一条主记录都单独执行一条 SQL 去查询其关联数据(比如每个用户的订单),最终导致执行了 N+1 条 SQL,性能极差。

然而,也有大量开发者为 ORM 辩护。他们认为,现代 ORM 已经提供了成熟的方案来避免 N+1 问题。使用 ORM 可以极大地减少样板代码,提升开发效率,并且在大多数 CRUD 场景下表现良好。
关键不在于用不用 ORM,而在于是否理解 ORM 的工作原理,并知道何时应该「跳出」 ORM,手写原生 SQL 来处理复杂查询。
快慢分离:后台任务与缓存的艺术
一个系统里,有些操作必须快(如用户交互的 API 响应),有些操作则天生就很慢(如转换一个巨大的 PDF 文件)。
处理这个问题的通用模式是:分离出能为用户提供即时价值的最小工作单元,将其余部分放入后台异步处理。
后台任务
这是系统设计的一个核心原语。几乎所有科技公司都有一套后台任务系统,通常由两部分组成:
- 1. 队列(Queue):通常用 Redis 或类似技术实现。
- 2. 任务执行器(Job Runner):一个或多个服务,从队列中取出任务并执行。
当你需要执行一个慢操作时,只需将一个类似 {job_name, params} 的消息推入队列即可。
对于需要延迟很久才执行的任务,Sean 提供了一个实用的技巧:
- • 在数据库中创建一个任务表,包含任务参数和一个
scheduled_at字段。 - • 用一个每日运行的定时任务去扫描这张表,捞出到期的任务并执行。
缓存(Caching)
当一个慢操作的结果对于多个用户是相同的,缓存就派上用场了。你可以将结果缓存几分钟,避免每次都去执行昂贵的计算或 API 调用。
Sean 再次提出了一个深刻的观察:
初级工程师了解缓存后,什么都想缓存。而高级工程师则尽可能少地使用缓存。
为什么?因为缓存是另一种形式的状态。它可能会有脏数据,可能与真实数据不同步,可能因为返回了过时数据而引发神秘的 bug。
使用缓存前的黄金法则:先尽力优化! 比如,为一个慢 SQL 查询加索引,远比直接缓存这个查询结果要明智。
系统间的沟通之道:事件、推送与拉取
除了后台任务系统,大公司通常还有一个事件中心(Event Hub),最常见的实现是 Kafka。
事件(Events)
事件中心本质上也是个队列,但它传递的不是「执行这个任务」的指令,而是「某件事发生了」的通知。
经典例子是「新用户注册」事件。当一个新用户创建账户时,系统会发布一个事件。然后,多个下游服务可以订阅这个事件并各自采取行动:
- • 一个服务负责发送欢迎邮件。
- • 一个服务负责进行风险扫描。
- • 一个服务负责初始化用户的基础设施。
这种模式实现了服务间的解耦。但 Sean 提醒,不要滥用事件。很多时候,一个简单的服务间 API 调用更直接、更易于追踪和调试。
推(Push)vs. 拉(Pull)
当一份数据需要被分发到很多地方时,你有两种选择:
- • 拉(Pull):消费者主动向数据源请求数据。这是 Web 的基本工作模式。缺点是可能产生大量重复请求。
- • 推(Push):数据源在数据更新时,主动将新数据推送给所有已注册的消费者。Gmail 就是这样工作的,新邮件会自动出现,无需刷新。
选择哪种模式,取决于数据变化的频率、消费者数量、以及对数据实时性的要求。
为失败而设计:日志、熔断与优雅降级
一个好的系统,不仅要在正常时工作良好,更要在异常时表现得体。
日志与指标
在异常路径上疯狂打日志。
- • 当你的代码因为某个条件检查而返回 422 错误时,把触发的那个条件记下来。
- • 当你的计费代码决定不为某个事件收费时,把原因记下来。
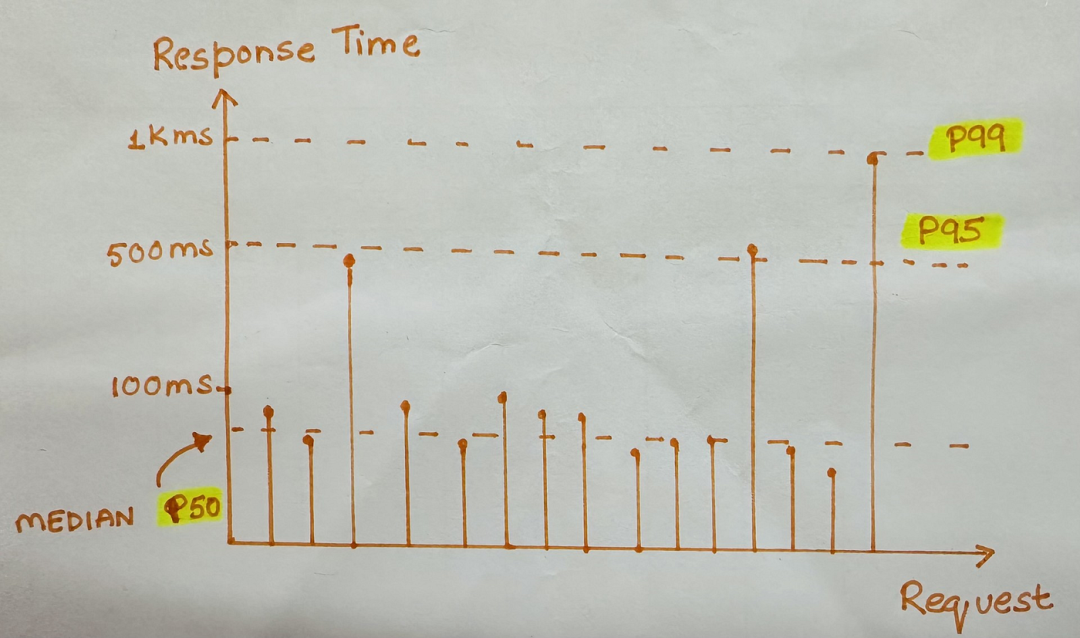
在指标方面,除了关注平均响应时间,更要关注 p95 和 p99,即最慢的那 5% 和 1% 的请求耗时。这些慢请求往往来自你最大、最重要的客户。
熔断、重试与幂等性
- • 重试不是万能药:应该使用熔断器模式,当连续收到过多错误时,暂停发送请求一段时间。
- • 幂等性:对于写操作的重试尤其危险。经典的解决方案是使用幂等键(Idempotency Key),一个唯一的请求 ID,避免重复执行操作。
优雅降级:Fail-Open vs. Fail-Closed
当系统的某个部分失败时,应该如何应对?
- • Fail-Open(失败时放行):例如限流服务,当它故障时应该放行所有请求,避免导致整个产品宕机。
- • Fail-Closed(失败时阻断):例如认证授权系统,当它故障时必须阻断所有请求,安全第一。
这个权衡需要根据具体功能的性质来决定。
面试中的「表演式设计」
上面说的大道理大家都认可,但一个非常现实的问题被 Hacker News 上的网友辛辣地指了出来:这套「简单为王」的哲学,在面试中可能会让你直接挂掉。
他分享了自己的惨痛经历:
- • 面试官:「那服务间的背压问题你怎么考虑?」
- • 我:「这点 QPS 根本不需要考虑这个问题。」
- • 面试官:「这里为什么不用队列(queue)而是用定时任务(cron job)?」
- • 我:「我觉得对于这个 App 的需求来说没必要,不过我可以分析一下两者的权衡……」
- • 面试官:「你会在 SQL 和 NoSQL 之间怎么选?」
- • 我:「关系不大,团队对哪个更熟悉就用哪个。」
结果可想而知。面试官想要的,往往是让你在白板上画满复杂的箭头和框框,直到它看起来像是「用 Kubernetes 去管理你的 Kubernetes」。
另一位网友补充道,这正是所谓的「LinkedIn 驱动开发」存在的根源。在简历上列出一大堆时髦的技术,远比描述你如何用一个单体应用和单个 PostgreSQL 实例就搞定一切,更能吸引招聘者的眼球。
这无疑是行业的一大讽刺:我们追求简单的、可维护的系统,但评价体系却在鼓励复杂的、简历驱动的方案。
总结:返璞归真,无聊才是王道
回到文章的起点,Sean 强调:
好的系统设计,不是关于各种花哨的技巧,而是关于知道如何在正确的地方使用那些无聊的、经过充分测试的组件。
他打了一个比方:好的系统设计就像好的管道工程。如果你搞得太「激动人心」,那最终很可能会弄得自己满身都是秽物。
在大公司里,这些「无聊」的组件都已是现成的基础设施。好的系统设计,就是像搭乐高一样,把它们正确地拼在一起。
这或许是所有开发者都需要内化的核心思想:我们的目标不是构建一个能写进简历的、看起来很厉害的系统,而是构建一个能在后台默默无闻、稳定运行数年而无人问津的系统。
这,才是系统设计的真正艺术。
那么,对于这套「无聊哲学」,你有什么看法?欢迎在评论区分享你的观点!
参考来源(推荐阅读)
- • https://www.seangoedecke.com/good-system-design/
- • https://news.ycombinator.com/item?id=44921137
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号