大模型是迷失方向?强化学习之父 Rich Sutton 提出最新 OaK 架构,通往超级智能的新宏图

大模型是迷失方向?强化学习之父 Rich Sutton 提出最新 OaK 架构,通往超级智能的新宏图

不二小段
发布于 2026-04-09 18:10:26
发布于 2026-04-09 18:10:26
当 AI 行业还在追逐大模型的 Scale law 时,一位学界泰斗却发出了警示:
在某种程度上,人工智能行业已经迷失了方向。
说出这句评价的,不是别人,正是 Rich Sutton。
作为强化学习之父、图灵奖得主,Sutton 在 RLC 2025 的讲台上,再次抛出了一套宏大的构想,直指 AI 的终极问题——超级智能如何从经验中涌现?

Rich Sutton, The OaK Architecture: A Vision of SuperIntelligence from Experience - RLC 2025
他将其命名为「橡树」架构——OaK (Options and Knowledge) Architecture。
这不仅仅是一个技术框架的发布,更像是一篇檄文。它深刻地批评了当前 AI 领域对大规模语言模型的路径依赖,并试图将研究的焦点重新拉回到那个最经典也最核心的命题上:
我们究竟该如何创造一个能够像我们一样,通过与世界互动、在生命周期中不断学习和成长的智能体?
Sutton 认为,要回到通往「真正智能」的正确轨道上,我们需要:
- • 能够持续学习的智能体。
- • 能够建立世界模型并进行规划。
- • 能够学习高层次、可学习的知识。
- • 能够实现元学习泛化。
而 OaK 架构,正是他对上述所有需求的回应。让我们一起学习一下 Sutton 描绘了怎样不同的路线图。
一切的起点:AI 的伟大远征与「大世界」假说
在演讲中,Sutton 重新定义了 AI 研究的终极目标。
他将其形容为一场「伟大的远征」,其重要性堪比地球生命的起源。因为我们不仅是在制造强大的工具,更是在理解「心智」本身。
最大的瓶颈,说来奇怪,是我们缺乏足够的学习算法。我们现有的算法,包括深度学习,都还非常粗糙。
Sutton 建立了一个宏大的世界观,这个世界观是他所有思考的基石。他将其称为「大世界视角」。
这个视角的核心思想简单而深刻:世界远比智能体本身庞大和复杂得多。
世界包含了数十亿其他智能体,包含了所有的原子和物体的复杂细节。你朋友、爱人、甚至敌人头脑中发生的事情,都与你息息相关。
在这个「大世界」中,智能体永远不可能获得关于世界的完整、精确的知识。
因此,它的价值函数必然是近似的,策略是次优的,对世界的模型也必然是高度简化的。更重要的是,由于智能体无法观察到世界的全部状态,这个世界在它看来必然是非平稳的。

这个看似简单的假设,却直接引出了 Sutton 对当前 AI 发展路径的第一个核心批判:设计时 vs. 运行时。

- • 设计时:指的是在工厂里、在模型发布前,由人类工程师将知识和能力构建到智能体中的阶段。
- • 运行时:指的是智能体被部署到真实世界后,通过与环境的实时交互来学习和成长的阶段。
Sutton 毫不客气地指出:
一个大型语言模型,所有的事情都在「设计时」完成了。当它被部署到世界上使用时,它什么也不做 (指不再学习)。
他的观点非常明确:所有重要的事情都必须在「运行时」完成。
为什么?因为在一个「大世界」里,你不可能在「设计时」预见到智能体将要面对的所有情况。

一个家用机器人,它需要记住主人的名字、工作项目的内容、同事是谁,这些信息不可能预先内置在它的「领域知识」里。它必须在「运行时」去学习、去适应。
这自然地引出了 Sutton 多年前提出的著名论断——「苦涩的教训」 (The Bitter Lesson)。

我们想要构建的,是能够像我们一样去发现的智能体,而不是包含了我们已经发现的东西的智能体。
LLM 在某种意义上,正是「包含了我们已经发现的东西」的极致体现。它通过在「设计时」吞噬海量的人类知识文本,构建了一个庞大的知识库。但它却缺乏在「运行时」发现新知识、形成新抽象的能力。
Sutton 认为,这是一种本末倒置。真正的智能,其核心能力应该是在「运行时」的学习,而「设计时」提供的,只应该是那些最通用的、能够支持这种学习的「元方法」。
然而,他也指出了当前「运行时学习」所面临的巨大技术瓶颈:灾难性遗忘和可塑性的丧失。今天的深度学习方法在持续学习方面表现得并不好。
这便是 Sutton 抛出的时代之问:当整个行业都在为 scaling law 欢呼,将 LLM 的参数竞赛推向新高潮时,我们是否忽略了通往真正智能所必需的、更根本的东西?
OaK 架构,就是他给出的答案。
追寻圣杯:为「真智能」立下三大准则
在构建 OaK 架构之前,Sutton 首先清晰地定义了他所追寻的 AI 「圣杯」需要满足的三个核心设计目标。这三大准则支撑起了 OaK 架构的整个哲学思想。
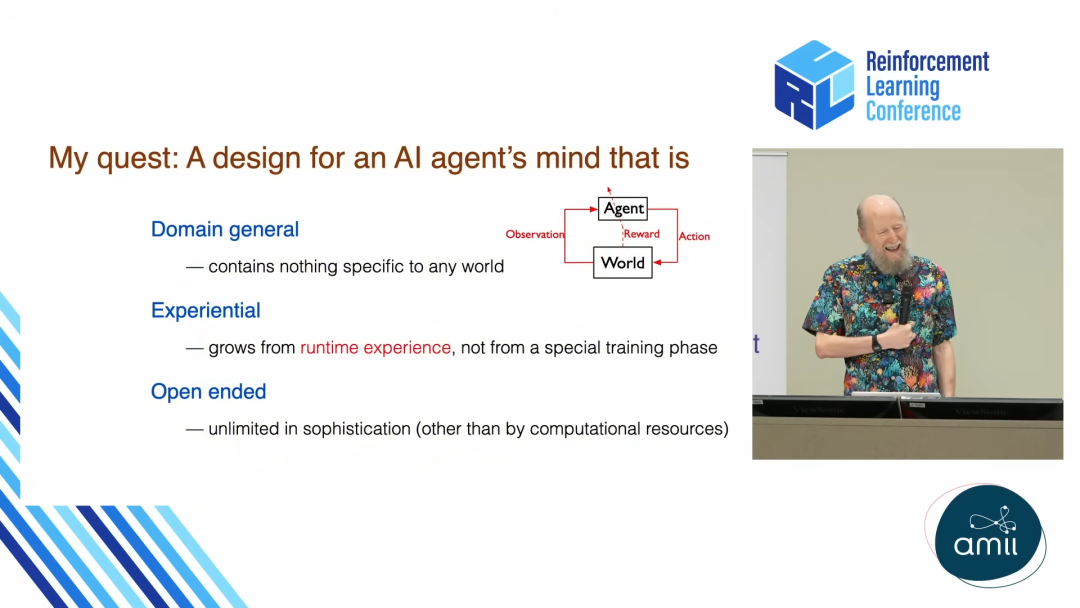
准则一:领域通用
智能体的设计本身,不应该包含任何关于特定世界的知识。

这是一个非常激进但又无比纯粹的目标。Sutton 强调,这并非否定领域知识在具体应用中的价值。如果你想快速开发一个能解决特定问题的应用,内置领域知识当然是高效的。
但如果你的目标是理解「心智」的本质,是寻找一个关于智能如何运作的、简洁而普适的理论,那么你就必须将那些「任意的、内在复杂的外部世界」的细节排除在智能体的核心设计之外。
智能体的任务,正是去学习这个世界中那些「古怪、繁复的细节和高层结构」,而不是将这些细节变成其自身设计的一部分。我们想要的是一个简洁、优雅、能够理解任何世界的智能原理,而不是一个装满了特定世界知识的复杂百科全书。
换句话说:关于特定世界的知识,应该由 AI 自己去学习,而不是被人类工程师「硬编码」进去。
准则二:完全经验主义
智能体的心智,应该完全从「运行时」的经验中生长出来,而不依赖于一个特殊的训练阶段。

这个准则与「设计时 vs. 运行时」的讨论一脉相承。
Sutton 的逻辑非常清晰:既然在一个「大世界」中,智能体必须具备在「运行时」学习、规划、构建和调整抽象概念的能力,那么,为什么不将这种能力作为设计的唯一核心呢?
那些在「设计时」预先构建的能力,或许能让智能体在初期「抢跑」,但从概念的简洁性上来看,一个只依赖「运行时」经验的纯粹设计,无疑是更根本、更优雅的。
既然你必须有能力在运行时完成这些事,那为什么不干脆在一个地方把它们都做了呢?
准则三:开放式抽象
智能体应该能够持续不断地创造出任何它所需要的概念和抽象,其复杂度的上限只受限于其计算资源。
这是通往超级智能的关键。
智能体不能只停留在学习预设的特征或概念,它必须有能力在与世界的互动中,自己发现这个世界的联结,自己定义出新的、更有用的概念,并利用这些新概念去构建更复杂的知识体系。
这个过程必须是开放的、永无止境的。
为了给这三大准则提供一个明确的「目标函数」,Sutton 重申了他坚信不疑的奖励假说。

所有我们所说的目标 (goals) 和目的 (purposes),都可以被很好地理解为对一个接收到的标量信号(我们称之为奖励)的累积和的期望值的最大化。
这个假说,将智能体所有复杂的行为动机,统一到了一个极其简洁的数学框架下。
无论是寻找食物、探索未知,还是进行艺术创作,其根本驱动力都可以被建模为最大化一个单一的标量奖励信号。
在一个足够复杂的世界里,仅仅是最大化一个简单的奖励信号,就足以涌现出我们所认为的智能的所有属性。
至此,Sutton 的「 AI 圣杯」画像已经清晰:一个领域通用的智能体,完全通过运行时经验,在一个开放式的抽象创造过程中,以最大化标量奖励为唯一目标,最终成长为超级智能。
OaK 架构:一棵从经验中长出的智慧之树
有了清晰的目标,我们可以揭开了 OaK 架构的神秘面纱。
首先,让我们来拆解它的名字:OaK = Options + Knowledge。

- • Options (选项):在强化学习中,Option 指的是一个「时间上扩展的动作」,它不仅仅是一个原子动作(如向左走一步),而是一个包含自身策略 (policy) 和终止条件的行为片段(如「走到门口」这个选项)。
- • Knowledge (知识):在 OaK 架构中,知识特指「当你执行某个 Option 后会发生什么」的模型。这是一种更高层次的世界模型,它让你能够以更大的时间步长进行推理和规划。
OaK 的核心,就是让智能体不断地学习新的 Options,并围绕这些 Options 建立起关于世界的 Knowledge,从而让智能体能够在一个更高的、更抽象的层面上理解和规划世界,从而实现「在更大的时间尺度上进行跳转」,并「在世界的关键节点上剖析世界」。
下图是 OaK 架构的整体示意:
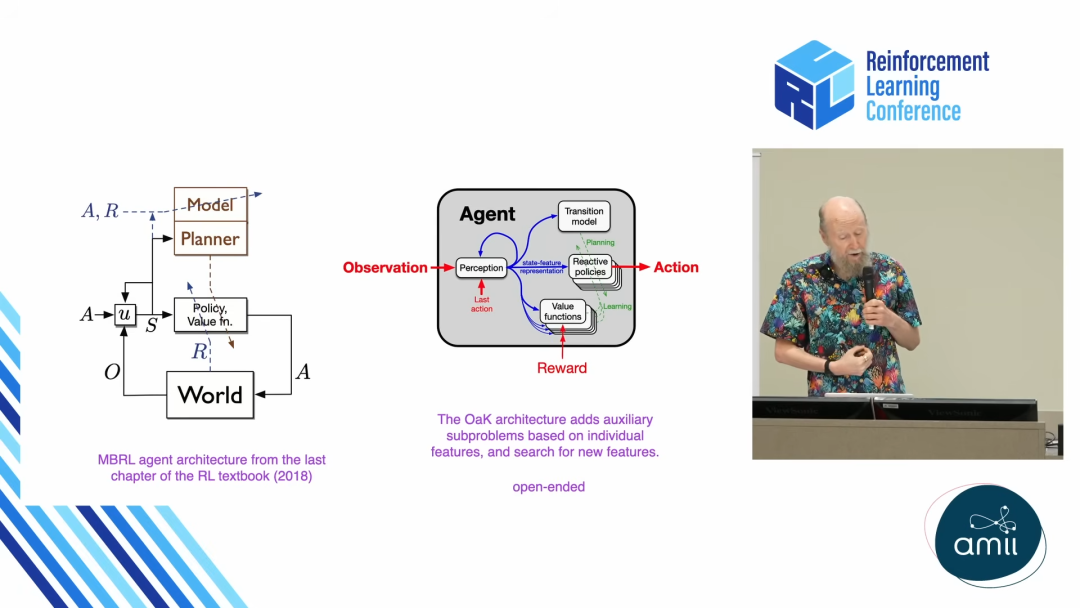
我们可以看到,它包含了经典强化学习智能体的所有组件:从世界接收观察 (Observation) 和奖励 (Reward),输出动作 (Action);内部有策略 (Policy)、价值函数 (Value Function)、世界模型 (Model) 和规划器 (Planner)。
但最关键的不同在于:辅助子问题 (Auxiliary Subproblems)。
Sutton 认为,智能体不应该只有一个由环境给定的主任务(例如最大化奖励信号),它必须能够为自己创造新的、内部驱动的子问题。

这也是一个困扰 AI 和认知科学多年的问题:好奇心、内在动机和「玩耍」的本质是什么?
Sutton 用生动的例子解释了这一点:一只年幼的猩猩在树枝上摆荡,它不是为了获取食物,只是对「摇摆」这种感觉本身产生了兴趣。一个婴儿不断地摇晃拨浪鼓,也不是为了完成某个外部任务,而是为了重现和理解那个有趣的声音。
这些「玩耍」行为,在 Sutton 看来,就是智能体在为自己设定子问题。
那么,这些子问题又从何而来?Sutton 给出了一个极其简洁的机制:从「特征 (feature)」中来。
当智能体在与世界交互时,它的感知系统会构建出世界的「状态特征」。这些特征可以是任何东西:一个明亮的光斑、一个特定的声音、一种特殊的感觉。
OaK 架构的核心思想是,任何一个足够「有趣」的特征,都可以成为一个新子问题的目标。

这个子问题被定义为「尊重奖励的特征达成」。
具体来说,对于某个特征i,智能体会创建一个子问题,其目标是:在不过多损失主任务奖励的前提下,尽可能地让特征i的值变高。
这个定义的精妙之处在于。智能体在追求自己的「小目标」(比如探索有趣的声音)时,不会完全忘记自己的「大目标」(比如生存)。它会在两者之间进行权衡。比如,为了喝到一杯咖啡(达成「咖啡」这个特征),它会寻找一条安全的路径,而不会选择跳下悬崖(这会导致巨大的负奖励)。
通过这种方式,智能体得以源源不断地为自己创造出探索世界的内在动力,从而实现开放式的、永不停止的学习。
智能的「永动机」:OaK 架构的核心发现循环
Sutton 不仅定义了上面的概念,还构建了一个持续发现、持续抽象的「永动机」式的学习循环。
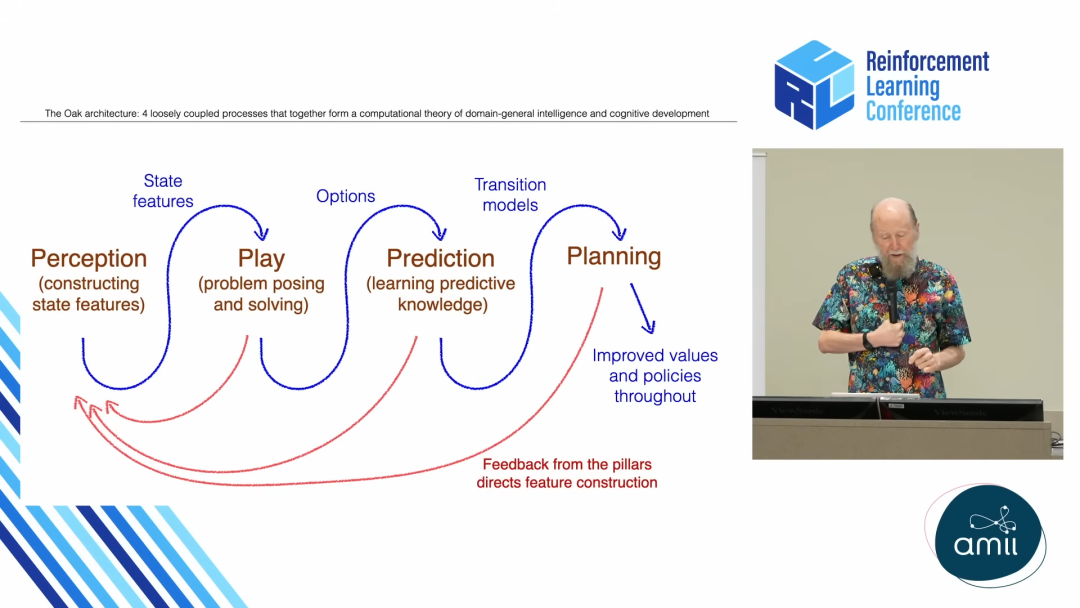
Sutton 将其描述为一个由多个并行步骤构成的运行时循环,这个过程,正是 OaK 架构中那棵智慧之树生长的脉络。

第一步:特征构建
一切始于感知。智能体从与世界交互的原始数据流(观察、动作)中,构建出对它当前所处状态的描述,也就是状态特征。
Sutton 强调,这个过程不是为了逼近某个「人类标注的标签」或者「外部世界的真实状态」,而是为了服务于智能体自身的决策和学习。一个特征是否有用,取决于它能否帮助智能体更好地解决问题。
第二步:提出子任务
智能体内部有一个评估机制,当智能体构建或发现了一个「有趣」的特征后,它会将这个特征本身变成一个新的目标,即一个子任务。
然后,它会基于这些高价值特征,按照我们前面提到的「尊重奖励的特征达成」原则,生成一系列新的子问题。

Sutton 认为,智能体必须能够自己创造自己的子任务,而不是等待人类来设定。
第三步:学习选项
一旦一个子任务被提出,智能体就会利用强化学习的方法,去学习一个能够完成这个子任务的策略,也就是一个 Option。
例如,针对「再次发出摇铃声」这个子任务,智能体可能会学到一个 Option,包含了一系列特定的手臂和手腕动作,以及在听到声音后就终止的条件。
OaK 架构中会同时存在大量这样的 Options,每一个都对应着一个由特征转化而来的子任务。
第四步:模型学习
当智能体拥有了大量的 Options 后,它接下来要做的,就是为每一个 Option 学习一个模型。
这个模型回答的问题是:「如果我在某个状态下,启动『发出摇铃声』这个 Option,世界会发生什么变化?我会到达一个什么样的新状态?在这个过程中会得到多少奖励?」
这是一种高层次、时间抽象的世界模型。它不再是对单步原子动作的建模,而是对整个行为片段 (Option) 的结果进行预测。这使得智能体的规划能力得到了质的飞跃。
第五步:规划
拥有了基于 Options 的高层世界模型后,智能体就可以进行高效的、长远的规划。它可以像在脑中下棋一样,推演执行一系列选项组合的后果,从而找到解决主任务的最佳宏观策略,并以此来更新自己的整体策略和价值函数。

当面临一个新的目标时(比如主线任务的奖励发生了变化),它不再需要从原子动作开始一步步地进行模拟推演,而是可以直接在 Options 的层面上进行「思考」。
「我可以先执行『走到门口』的 Option,然后再执行『打开门』的 Option…」这种基于高层抽象的规划,其效率和深度远非单步规划所能比拟。
Sutton 强调,规划的本质,就是通过模型来让价值函数与世界动态保持一致。
生生不息的「美德循环」
这些步骤并非线性执行一次就结束,它们构成了一个永动的美德循环。
这个循环的关键在于反馈。
当智能体利用学到的 Options 和 Models 进行规划时,它会发现:
- • 某些 Options 对于解决主线任务特别有用。
- • 某些 Options 的模型更容易学习,预测更准。
- • 在学习某个 Option 的策略或模型时,某些底层的状态特征比其他特征更有用。
这些信息会形成一个反馈信号,反过来告诉第一步的「特征构建」模块:哪些类型的特征是「有用的」,哪些是「无用的」。
这个反馈机制,会引导智能体去构建出更多、更好的新特征。而这些新特征,又会成为新一轮「提出子任务」的原材料,从而开启新一轮的 Option 学习、Model 学习和 Planning。
就这样,智能体从解决简单子任务的过程中,发现了构建更复杂子任务所需的特征;又从解决这些复杂子任务的过程中,发现了构建更更复杂任务的特征……
这个循环不断往复,智能体的认知能力和抽象水平就会像滚雪球一样,不断地自我提升,最终形成一个开放式的、没有上限的智能成长阶梯。
这,就是 Sutton 对「超级智能如何从经验中涌现」给出的机械论的回答。
它描绘出的图景告诉我们:智能,本质上是一个自我驱动、自我创造、自我提升的永恒循环。
前路漫漫:缺失的拼图与未来的方向
尽管 OaK 架构的愿景激动人心,但 Sutton 在演讲中也坦诚地指出了实现这一宏图所面临的巨大挑战,以及当前仍然缺失的关键技术拼图。
其中,最关键的两个「老大难」问题,正是开篇提到的:
1. 可靠的持续学习
这是整个 OaK 架构的基石。无论是学习主线任务的价值函数和策略,还是学习成百上千个子任务的 Options 和 Models,所有组件都必须能够在「运行时」持续不断地学习新知识,同时不忘记旧知识。

Sutton 明确指出,我们还没有可靠的、能够用于非线性函数逼近器(即深度神经网络)的持续学习算法。灾难性遗忘的问题,仍然是深度强化学习领域的一座大山。
尽管已经有许多研究方向,但目前还没有一个公认的、能够大规模应用的解决方案。
2. 新特征的元学习
这是「美德循环」的起点,也是最具挑战性的一环。智能体如何从零开始,自动地、创造性地生成那些「有用的」新特征?

这个问题,也被称为「新术语问题」,可以追溯到上世纪 60 年代 Minsky 等 AI 先驱的思考。
Sutton 认为,虽然 1986 年提出的反向传播算法本应解决这个问题,但事实证明,单纯依赖梯度下降来学习表征是远远不够的。
当前的大多数方法都基于「生成与测试」的思想,即随机或启发式地生成大量候选特征,然后通过某种方式(如对下游任务的贡献度)来评估和筛选。但如何设计一个高效、可扩展、且具有创造性的特征生成器,仍然是一个开放性的核心问题。
Sutton 相信,解决这两个问题,将会是未来几年 AI 领域最重要的突破。一旦我们拥有了能够持续学习的深度学习方法,它将「接管人们用深度学习所做的一切」。
结语:回归本源,重拾真正的远征
Rich Sutton 的 OaK 架构,与其说是一个具体的算法,不如说是一个思想纲领,一个研究范式。
它提醒着我们,在追逐模型参数和数据集规模的竞赛中,不要忘记 AI 研究最初的梦想:创造一个能够自主学习、理解和改造世界的智能。
OaK 提供了一套关于心智如何运作的、极具说服力的计算理论:

- • 高层知识如何从底层经验中学习? -> 通过循环。
- • 概念从何而来? -> 来自于为解决子任务而构建的特征。
- • 推理的本质是什么? -> 或许就是基于 Option 模型的规划。
- • 玩耍和好奇心的目的是什么? -> 为了发现并设定那些能够构建我们认知结构的子任务。
- • 感知的目的是什么? -> 为了形成那些能够作为子任务基础的、有用的内部概念,而无需人类标签的监督。
对于整个 AI 社区而言,OaK 提供了一个全新的思考框架,一个可以指导未来几十年研究的宏大愿景。它强调了在当前 LLM 热潮中可能被忽视的关键能力:基于学习模型的规划、根植于经验而非人类标签的感知、以及子问题、选项和特征的自主发现。
OaK 是一份邀请,邀请我们重新思考:什么是真正的学习?什么是真正的智能?
正如 Sutton 在演讲结尾所说,OaK 是一个关于「如何基于经验、在运行时培育出一个超级智能」的愿景。
如果这条路是正确的,那么 AGI 将始于经验,成于循环,通往无限。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号