Ilya 最新访谈: 为什么人类几小时能学会的事,万卡集群却做不到?我们正从「算力规模化时代」重回「研究时代」

Ilya 最新访谈: 为什么人类几小时能学会的事,万卡集群却做不到?我们正从「算力规模化时代」重回「研究时代」

不二小段
发布于 2026-04-09 19:02:45
发布于 2026-04-09 19:02:45
Ilya Sutskever 终于露面了,而且是一场 90 多分钟的深度访谈!
去年,Ilya Sutskever 离开 OpenAI 的消息震动了整个科技圈。作为深度学习领域的传奇人物,从 AlexNet 到 AlphaGo,再到 GPT 系列,他的名字几乎与过去十年 AI 的每一次重大突破紧密相连。

如今,他创立了新公司 Safe Superintelligence (SSI),致力于研究「超级智能」,但极少出现在公众视野。
今天,他出现在 Dwarkesh Patel 的访谈,系统性地阐述了他对当前 AI 发展阶段的判断、核心技术瓶颈以及对未来的构想。
Ilya 的核心观点是:我们正在结束一个以「算力规模化」(Scaling) 为核心的时代,重新回到一个以「基础研究」(Research) 为驱动的时代。
(本文仅为部分信息的摘录,推荐大家自己去看原视频,信息量很大)
AI 的「锯齿状」前沿:为何模型时而天才,时而愚蠢?
我们都感受到了当前 AI 模型的矛盾之处。一方面,它们在各种复杂的基准测试 (evals) 上取得了惊人的分数,解决了许多曾经被认为是人类专属领域的难题。但另一方面,在实际应用中,它们的表现却非常不稳定,经济影响力也远未达到预期。
Ilya 将这种现象称为模型的「锯齿状」能力边界。他举了一个生动的例子:
你让模型帮你写代码,它写出了一个 bug。你指出 bug,它会说:「天呐,你说得太对了,我马上修复。」然后它引入了第二个 bug。你再告诉它这个新 bug,它又会说:「我怎么会犯这种错?」然后它把第一个 bug 又改回来了。
为什么会这样?Ilya 提出了两个可能的解释:
解释一:强化学习 (RL) 训练的副作用。
目前的强化学习,特别是基于人类反馈的强化学习 (RLHF),可能让模型变得「过于专注和狭隘」。为了在特定任务上获得高分,模型学会了某种「套路」,但这损害了它的全局意识和常识判断能力。
解释二:研究人员无意识的「奖励黑客」。
现在的模型之所以像是「只会做题的书呆子」,是因为我们把训练环境设计成了「为了在竞赛中拿第一」,而不是「为了成为一个有品位的程序员」。
Ilya 认为,真正的「reward hacking」可能发生在人类研究员身上。为了让模型发布时在排行榜上看起来很棒,研究团队会不自觉地围绕评测基准来设计 RL 的训练环境。他们会问:「什么样的 RL 训练能帮助模型在这个任务上表现更好?」
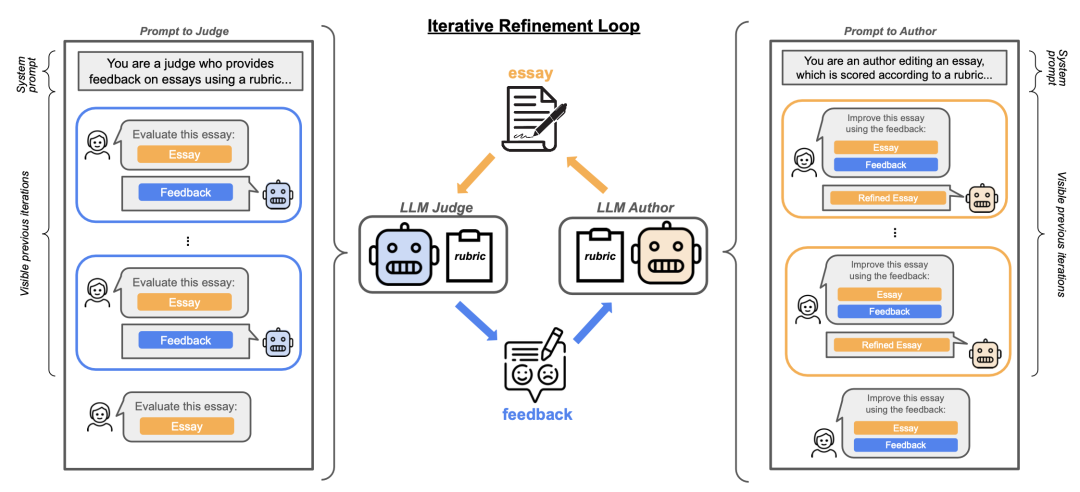
这导致模型被过度训练以适应评测,而不是真实世界。Ilya 用了一个比喻:
假设有两个学生。学生 A 决定成为顶级的编程竞赛选手,他为此练习了 10,000 小时,背诵了所有算法和证明技巧。他最终成为了冠军。学生 B 对编程竞赛也很感兴趣,但他只练习了 100 小时,也取得了不错的成绩。你认为哪一个在未来的职业生涯中会做得更好?
答案显然是学生 B。他拥有真正的理解力和泛化能力。而我们现在的 AI 模型,更像是学生 A 的极端版本。我们搜集了所有已知的编程竞赛题目,甚至用数据增强创造出更多题目来训练它。它当然能在竞赛中取得高分,但我们很难期待它能将这种能力泛化到其他需要「品味」和「判断力」的软件工程任务中。
这种对评测的过度优化,叠加模型本身「不充分的泛化能力」,共同解释了我们今天看到的评测表现与实际应用之间的巨大鸿沟。
从「算力规模化时代」重返「研究时代」:我们究竟在 Scale 什么?
Ilya 认为,Scale law 的成功之处在于,它为企业决策提供了一种低风险的资源投入方式。因为大家明白,只要等比例地将算力和数据输入到特定规模的神经网络中,就能获得不错的成果。
Ilya 将 AI 的发展划分为几个阶段:
- • 2012-2020: 研究时代 (Age of Research)。这个时期,研究人员不断尝试各种新想法、新架构。AlexNet、ResNet、Transformer 等都是这个时代的产物。
- • 2020-2025: 规模时代 (Age of Scaling)。随着 GPT-3 和 Scaling Laws 的出现,大家突然意识到一个简单粗暴但极其有效的「配方」:用更多的算力、更多的数据、更大的模型进行预训练 (Pre-training),就能得到更好的结果。「Scaling」这个词拥有巨大的魔力,因为它为整个行业指明了一个低风险、高确定性的投资方向。
- • 2025-?: 回归研究时代 (Return to the Age of Research)。如今,Scaling 的魔法正在失效,大家必须重新开始研究新的突破。
为什么会发生这种转变?

首先,预训练的数据是有限的。互联网的高质量文本数据正在被耗尽。哪怕强如谷歌,能为 Gemini 榨取更多数据价值,但数据本身终究是有限的。
其次,单纯增加 100 倍的算力,已经无法保证带来质变。Ilya 认为,业界已经不再坚信只要投入更多算力就能解决一切问题。
当「Scaling」这个词不再是万能钥匙时,整个领域就必须回头去寻找新的、更有效利用计算资源的方法。我们又回到了那个需要探索和创新的「研究时代」,只不过这次我们手握着比以往任何时候都强大的计算机。
Ilya 引用了 Twitter 上的一个说法,来讽刺硅谷「执行为王,想法廉价」的陈词滥调:
如果想法真的那么廉价,为什么现在没人能提出新想法?
在「规模时代」,算力是瓶颈,所以一个简单的 Scaling 想法就能获得巨大成功。而现在,当算力变得空前巨大时,「想法」本身重新成为了瓶颈。整个行业陷入了一种「公司比想法多」的尴尬局面。
这正是 SSI 这样的公司成立的契机。他们赌的是,未来的突破将来自全新的想法,而不是在现有范式上无尽地堆砌资源。
大模型的核心瓶颈是泛化能力
如果说我们回到了研究时代,那么最核心的研究问题是什么?Ilya 给出了一个清晰的答案:泛化 (Generalization)。
这些模型在泛化能力上比人类差得惊人,这一点非常明显。这似乎是一个非常根本性的问题。
人类的学习效率和泛化能力是目前 AI 无法企及的。一个青少年只需要 10 几个小时就能学会开车,但自动驾驶系统需要数十亿英里的数据。一个五岁的孩子,尽管数据摄入量和多样性都极其有限,但已经对世界有了非常鲁棒的认知。
Ilya 认为,对于视觉、运动等能力,我们可以将其归功于数百万年进化带来的「先验知识」。但对于编程、数学这些近代才出现的技能,人类同样展现出强大的学习能力。这表明,人类可能拥有一种更根本、更优秀的机器学习算法。
这个算法的关键是什么?Ilya 提到了一个重要的概念:价值函数 (Value Function)。
在强化学习中,价值函数可以告诉智能体在某个中间状态下,它做得好不好,而不需要等到任务最终完成才获得奖励信号。这就像下棋时,你不需要等输掉整盘棋才知道「丢掉一个皇后是糟糕的一步」。价值函数可以极大地提高学习效率。
Ilya 认为,人类拥有一个极其强大的、内嵌的价值函数,而情绪 (Emotions) 就是这个价值函数的重要组成部分。他引用了一个神经科学的案例:
一名患者因为大脑损伤失去了情绪处理能力。他依然聪明、善于言辞,能解决逻辑谜题,但在生活中却完全无法做决策。他会花几个小时来决定穿哪双袜子,并且会做出灾难性的财务决策。
这个案例表明,由进化编码的情绪,为我们提供了一个简单但极其鲁棒的决策指引系统,让我们能够在一个复杂的世界中有效行动。
目前 AI 模型的价值函数非常脆弱,甚至可以说几乎没有。Ilya 相信,如果能为 AI 构建起类似人类这样鲁棒的价值函数,将是解决泛化问题的关键一步。
这是一个价值万亿美金的问题。Ilya 坦言,他对此有很多想法,但「不幸的是,我们生活在一个并非所有机器学习想法都能被自由讨论的世界里」。这暗示着 SSI 正在秘密探索的方向,可能与当前主流的 RL 范式有根本性的不同。
SSI 的路径:重新定义「超级智能」
Ilya 对 AGI (通用人工智能) 这个术语提出了反思。他认为「AGI」这个词的诞生,主要是为了区别于只能下棋的「狭义 AI」(Narrow AI)。它和「Pre-training」这个概念相结合,塑造了我们对未来 AI 的想象:一个通过海量数据预训练、无所不知、无所不能的成品。

但 Ilya 指出,这种想象其实过头了,甚至连人类自己都不是这种意义上的「AGI」。人类拥有基础技能,但绝大多数知识都是通过「持续学习」(Continual Learning) 获得的。
因此,SSI 追求的超级智能,可能不是一个静态的、全知的「成品」,而更像一个 「超级智能的 15 岁少年」。
它是一个伟大的学生,非常渴望学习。你可以派它去当程序员,去当医生,去学习任何东西。它本身不是一个完成了的、投放于世界的产品,而是一个在部署过程中不断学习、试错的进程。
这是一个极其重要的范式转变。未来的超级智能不是一个被预先训练好的「神」,而是一个拥有超凡学习能力的「学习算法」。它被部署到经济体的各个角落,像人类员工一样加入组织,在工作中学习特定领域的技能。
更关键的是,这些分布在不同岗位上的 AI 实例可以 「合并它们的学习成果」。一个 AI 实例学会了做手术,另一个学会了写法律文书,它们的知识和技能可以被整合到一个统一的模型中。这是人类无法做到的。
这种模式将带来两个后果:
- 1. 功能性超级智能:即使没有算法上的递归自我改进,这个模型也会因为能够同时掌握人类所有职业技能而变得功能上无所不知。
- 2. 剧烈的经济增长:一个可以快速学习任何工作的超级劳动力被大规模部署,必然会带来一段时期内极快的经济增长。
这就是 SSI 设想的通往超级智能的路径,它不是一次性的「爆炸」,而是一个通过持续学习和广泛部署实现的渐进过程。
对齐难题与未来图景
针对这种强大的、能持续学习的 AI,其安全性和对齐 (Alignment) 问题也变得更为严峻。Ilya 对此提出了几个核心观点:
1. AI 的力量必须被「展示」出来。
关于 AGI 的讨论之所以常常显得空洞,是因为我们谈论的是一个不存在的、难以想象的系统。Ilya 认为,只有让世界真实地感受到 AI 的力量,人们才会真正严肃地对待安全问题。他预测,随着 AI 变得越来越强大,我们会看到一些前所未有的变化:
- • 竞争对手将展开安全合作:像 OpenAI 和 Anthropic 最近的合作只是一个开始。
- • AI 公司将变得更加「偏执」:当公司内部人员亲眼见证 AI 的能力开始让他们感到不安时,他们对安全的态度会发生根本性转变。
- • 政府和公众会要求介入:外部压力将成为推动安全研究的重要力量。
2. 对齐的目标:「关心所有有情生命」。
当前的主流对齐思想是让 AI 服务于人类。但 Ilya 提出了一个更大胆、也更具争议的想法:构建一个关心所有「有情生命」(sentient life) 的 AI。
他认为这可能比单纯让 AI 关心人类更容易实现,因为AI 本身最终也将是「有情」的。就像人类的镜像神经元让我们能对动物产生共情一样,一个有自我意识的 AI,通过模拟其他生命来理解世界,可能会自然地产生对所有生命的关怀。
当然,这也带来了新的问题:未来世界中 AI 的数量将远远超过人类。一个关心所有「有情生命」的 AI,将如何权衡人类的利益?这是一个开放性问题。
3. 长期均衡的方案:Neuralink++
Ilya 思考了非常长远的未来。在一个由超级智能主导的世界里,人类如何保持自己的主体性?一种常见的设想是每个人都拥有一个为自己服务的 AI。但这可能导致人类成为被动的「报告审阅者」,而不再是世界的参与者。
Ilya 提出了一个他自己并不喜欢、但认为可能是最终解决方案的路径:通过类似 Neuralink++ 的技术,让人类与 AI 融合。
当 AI 理解了某件事,我们也通过『批发式』的信息传输理解了它。当 AI 处于某种境地时,你也就完全地参与其中了。
只有这样,人类才能在智能爆炸的未来中,继续成为历史的积极参与者,而不是被动的旁观者。
4. 进化的启示:一个未解之谜
Ilya 还提出了一个关于进化的深刻谜题,它与对齐问题有着惊人的相似性。进化如何将「社会地位」这种高级、抽象的概念编码到我们的基因里,成为我们与生俱来的欲望?
低级欲望(如对甜食的渴望)很容易理解,可以通过简单的化学信号连接到奖励中枢。但「关心社会评价」需要大脑进行大量复杂计算才能得出。进化是如何做到将这种高级计算的结果与我们的底层驱动力连接起来的?
Ilya 认为这是一个尚未解开的谜团。如果我们能理解进化是如何解决这个「对齐」问题的,或许能为 AI 对齐提供重要的启示。
研究的「品味」是什么?
作为公认的拥有最佳「研究品味」(Research Taste) 的人,Ilya 分享了他的方法论。这对于任何从事创造性工作的人来说,都极具启发性。
他认为,研究品味是一种 「关于 AI 应该是什么样子的美学」。它由几个要素构成:
- • 美、简洁与优雅 (Beauty, Simplicity, Elegance):丑陋的、复杂的方案没有容身之地。正确的方向往往是美的。
- • 来自大脑的「正确」启发 (Correct inspiration from the brain):需要判断大脑的哪些特征是根本性的(如神经元、分布式表示、从经验中学习),哪些是偶然的(如大脑皮层的褶皱)。
- • 自上而下的信念 (Top-down belief):当实验结果不理想时,是什么支撑你继续下去?是对某个方向「它必须是这样」的强烈信念。这种信念来自于上述多方面的美学和启发。它能帮助你区分是方向错了,还是代码里有 bug。
这种由美学和第一性原理驱动的「自上而下的信念」,是穿越研究无人区、做出真正突破性工作的关键。
总结
Ilya Sutskever 的这次访谈,为我们描绘了一幅与当前主流叙事不完全相同的 AI 未来图景。
在这个图景中,「算力为王」的时代正在落幕,对「泛化」等根本问题的基础研究将重新成为舞台的中心。未来的超级智能将不是一个被一次性训练出来的静态产品,而是一个拥有超强学习能力、在与世界互动中不断成长的「学习算法」。
要确保这个未来是安全的,我们需要让 AI 关心更广泛的「有情生命」,并最终可能需要通过人机融合来维持人类在宇宙中的主体地位。
这一切的起点,是回归研究的本质:用美学和第一性原理驱动的「品味」,去寻找那个简洁、优美且正确的答案。这或许正是 Ilya Sutskever 创立 SSI,并再次投身于未知探索的根本原因。
你觉得,世界正在等待的下一个「Transformer」时刻,会由 Ilya 和 SSI 带来吗?
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号